---
title: "Release CalCOFI Database"
calcofi:
target_name: release_database
workflow_type: release
dependency:
- auto
output: data/releases
# cross-dataset foreign keys (relationships spanning ingests) are authored in
# metadata/relationships_cross.csv; intra-dataset FKs live in each ingest's
# relationships.json. both are merged below into the release relationships.json.
# ERD color overrides for common/cross-cutting tables (neutral). dataset
# colors themselves come from each ingest's calcofi.erd.color.
erd_overrides:
dataset: "#e8e8e8"
measurement_type: "#e8e8e8"
cruise: "#e8e8e8"
sample: "#e8e8e8"
obs: "#e8e8e8"
obs_attribute: "#e8e8e8"
sample_measurement: "#e8e8e8"
obs_ctd_full: "#e8e8e8"
_spatial: "#cfe8ea"
_spatial_attr: "#cfe8ea"
execute:
echo: true
message: true
warning: true
editor_options:
chunk_output_type: console
format:
html:
code-fold: true
editor:
markdown:
wrap: 72
---
## Overview {.unnumbered}
**Goal**: Create a frozen (immutable) release of the CalCOFI integrated
database by assembling all ingest parquet outputs. This is the "caboose"
notebook that always runs last, after all ingest notebooks complete.
**Upstream notebooks** are auto-discovered from `calcofi:` YAML
frontmatter in each `.qmd`. All workflows with `workflow_type: ingest`
or `spatial` feed into this release notebook via `dependency: [auto]`
in `_targets.R`.
```{r}
#| label: gen_fig_workflow
#| results: asis
#| echo: false
#| message: false
#| warning: false
# echo must stay false: this chunk emits a ```{mermaid} cell, and echoing R
# source that contains literal ``` fences would corrupt the document structure.
librarian::shelf(targets, quiet = TRUE)
# auto-discover the pipeline graph straight from _targets.R, so newly added
# workflows show up without editing this diagram. callr_function = NULL keeps it
# in-process (safe when this notebook is rendered via tar_make); outdated = FALSE
# skips the up-to-date check (no node status needed here).
invisible(suppressMessages(capture.output(
net <- tar_network(targets_only = TRUE, outdated = FALSE, callr_function = NULL))))
nodes <- net$vertices$name
edges <- net$edges
# group each node by name so the diagram colors input / ingest / release / test
node_grp <- ifelse(nodes == "release_database", "rel",
ifelse(nodes == "test_release", "test",
ifelse(nodes == "corrections_csv", "input", "ingest")))
# emit Mermaid source; rendered to a zoomable PNG via the project-level
# `mermaid-format: png` + `lightbox: true` (see _quarto.yml). release_database
# (this notebook) is highlighted.
mmd <- c(
"flowchart LR",
vapply(nodes, function(n) sprintf(' %s["%s"]', n, n), ""),
apply(edges, 1, function(r) sprintf(" %s --> %s", r[["from"]], r[["to"]])),
" classDef input fill:#eeeeee,stroke:#999999,color:#333333;",
" classDef ingest fill:#e3f2fd,stroke:#1565c0,color:#0d3c61;",
" classDef rel fill:#ef6c00,stroke:#b35100,color:#ffffff,font-weight:bold;",
" classDef test fill:#e8f4e8,stroke:#2e7d32,color:#1b5e20;")
for (grp in c("input", "ingest", "rel", "test")) {
members <- nodes[node_grp == grp]
if (length(members))
mmd <- c(mmd, sprintf(" class %s %s;", paste(members, collapse = ","), grp))
}
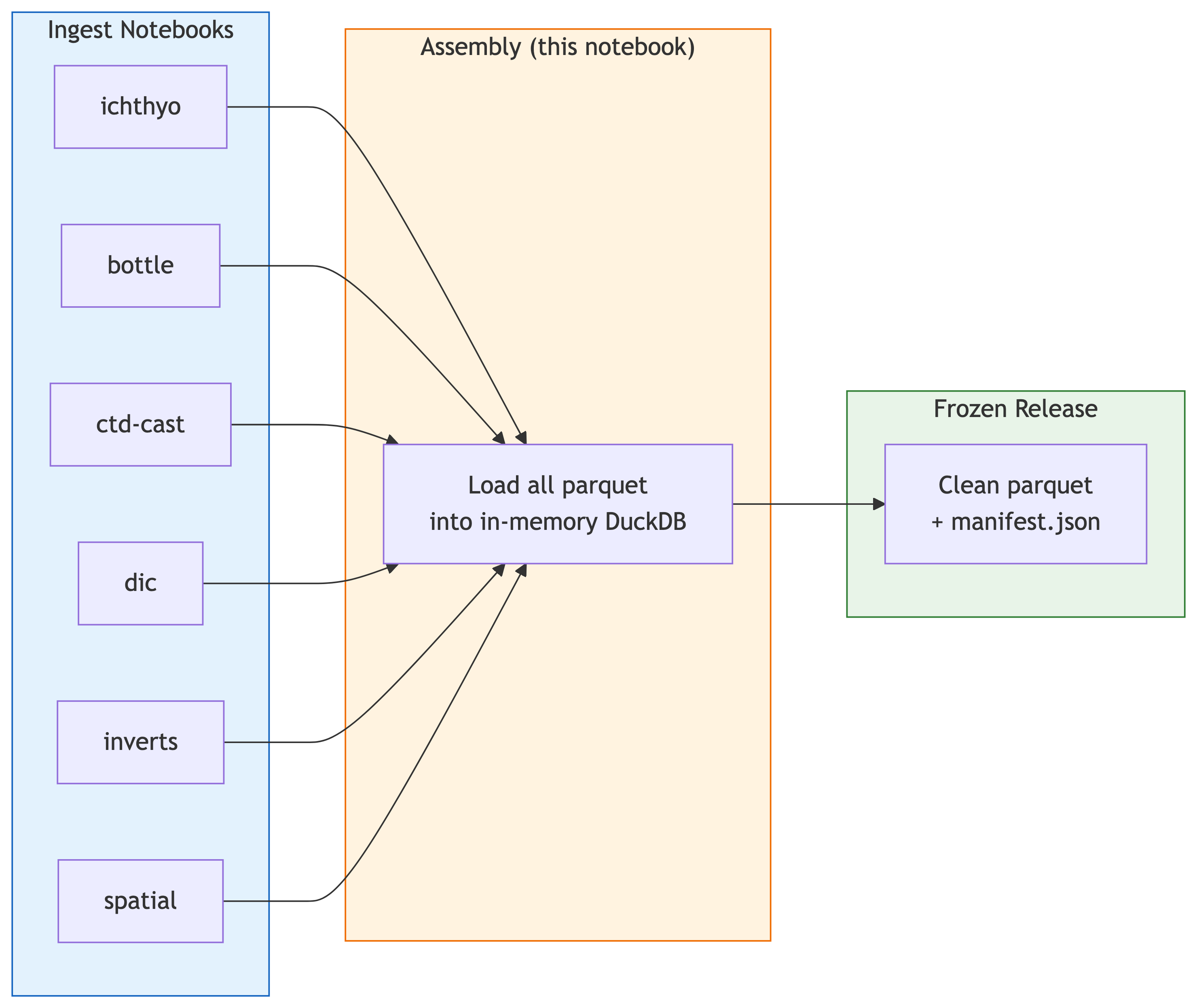
cap <- paste(
"Pipeline dependency graph, auto-discovered from `_targets.R`: every workflow",
"in this folder is a node and edges are dependencies. `release_database` (this",
"notebook, orange) is the caboose — it runs last, after all ingests, to assemble",
"the frozen release. Click to zoom.")
cat("```{mermaid}\n")
cat("%%| label: fig-workflow\n")
cat('%%| fig-cap: "', cap, '"\n', sep = "")
cat(mmd, sep = "\n")
cat("\n```\n")
```
## Setup
```{r}
#| label: setup
devtools::load_all(here::here("../calcofi4db"))
devtools::load_all(here::here("../calcofi4r"))
# cleanup_gcs_obsolete(dry_run = F)
librarian::shelf(
CalCOFI / calcofi4db,
CalCOFI / calcofi4r,
DBI,
dplyr,
DT,
fs,
glue,
here,
jsonlite,
purrr,
tibble,
quiet = T
)
options(DT.options = list(scrollX = TRUE))
# release version
release_version <- format(Sys.Date(), "v%Y.%m.%d")
message(glue("Release version: {release_version}"))
```
## Assemble from Ingest Outputs
Create VIEWs on local parquet files from each ingest (zero-copy).
For tables appearing in multiple ingests, use the canonical (first) source.
```{r}
#| label: assemble_working
con_wdl <- get_duckdb_con(":memory:")
load_duckdb_extension(con_wdl, "spatial")
# auto-discover table registry from all ingest manifests
registry <- build_release_table_registry(here())
# use only canonical, non-supplemental tables
reg_canon <- registry |>
filter(canonical, !supplemental)
message(glue(
"{nrow(reg_canon)} canonical tables from ",
"{length(unique(reg_canon$ingest))} ingests"))
# --- authoritative dataset metadata + ERD coloring from ingest YAML ----
# table -> provider_dataset(s) owned, from each ingest's calcofi.tables_owned
ingest_yaml <- read_ingest_yaml(here())
table_dataset <- list()
add_owner <- function(tbl, pd) {
if (is.null(tbl)) return(invisible())
table_dataset[[tbl]] <<- unique(c(table_dataset[[tbl]], pd))
}
for (key in names(ingest_yaml)) {
cc <- ingest_yaml[[key]]
for (e in cc$tables_owned %||% list()) add_owner(e$table, key)
for (ad in cc$additional_datasets %||% list()) {
pd2 <- paste0(ad$provider, "_", ad$dataset)
for (e in ad$tables_owned %||% list()) add_owner(e$table, pd2)
}
}
# one color per dataset (from calcofi.erd.color)
dataset_colors <- lapply(ingest_yaml, function(cc) cc$erd$color)
# release-level config: neutral ERD overrides for common tables
rel_cfg <- read_calcofi_meta(here("release_database.qmd"))
release_overrides <- rel_cfg$erd_overrides
# cross-dataset foreign keys (relationships spanning ingests) are authored in a
# reviewable CSV; intra-dataset FKs live in each ingest's relationships.json.
cross_fks_df <- readr::read_csv(
here("metadata/relationships_cross.csv"), show_col_types = FALSE)
cross_fks <- lapply(seq_len(nrow(cross_fks_df)), function(i)
as.list(cross_fks_df[i, c("table", "column", "ref_table", "ref_column")]))
# stroke-based color map consumed by every cc_erd() call below
color_map <- cc_erd_color_map(
table_dataset = table_dataset,
dataset_colors = dataset_colors,
overrides = release_overrides,
neutral = "#dcdcdc")
# create VIEWs on local parquet for each canonical table
# _new delta tables handled separately for merging
all_geom_tables <- c("grid", "site", "segment", "casts", "ctd_cast", "_spatial")
main_tables <- reg_canon |> filter(!grepl("_new$", table))
new_tables <- registry |> filter(grepl("_new$", table))
load_stats <- purrr::map_dfr(
split(main_tables, seq_len(nrow(main_tables))),
function(row) {
load_prior_tables(
con = con_wdl,
parquet_dir = row$parquet_dir,
tables = row$table,
geom_tables = all_geom_tables,
as_view = TRUE
)
})
# merge {table}_new additions into their base tables
# driven by calcofi.modifies in YAML frontmatter
if (nrow(new_tables) > 0) {
# group _new tables by their base table
base_names <- unique(sub("_new$", "", new_tables$table))
for (base_tbl in base_names) {
delta_rows <- new_tables |> filter(table == paste0(base_tbl, "_new"))
# replace VIEW with TABLE for this base table (so we can INSERT)
base_src <- main_tables |> filter(table == base_tbl)
if (nrow(base_src) > 0) {
dbExecute(con_wdl, glue("DROP VIEW IF EXISTS {base_tbl}"))
load_prior_tables(
con = con_wdl, parquet_dir = base_src$parquet_dir[1],
tables = base_tbl, geom_tables = all_geom_tables)
# get PK column for dedup
pk_col <- dbGetQuery(con_wdl, glue(
"SELECT column_name FROM information_schema.columns
WHERE table_name = '{base_tbl}'
ORDER BY ordinal_position LIMIT 1"))$column_name
for (j in seq_len(nrow(delta_rows))) {
dr <- delta_rows[j, ]
pq_path <- file.path(dr$parquet_dir, paste0(base_tbl, "_new.parquet"))
if (file.exists(pq_path)) {
dbExecute(con_wdl, glue(
"INSERT INTO {base_tbl}
SELECT * FROM read_parquet('{pq_path}')
WHERE {pk_col} NOT IN (SELECT {pk_col} FROM {base_tbl})"))
n_new <- dbGetQuery(con_wdl, glue(
"SELECT COUNT(*) AS n FROM read_parquet('{pq_path}')"))$n
message(glue("Merged {n_new} {base_tbl} addition(s) from {dr$ingest}"))
}
}
}
}
}
load_stats |>
datatable(caption = "Assembled tables (VIEWs on local parquet)")
```
## Dataset Reference & Observation Views
Non-destructive enablers (Part B of the station-portal epic): a `dataset`
reference table keyed by `dataset_key = provider_dataset`, and unified
`v_obs_env` / `v_obs_bio` (+ `v_obs`) VIEWs that project every dataset's
long-format observations into a common shape stamped with `dataset_key`. These
are the shared query surface behind the three spatial summarizers (hex /
cruise-track / station-grid) and prove the env/bio consolidation target
(Part C) non-destructively — no ingest re-run required.
```{r}
#| label: obs_views
# dataset reference: dataset_key = provider_dataset (authoritative from the CSV,
# replacing any per-ingest `dataset` VIEW assembled above)
dbExecute(con_wdl, "DROP VIEW IF EXISTS dataset")
dbExecute(con_wdl, glue(
"CREATE OR REPLACE TABLE dataset AS
SELECT provider || '_' || dataset AS dataset_key, provider, dataset, dataset_name,
description, citation_main, link_calcofi_org, link_data_source, license, pi_names
FROM read_csv_auto('{here('metadata/dataset.csv')}')"))
# only build view arms whose source tables are present in this release
tbls <- dbGetQuery(con_wdl, "SELECT table_name FROM information_schema.tables")$table_name
has <- function(...) all(c(...) %in% tbls)
# --- environment arms (point-depth measurement grain) ----------------------
env_arms <- list(
bottle = if (has("bottle_measurement","bottle","casts")) "
SELECT 'calcofi_bottle' AS dataset_key, c.grid_key, c.cruise_key,
c.latitude, c.longitude, CAST(c.datetime_start_utc AS TIMESTAMP) AS datetime,
b.depth_m AS depth_min, b.depth_m AS depth_max,
m.measurement_type, m.measurement_value, m.measurement_qual
FROM bottle_measurement m JOIN bottle b USING (bottle_id) JOIN casts c USING (cast_id)
WHERE c.grid_key IS NOT NULL",
ctd = if (has("ctd_measurement","ctd_cast")) "
SELECT 'calcofi_ctd-cast', cc.grid_key, cc.cruise_key,
cc.latitude, cc.longitude, CAST(cc.datetime_start_utc AS TIMESTAMP),
m.depth_m, m.depth_m, m.measurement_type, m.measurement_value, m.measurement_qual
FROM ctd_measurement m JOIN ctd_cast cc ON m.ctd_cast_uuid = cc.ctd_cast_uuid
WHERE cc.grid_key IS NOT NULL",
dic = if (has("dic_measurement","casts")) "
SELECT 'calcofi_dic', c.grid_key, c.cruise_key,
dm.latitude, dm.longitude, CAST(dm.datetime_start_utc AS TIMESTAMP),
dm.depth_m, dm.depth_m, dm.measurement_type, dm.measurement_value, dm.measurement_qual
FROM dic_measurement dm JOIN casts c USING (cast_id)
WHERE c.grid_key IS NOT NULL")
env_arms <- Filter(Negate(is.null), env_arms)
# --- biology arms (taxon x measurement, tow-integrated depth) ---------------
# taxon_key = raw species/taxon id (resolve to names via the taxon tables); NULL
# where the taxon is encoded in measurement_type (cufes eggs, phyllosoma stages).
bio_arms <- list(
ichthyo = if (has("ichthyo","net","tow","site")) "
SELECT 'swfsc_ichthyo' AS dataset_key, s.grid_key, s.cruise_key,
s.latitude, s.longitude, CAST(t.datetime_start_utc AS TIMESTAMP) AS datetime,
NULL::DOUBLE AS depth_min, NULL::DOUBLE AS depth_max,
i.measurement_type, i.measurement_value, NULL AS measurement_qual,
CAST(i.species_id AS VARCHAR) AS taxon_key, i.life_stage
FROM ichthyo i JOIN net n USING (net_uuid) JOIN tow t USING (tow_uuid) JOIN site s USING (site_uuid)
WHERE s.grid_key IS NOT NULL",
cufes = if (has("cufes_measurement","cufes_sample")) "
SELECT 'swfsc_cufes', c.grid_key, c.cruise_key, c.latitude, c.longitude,
CAST(c.datetime_start_utc AS TIMESTAMP), 0::DOUBLE, 0::DOUBLE,
m.measurement_type, m.measurement_value, m.measurement_qual, NULL, NULL
FROM cufes_measurement m JOIN cufes_sample c USING (sample_id) WHERE c.grid_key IS NOT NULL",
euphausiids = if (has("euphausiids_measurement","euphausiids_tow")) "
SELECT 'cce-lter_euphausiids', tw.grid_key, tw.cruise_key, tw.latitude, tw.longitude,
CAST(tw.datetime_start_utc AS TIMESTAMP), NULL::DOUBLE, NULL::DOUBLE,
m.measurement_type, m.measurement_value, m.measurement_qual, NULL, NULL
FROM euphausiids_measurement m JOIN euphausiids_tow tw USING (tow_id) WHERE tw.grid_key IS NOT NULL",
phyllosoma = if (has("phyllosoma_measurement","phyllosoma_tow")) "
SELECT 'calcofi_phyllosoma', tw.grid_key, tw.cruise_key, tw.latitude, tw.longitude,
CAST(tw.datetime_start_utc AS TIMESTAMP), 0::DOUBLE, tw.max_tow_depth_m,
m.measurement_type, m.measurement_value, m.measurement_qual, NULL, NULL
FROM phyllosoma_measurement m JOIN phyllosoma_tow tw USING (tow_id) WHERE tw.grid_key IS NOT NULL",
zoodb = if (has("zoodb_measurement","zoodb_sample")) "
SELECT 'cce-lter_zoodb', sp.grid_key, sp.cruise_key, sp.latitude, sp.longitude,
CAST(sp.datetime_start_utc AS TIMESTAMP), sp.min_depth_m, sp.max_depth_m,
m.measurement_type, m.measurement_value, NULL, CAST(m.taxon_id AS VARCHAR), NULL
FROM zoodb_measurement m JOIN zoodb_sample sp USING (sample_id) WHERE sp.grid_key IS NOT NULL",
zooscan = if (has("zooscan_measurement","zooscan_sample")) "
SELECT 'cce-lter_zooscan', sp.grid_key, sp.cruise_key, sp.latitude, sp.longitude,
CAST(sp.station_date AS TIMESTAMP), sp.min_depth_m, sp.max_depth_m,
m.measurement_type, m.measurement_value, NULL, CAST(m.taxon_id AS VARCHAR), NULL
FROM zooscan_measurement m JOIN zooscan_sample sp USING (sample_id) WHERE sp.grid_key IS NOT NULL",
bird_mammal = if (has("bird_mammal_observation","bird_mammal_transect")) "
SELECT 'calcofi_bird_mammal_census', tr.grid_key, tr.cruise_key, tr.latitude, tr.longitude,
CAST(tr.datetime_start_utc AS TIMESTAMP), 0::DOUBLE, 0::DOUBLE,
'count', o.count, NULL, CAST(o.species_code AS VARCHAR), o.behavior_code
FROM bird_mammal_observation o JOIN bird_mammal_transect tr USING (gis_key) WHERE tr.grid_key IS NOT NULL")
bio_arms <- Filter(Negate(is.null), bio_arms)
dbExecute(con_wdl, glue(
"CREATE OR REPLACE VIEW v_obs_env AS
SELECT 'env' AS realm, * FROM (\n{paste(env_arms, collapse='\nUNION ALL\n')}\n)"))
dbExecute(con_wdl, glue(
"CREATE OR REPLACE VIEW v_obs_bio AS
SELECT 'bio' AS realm, * FROM (\n{paste(bio_arms, collapse='\nUNION ALL\n')}\n)"))
# v_obs: common columns across both realms (drops taxon_key/life_stage)
dbExecute(con_wdl,
"CREATE OR REPLACE VIEW v_obs AS
SELECT realm, dataset_key, grid_key, cruise_key, latitude, longitude, datetime,
depth_min, depth_max, measurement_type, measurement_value, measurement_qual FROM v_obs_env
UNION ALL
SELECT realm, dataset_key, grid_key, cruise_key, latitude, longitude, datetime,
depth_min, depth_max, measurement_type, measurement_value, measurement_qual FROM v_obs_bio")
dbGetQuery(con_wdl,
"SELECT realm, dataset_key, count(*) n_obs, count(DISTINCT grid_key) n_stations
FROM v_obs GROUP BY 1,2 ORDER BY 1,2") |>
datatable(caption = "v_obs: unified observation views (dataset_key-stamped)")
```
## Consolidated Core Tables
Part C of the station-portal epic: promote the Phase-1 `v_obs_*` VIEWs to
materialized **core** tables that every consumer reads, replacing the ~40
per-dataset triples. Built with the `calcofi4db` model engine
(`build_sample_reference()` / `append_obs()` / `append_obs_attribute()` /
`append_sample_measurement()`), keyed by a namespaced `sample_key`
(`dataset_key:sample_type:id`) and stamped with a computed H3 `hex_id`. See
`design_env-bio-consolidation.md`.
```{r}
#| label: core_tables
# build obs_ctd_full (216M full-resolution CTD scans) is the heavy step; the
# default `obs` carries CTD via the thinned ctd_thin (~5.5M). Defaults ON for the
# full pipeline; set env BUILD_OBS_CTD_FULL=FALSE for a fast render (the
# supplemental full-scan table is opt-in).
build_obs_ctd_full <- as.logical(Sys.getenv("BUILD_OBS_CTD_FULL", "TRUE"))
# measurement_type: authoritative from the metadata CSV (adds abundance, count,
# body_length, and the event-level effort types), replacing any per-ingest VIEW
# so the FK parity check below sees the current vocabulary.
dbExecute(con_wdl, "DROP VIEW IF EXISTS measurement_type")
dbExecute(con_wdl, glue(
"CREATE OR REPLACE TABLE measurement_type AS
SELECT * FROM read_csv_auto('{here('metadata/measurement_type.csv')}')"))
# unified taxon references ------------------------------------------------------
# taxon (one authoritative row per taxon, keyed worms:/itis:), dataset_taxon
# (per-dataset vocabulary -> taxon_key crosswalk) and taxon_group (groupings),
# replacing the ~7 per-dataset taxon tables. Coarse/composite taxa (cufes eggs,
# phyllosoma stages, euphausiid family, phyto functional groups, seabird/mammal
# species) resolve to real WoRMS/ITIS ids via two reviewable registries.
mt_taxon <- readr::read_csv(here("metadata/measurement_taxon.csv"), show_col_types = FALSE)
tx_over <- readr::read_csv(here("metadata/taxon_override.csv"), show_col_types = FALSE)
n_taxon <- build_taxon_reference(con_wdl, measurement_taxon = mt_taxon, overrides = tx_over)
n_ds_tax <- build_dataset_taxon(con_wdl, measurement_taxon = mt_taxon, overrides = tx_over)
n_tx_grp <- build_taxon_group(con_wdl, measurement_taxon = mt_taxon, overrides = tx_over)
# _measurement_taxon: the composite-decomposition map the bio obs arms join to
# split "sardine_eggs"/"phyllosoma_stage_N" into (taxon_key, canonical type,
# life_stage). taxon_key derived here (composites are non-bird -> worms:, itis fallback).
dbExecute(con_wdl, glue(
"CREATE OR REPLACE TABLE _measurement_taxon AS
SELECT *, CASE WHEN worms_id IS NOT NULL THEN 'worms:' || CAST(worms_id AS BIGINT)
WHEN itis_id IS NOT NULL THEN 'itis:' || CAST(itis_id AS BIGINT) END AS taxon_key
FROM read_csv_auto('{here('metadata/measurement_taxon.csv')}')"))
message(glue("taxon: {n_taxon} / dataset_taxon: {n_ds_tax} / taxon_group: {n_tx_grp}"))
# 1. sample dimension (adjacency list) from the per-dataset event tables --------
n_sample <- build_sample_reference(con_wdl)
message(glue("sample: {n_sample} rows"))
# 2. obs — occurrence-headline long table --------------------------------------
# shared DIC natural key (columns present in dic_measurement so obs aligns with
# the `sample` dic arm); a DIC obs sharing a physical Niskin points at the bottle.
dic_key <- "CASE WHEN dm.bottle_id IS NOT NULL
AND dm.bottle_id IN (SELECT bottle_id FROM bottle)
THEN 'calcofi_bottle:bottle:' || CAST(dm.bottle_id AS VARCHAR)
ELSE 'calcofi_dic:bottle:' || md5(concat_ws('|', dm.expocode,
CAST(dm.datetime_start_utc AS VARCHAR), CAST(dm.latitude AS VARCHAR),
CAST(dm.longitude AS VARCHAR), CAST(dm.depth_m AS VARCHAR))) END"
env_obs_arms <- list(
bottle = if (has("bottle_measurement", "bottle", "casts")) "
SELECT 'env' realm, 'calcofi_bottle' dataset_key,
'calcofi_bottle:bottle:' || CAST(b.bottle_id AS VARCHAR) sample_key,
c.grid_key, c.cruise_key, c.latitude, c.longitude,
CAST(c.datetime_start_utc AS TIMESTAMP) datetime, b.depth_m depth_min_m, b.depth_m depth_max_m,
NULL::VARCHAR taxon_key, NULL::VARCHAR life_stage,
m.measurement_type, m.measurement_value, m.measurement_qual, m.measurement_prec
FROM bottle_measurement m JOIN bottle b USING (bottle_id) JOIN casts c USING (cast_id)
WHERE c.grid_key IS NOT NULL",
# CTD via thinned ctd_thin; map each thin scan's ctd_cast_uuid to its physical cast_key
ctd = if (has("ctd_thin", "ctd_cast")) "
SELECT 'env', 'calcofi_ctd-cast',
'calcofi_ctd-cast:cast:' || CAST(cc.cast_key AS VARCHAR),
cc.grid_key, cc.cruise_key, cc.latitude, cc.longitude,
CAST(cc.datetime_start_utc AS TIMESTAMP), t.depth_m, t.depth_m,
NULL::VARCHAR, NULL::VARCHAR, t.measurement_type, t.measurement_value,
t.measurement_qual, NULL::DOUBLE
FROM ctd_thin t JOIN ctd_cast cc ON t.ctd_cast_uuid = cc.ctd_cast_uuid
WHERE cc.grid_key IS NOT NULL",
dic = if (has("dic_measurement", "bottle", "casts")) glue("
SELECT 'env', 'calcofi_dic', {dic_key},
c.grid_key, c.cruise_key, dm.latitude, dm.longitude,
CAST(dm.datetime_start_utc AS TIMESTAMP), dm.depth_m, dm.depth_m,
NULL::VARCHAR, NULL::VARCHAR, dm.measurement_type, dm.measurement_value,
dm.measurement_qual, NULL::DOUBLE
FROM dic_measurement dm JOIN casts c USING (cast_id)
WHERE c.grid_key IS NOT NULL"))
# bio arms resolve the GLOBAL taxon_key: taxon-table datasets join `dataset_taxon`
# on (dataset_key, ds_taxa_code); composite datasets (cufes/euphausiids/phyllosoma)
# join `_measurement_taxon` (target='obs') to decompose the taxon out of the type
# name into taxon_key + canonical measurement_type + life_stage.
bio_obs_arms <- list(
# ichthyo base rows (measurement_type IS NULL) -> abundance headline; size/stage
# go to obs_attribute below.
ichthyo = if (has("ichthyo", "net", "tow", "site")) "
SELECT 'bio', 'swfsc_ichthyo', 'swfsc_ichthyo:net:' || CAST(i.net_uuid AS VARCHAR),
s.grid_key, s.cruise_key, s.latitude, s.longitude,
CAST(t.datetime_start_utc AS TIMESTAMP), NULL::DOUBLE, NULL::DOUBLE,
dt.taxon_key, i.life_stage,
'abundance', CAST(i.tally AS DOUBLE), NULL::VARCHAR, NULL::DOUBLE
FROM ichthyo i JOIN net n USING (net_uuid) JOIN tow t USING (tow_uuid) JOIN site s USING (site_uuid)
LEFT JOIN dataset_taxon dt ON dt.dataset_key = 'swfsc_ichthyo'
AND dt.ds_taxa_code = CAST(i.species_id AS VARCHAR)
WHERE i.measurement_type IS NULL AND s.grid_key IS NOT NULL",
# cufes: taxon baked in the type name (sardine_eggs, ...) -> abundance + life_stage='egg'
cufes = if (has("cufes_measurement", "cufes_sample")) "
SELECT 'bio', 'swfsc_cufes', 'swfsc_cufes:underway:' || CAST(c.sample_id AS VARCHAR),
c.grid_key, c.cruise_key, c.latitude, c.longitude,
CAST(c.datetime_start_utc AS TIMESTAMP), 0::DOUBLE, 0::DOUBLE,
mx.taxon_key, mx.life_stage, mx.measurement_type, m.measurement_value, m.measurement_qual, NULL::DOUBLE
FROM cufes_measurement m JOIN cufes_sample c USING (sample_id)
JOIN _measurement_taxon mx ON mx.dataset_key = 'swfsc_cufes'
AND mx.raw_measurement_type = m.measurement_type AND mx.target = 'obs'
WHERE c.grid_key IS NOT NULL",
euphausiids = if (has("euphausiids_measurement", "euphausiids_tow")) "
SELECT 'bio', 'cce-lter_euphausiids', 'cce-lter_euphausiids:tow:' || CAST(tw.tow_id AS VARCHAR),
tw.grid_key, tw.cruise_key, tw.latitude, tw.longitude,
CAST(tw.datetime_start_utc AS TIMESTAMP), NULL::DOUBLE, NULL::DOUBLE,
mx.taxon_key, mx.life_stage, mx.measurement_type, m.measurement_value, m.measurement_qual, NULL::DOUBLE
FROM euphausiids_measurement m JOIN euphausiids_tow tw USING (tow_id)
JOIN _measurement_taxon mx ON mx.dataset_key = 'cce-lter_euphausiids'
AND mx.raw_measurement_type = m.measurement_type AND mx.target = 'obs'
WHERE tw.grid_key IS NOT NULL",
# phyllosoma: only total_phyllosoma is the obs headline (target='obs'); the
# phyllosoma_stage_N (target='attribute') go to obs_attribute below.
phyllosoma = if (has("phyllosoma_measurement", "phyllosoma_tow")) "
SELECT 'bio', 'calcofi_phyllosoma', 'calcofi_phyllosoma:tow:' || CAST(tw.tow_id AS VARCHAR),
tw.grid_key, tw.cruise_key, tw.latitude, tw.longitude,
CAST(tw.datetime_start_utc AS TIMESTAMP), 0::DOUBLE, tw.max_tow_depth_m,
mx.taxon_key, mx.life_stage, mx.measurement_type, m.measurement_value, m.measurement_qual, NULL::DOUBLE
FROM phyllosoma_measurement m JOIN phyllosoma_tow tw USING (tow_id)
JOIN _measurement_taxon mx ON mx.dataset_key = 'calcofi_phyllosoma'
AND mx.raw_measurement_type = m.measurement_type AND mx.target = 'obs'
WHERE tw.grid_key IS NOT NULL",
zoodb = if (has("zoodb_measurement", "zoodb_sample")) "
SELECT 'bio', 'cce-lter_zoodb', 'cce-lter_zoodb:tow:' || CAST(sp.sample_id AS VARCHAR),
sp.grid_key, sp.cruise_key, sp.latitude, sp.longitude,
CAST(sp.datetime_start_utc AS TIMESTAMP), sp.min_depth_m, sp.max_depth_m,
dt.taxon_key, NULL::VARCHAR, m.measurement_type, m.measurement_value, NULL::VARCHAR, NULL::DOUBLE
FROM zoodb_measurement m JOIN zoodb_sample sp USING (sample_id)
LEFT JOIN dataset_taxon dt ON dt.dataset_key = 'cce-lter_zoodb'
AND dt.ds_taxa_code = CAST(m.taxon_id AS VARCHAR)
WHERE sp.grid_key IS NOT NULL",
zooscan = if (has("zooscan_measurement", "zooscan_sample")) "
SELECT 'bio', 'cce-lter_zooscan', 'cce-lter_zooscan:tow:' || CAST(sp.sample_id AS VARCHAR),
sp.grid_key, sp.cruise_key, sp.latitude, sp.longitude,
CAST(sp.station_date AS TIMESTAMP), sp.min_depth_m, sp.max_depth_m,
dt.taxon_key, NULL::VARCHAR, m.measurement_type, m.measurement_value, NULL::VARCHAR, NULL::DOUBLE
FROM zooscan_measurement m JOIN zooscan_sample sp USING (sample_id)
LEFT JOIN dataset_taxon dt ON dt.dataset_key = 'cce-lter_zooscan'
AND dt.ds_taxa_code = CAST(m.taxon_id AS VARCHAR)
WHERE sp.grid_key IS NOT NULL",
# phytoplankton: region-pooled (grid_key NULL, no datetime); taxon via dataset_taxon
phyto = if (has("phyto_measurement", "phyto_sample")) "
SELECT 'bio', 'calcofi_phytoplankton', 'calcofi_phytoplankton:region_pool:' || CAST(ps.phyto_sample_id AS VARCHAR),
NULL::VARCHAR, ps.cruise_key, ps.latitude, ps.longitude,
NULL::TIMESTAMP, 0::DOUBLE, 0::DOUBLE,
dt.taxon_key, NULL::VARCHAR, pm.measurement_type, pm.measurement_value, NULL::VARCHAR, NULL::DOUBLE
FROM phyto_measurement pm JOIN phyto_sample ps USING (phyto_sample_id)
LEFT JOIN dataset_taxon dt ON dt.dataset_key = 'calcofi_phytoplankton'
AND dt.ds_taxa_code = CAST(pm.species_code AS VARCHAR)",
# bird_mammal headline: one row per (transect, species), count SUMmed across
# behaviors; the behavior breakdown goes to obs_attribute below.
bird_mammal = if (has("bird_mammal_observation", "bird_mammal_transect")) "
SELECT 'bio', 'calcofi_bird_mammal_census', 'calcofi_bird_mammal_census:transect:' || CAST(tr.gis_key AS VARCHAR),
tr.grid_key, tr.cruise_key, tr.latitude, tr.longitude,
CAST(tr.datetime_start_utc AS TIMESTAMP), 0::DOUBLE, 0::DOUBLE,
dt.taxon_key, NULL::VARCHAR, 'count', CAST(SUM(o.count) AS DOUBLE), NULL::VARCHAR, NULL::DOUBLE
FROM bird_mammal_observation o JOIN bird_mammal_transect tr USING (gis_key)
LEFT JOIN dataset_taxon dt ON dt.dataset_key = 'calcofi_bird_mammal_census'
AND dt.ds_taxa_code = CAST(o.species_code AS VARCHAR)
WHERE tr.grid_key IS NOT NULL
GROUP BY tr.gis_key, tr.grid_key, tr.cruise_key, tr.latitude, tr.longitude,
tr.datetime_start_utc, dt.taxon_key")
obs_arms <- Filter(Negate(is.null), c(env_obs_arms, bio_obs_arms))
n_obs <- append_obs(con_wdl, paste(obs_arms, collapse = "\nUNION ALL\n"))
message(glue("obs: {n_obs} rows"))
# 3. obs_attribute — sub-occurrence attribution (length/stage frequency + behavior)
attr_arms <- list(
# ichthyo size->body_length + stage frequency; taxon_key via dataset_taxon
ichthyo = if (has("ichthyo", "lookup")) "
SELECT 'swfsc_ichthyo' dataset_key, 'swfsc_ichthyo:net:' || CAST(i.net_uuid AS VARCHAR) sample_key,
dt.taxon_key, i.life_stage,
CASE i.measurement_type WHEN 'size' THEN 'body_length' ELSE i.measurement_type END measurement_type,
i.measurement_value bin_value,
CASE WHEN i.measurement_type = 'stage' THEN lk.description ELSE NULL END bin_label,
i.tally count, NULL::VARCHAR measurement_qual
FROM ichthyo i
LEFT JOIN dataset_taxon dt ON dt.dataset_key = 'swfsc_ichthyo' AND dt.ds_taxa_code = CAST(i.species_id AS VARCHAR)
LEFT JOIN lookup lk ON lk.lookup_type = i.life_stage || '_stage'
AND lk.lookup_num = CAST(i.measurement_value AS INTEGER)
WHERE i.measurement_type IN ('stage','size')",
# phyllosoma stage-frequency: phyllosoma_stage_N -> ('stage', bin_value=N, count=value)
phyllosoma = if (has("phyllosoma_measurement", "phyllosoma_tow")) "
SELECT 'calcofi_phyllosoma' dataset_key, 'calcofi_phyllosoma:tow:' || CAST(tw.tow_id AS VARCHAR) sample_key,
mx.taxon_key, mx.life_stage, mx.measurement_type, mx.bin_value,
NULL::VARCHAR bin_label, CAST(m.measurement_value AS INTEGER) count, NULL::VARCHAR measurement_qual
FROM phyllosoma_measurement m JOIN phyllosoma_tow tw USING (tow_id)
JOIN _measurement_taxon mx ON mx.dataset_key = 'calcofi_phyllosoma'
AND mx.raw_measurement_type = m.measurement_type AND mx.target = 'attribute'
WHERE tw.grid_key IS NOT NULL AND m.measurement_value > 0",
# bird_mammal behavior breakdown -> ('behavior', label from bird_mammal_behavior)
behavior = if (has("bird_mammal_observation", "bird_mammal_transect", "bird_mammal_behavior")) "
SELECT 'calcofi_bird_mammal_census' dataset_key, 'calcofi_bird_mammal_census:transect:' || CAST(tr.gis_key AS VARCHAR) sample_key,
dt.taxon_key, NULL::VARCHAR life_stage, 'behavior' measurement_type, NULL::DOUBLE bin_value,
bb.description bin_label, CAST(o.count AS INTEGER) count, NULL::VARCHAR measurement_qual
FROM bird_mammal_observation o JOIN bird_mammal_transect tr USING (gis_key)
LEFT JOIN dataset_taxon dt ON dt.dataset_key = 'calcofi_bird_mammal_census' AND dt.ds_taxa_code = CAST(o.species_code AS VARCHAR)
LEFT JOIN bird_mammal_behavior bb ON bb.behavior_code = o.behavior_code
WHERE tr.grid_key IS NOT NULL")
attr_arms <- Filter(Negate(is.null), attr_arms)
if (length(attr_arms)) {
n_attr <- append_obs_attribute(con_wdl, paste(attr_arms, collapse = "\nUNION ALL\n"))
message(glue("obs_attribute: {n_attr} rows"))
}
# 4. sample_measurement — event-level effort -----------------------------------
sm_arms <- list(
# ichthyo net effort (canonical type names)
net = if (has("net")) "
SELECT 'swfsc_ichthyo:net:' || CAST(net_uuid AS VARCHAR) sample_key, 'swfsc_ichthyo' dataset_key,
mt measurement_type, mv measurement_value, NULL::VARCHAR measurement_qual
FROM (
SELECT net_uuid, 'volume_sampled' mt, volume_sampled mv FROM net UNION ALL
SELECT net_uuid, 'std_haul_factor', standard_haul_factor FROM net UNION ALL
SELECT net_uuid, 'prop_sorted', prop_sorted FROM net UNION ALL
SELECT net_uuid, 'small_plankton_biomass', smallplankton FROM net UNION ALL
SELECT net_uuid, 'total_plankton_biomass', totalplankton FROM net)
WHERE mv IS NOT NULL",
# bottle cast conditions (already event-level; condition_* -> measurement_*).
# cast_condition.cast_id is DOUBLE -> cast to BIGINT so the namespaced key
# matches casts.cast_id (INTEGER): 'calcofi_bottle:cast:5' not '...:5.0'.
cast_condition = if (has("cast_condition")) "
SELECT 'calcofi_bottle:cast:' || CAST(CAST(cast_id AS BIGINT) AS VARCHAR), 'calcofi_bottle',
condition_type, condition_value, NULL::VARCHAR
FROM cast_condition")
sm_arms <- Filter(Negate(is.null), sm_arms)
n_sm <- append_sample_measurement(con_wdl, paste(sm_arms, collapse = "\nUNION ALL\n"))
message(glue("sample_measurement: {n_sm} rows"))
# 5. obs_ctd_full — supplemental full-resolution CTD scans ----------------------
if (build_obs_ctd_full && has("ctd_cast")) {
ctd_pd <- registry |> filter(table == "ctd_thin") |> slice(1) |> pull(parquet_dir)
ctd_meas_glob <- file.path(ctd_pd, "ctd_measurement", "**", "*.parquet")
n_full <- append_obs(con_wdl, obs_tbl = "obs_ctd_full", select_sql = glue("
SELECT 'env' realm, 'calcofi_ctd-cast' dataset_key,
'calcofi_ctd-cast:cast:' || CAST(cc.cast_key AS VARCHAR) sample_key,
cc.grid_key, cc.cruise_key, cc.latitude, cc.longitude,
CAST(cc.datetime_start_utc AS TIMESTAMP) datetime, m.depth_m depth_min_m, m.depth_m depth_max_m,
NULL::VARCHAR taxon_key, NULL::VARCHAR life_stage,
m.measurement_type, m.measurement_value, m.measurement_qual, NULL::DOUBLE measurement_prec
FROM read_parquet('{ctd_meas_glob}', hive_partitioning = true) m
JOIN ctd_cast cc ON m.ctd_cast_uuid = cc.ctd_cast_uuid
WHERE cc.grid_key IS NOT NULL"))
message(glue("obs_ctd_full: {n_full} rows"))
}
dbGetQuery(con_wdl,
"SELECT dataset_key, count(*) n_obs, count(DISTINCT sample_key) n_samples,
count(DISTINCT hex_id) n_hex
FROM obs GROUP BY 1 ORDER BY 1") |>
datatable(caption = "obs: consolidated observations by dataset")
```
### Core Table Parity Checks
Hard assertions that the materialized core reproduces the per-dataset tables
(see `design_env-bio-consolidation.md` Verification). A break fails the render.
```{r}
#| label: core_parity
q <- function(sql) dbGetQuery(con_wdl, sql)$n
# (A) sample-count parity per level ------------------------------------------
sample_parity <- c(
"sample net" = q("SELECT COUNT(*) n FROM sample WHERE sample_type='net'") ==
q("SELECT COUNT(DISTINCT net_uuid) n FROM net"),
"sample tow" = q("SELECT COUNT(*) n FROM sample WHERE sample_type='tow' AND dataset_key='swfsc_ichthyo'") ==
q("SELECT COUNT(DISTINCT tow_uuid) n FROM tow"),
"sample site" = q("SELECT COUNT(*) n FROM sample WHERE sample_type='site'") ==
q("SELECT COUNT(DISTINCT site_uuid) n FROM site"),
"sample cast" = q("SELECT COUNT(*) n FROM sample WHERE dataset_key='calcofi_bottle' AND sample_type='cast'") ==
q("SELECT COUNT(DISTINCT cast_id) n FROM casts"),
"sample bottle" = q("SELECT COUNT(*) n FROM sample WHERE dataset_key='calcofi_bottle' AND sample_type='bottle'") ==
q("SELECT COUNT(DISTINCT bottle_id) n FROM bottle"),
"sample ctd" = q("SELECT COUNT(*) n FROM sample WHERE dataset_key='calcofi_ctd-cast'") ==
q("SELECT COUNT(DISTINCT cast_key) n FROM ctd_cast"))
stopifnot("sample-count parity" = all(sample_parity))
# (B) env obs row-count parity — env arms are 1:1 with source (CTD via ctd_thin).
# Bio arms intentionally aggregate (bird_mammal per transect x species) and
# decompose (phyllosoma stages -> obs_attribute; phyto added), so bio is reported,
# not asserted against the raw measurement counts.
env_expected <-
q("SELECT COUNT(*) n FROM bottle_measurement m JOIN bottle b USING(bottle_id) JOIN casts c USING(cast_id) WHERE c.grid_key IS NOT NULL") +
q("SELECT COUNT(*) n FROM ctd_thin t JOIN ctd_cast cc ON t.ctd_cast_uuid=cc.ctd_cast_uuid WHERE cc.grid_key IS NOT NULL") +
q("SELECT COUNT(*) n FROM dic_measurement dm JOIN casts c USING(cast_id) WHERE c.grid_key IS NOT NULL")
stopifnot("env obs row-count parity" = q("SELECT COUNT(*) n FROM obs WHERE realm='env'") == env_expected)
message(glue("env obs parity OK: {env_expected} rows"))
dbGetQuery(con_wdl, "SELECT dataset_key, count(*) n_obs, count(taxon_key) n_with_taxon
FROM obs WHERE realm='bio' GROUP BY 1 ORDER BY 1") |> print()
if (build_obs_ctd_full && exists("n_full"))
stopifnot("obs_ctd_full parity" =
q("SELECT COUNT(*) n FROM obs_ctd_full") ==
q(glue("SELECT COUNT(*) n FROM read_parquet('{ctd_meas_glob}', hive_partitioning=true) m
JOIN ctd_cast cc ON m.ctd_cast_uuid=cc.ctd_cast_uuid WHERE cc.grid_key IS NOT NULL")))
# (C) FK validity — every core row resolves against its reference, INCLUDING the
# unified taxon (obs/obs_attribute/dataset_taxon all key into taxon.taxon_key) ---
fk_bad <- c(
"obs.dataset_key" = q("SELECT COUNT(*) n FROM obs WHERE dataset_key NOT IN (SELECT dataset_key FROM dataset)"),
"obs.sample_key" = q("SELECT COUNT(*) n FROM obs WHERE sample_key NOT IN (SELECT sample_key FROM sample)"),
"obs.grid_key" = q("SELECT COUNT(*) n FROM obs WHERE grid_key IS NOT NULL AND grid_key NOT IN (SELECT grid_key FROM grid)"),
"obs.measurement_type" = q("SELECT COUNT(*) n FROM obs WHERE measurement_type NOT IN (SELECT measurement_type FROM measurement_type)"),
"obs.taxon_key" = q("SELECT COUNT(*) n FROM obs WHERE taxon_key IS NOT NULL AND taxon_key NOT IN (SELECT taxon_key FROM taxon)"),
"obs_attribute.sample_key" = q("SELECT COUNT(*) n FROM obs_attribute WHERE sample_key NOT IN (SELECT sample_key FROM sample)"),
"obs_attribute.taxon_key" = q("SELECT COUNT(*) n FROM obs_attribute WHERE taxon_key IS NOT NULL AND taxon_key NOT IN (SELECT taxon_key FROM taxon)"),
"obs_attribute.measurement_type" = q("SELECT COUNT(*) n FROM obs_attribute WHERE measurement_type NOT IN (SELECT measurement_type FROM measurement_type)"),
"dataset_taxon.taxon_key" = q("SELECT COUNT(*) n FROM dataset_taxon WHERE taxon_key NOT IN (SELECT taxon_key FROM taxon)"),
"sample_measurement.sample_key" = q("SELECT COUNT(*) n FROM sample_measurement WHERE sample_key NOT IN (SELECT sample_key FROM sample)"))
if (any(fk_bad > 0)) print(fk_bad[fk_bad > 0])
stopifnot("core FK validity" = all(fk_bad == 0))
# (D) obs_attribute stage sum vs abundance headline — reported (source may differ)
attr_check <- dbGetQuery(con_wdl, "
WITH f AS (SELECT sample_key, taxon_key, life_stage, SUM(count) s FROM obs_attribute
WHERE measurement_type='stage' GROUP BY 1,2,3),
o AS (SELECT sample_key, taxon_key, life_stage, SUM(measurement_value) a FROM obs
WHERE measurement_type='abundance' GROUP BY 1,2,3)
SELECT count(*) n_occ, count(*) FILTER (WHERE f.s > o.a) n_stage_gt_headline
FROM f JOIN o USING (sample_key, taxon_key, life_stage)")
message(glue("obs_attribute stage vs abundance: {attr_check$n_stage_gt_headline}/{attr_check$n_occ} occurrences exceed headline (source quirk)"))
message("Core parity checks passed.")
```
## Scan Manifests for Mismatches
```{r}
#| label: scan_mismatches
# scan all ingest manifests for unresolved mismatches
all_manifests <- list.files(
"data/parquet", "manifest.json",
recursive = TRUE, full.names = TRUE)
all_mismatches <- purrr::compact(lapply(all_manifests, function(mf) {
m <- jsonlite::read_json(mf)
if (is.null(m$mismatches)) return(NULL)
dataset <- basename(dirname(mf))
purrr::imap_dfr(m$mismatches, function(items, category) {
if (length(items) == 0) return(NULL)
purrr::map_dfr(items, function(x) {
# replace NULL values with NA so as_tibble works
x[vapply(x, is.null, logical(1))] <- NA
as_tibble(x)
}) |>
mutate(dataset = dataset, category = category, .before = 1)
})
}))
if (length(all_mismatches) > 0) {
d_mismatches <- bind_rows(all_mismatches)
message(glue("{nrow(d_mismatches)} unresolved mismatch(es) across manifests"))
d_mismatches |>
datatable(caption = "Unresolved mismatches (from manifest.json)")
} else {
message("No unresolved mismatches found across manifests")
}
```
## Validate
Cross-dataset validation to ensure data integrity before freezing.
```{r}
#| label: validate
# grid_key integrity: casts.grid_key should all be in grid.grid_key
tbls <- DBI::dbListTables(con_wdl)
if (all(c("casts", "grid") %in% tbls)) {
# use information_schema to check columns (avoids GEOMETRY type issues)
casts_cols_wdl <- dbGetQuery(
con_wdl,
"SELECT column_name FROM information_schema.columns
WHERE table_name = 'casts'"
)$column_name
grid_cols_wdl <- dbGetQuery(
con_wdl,
"SELECT column_name FROM information_schema.columns
WHERE table_name = 'grid'"
)$column_name
if ("grid_key" %in% casts_cols_wdl && "grid_key" %in% grid_cols_wdl) {
grid_orphans <- dbGetQuery(
con_wdl,
"SELECT COUNT(*) AS n FROM casts c
WHERE c.grid_key IS NOT NULL
AND c.grid_key NOT IN (SELECT grid_key FROM grid)"
)$n
message(glue("Grid key orphans in casts: {grid_orphans}"))
# Grid key orphans in casts: 0
}
}
# ship PK uniqueness
if ("ship" %in% tbls) {
ship_dups <- dbGetQuery(
con_wdl,
"SELECT ship_key, COUNT(*) AS n FROM ship
GROUP BY ship_key HAVING COUNT(*) > 1"
)
if (nrow(ship_dups) > 0) {
warning(glue("Duplicate ship_key values: {nrow(ship_dups)}"))
} else {
message("ship_key: all unique")
}
}
# ship_key: all unique
# cruise PK uniqueness
if ("cruise" %in% tbls) {
cruise_dups <- dbGetQuery(
con_wdl,
"SELECT cruise_key, COUNT(*) AS n FROM cruise
GROUP BY cruise_key HAVING COUNT(*) > 1"
)
if (nrow(cruise_dups) > 0) {
warning(glue("Duplicate cruise_key values: {nrow(cruise_dups)}"))
} else {
message("cruise_key: all unique")
}
}
# cruise_key: all unique
# cruise bridge coverage
if ("casts" %in% tbls) {
bridge_stats <- dbGetQuery(
con_wdl,
"SELECT
COUNT(*) AS total_casts,
SUM(CASE WHEN ship_key IS NOT NULL THEN 1 ELSE 0 END) AS with_ship_key,
SUM(CASE WHEN cruise_key IS NOT NULL THEN 1 ELSE 0 END) AS with_cruise_key
FROM casts"
)
bridge_stats |> datatable(caption = "Cruise bridge coverage")
}
# cruise_key format validation (YYYY-MM-NODC)
if ("cruise" %in% tbls) {
bad_ck <- dbGetQuery(
con_wdl,
"SELECT cruise_key FROM cruise
WHERE cruise_key IS NOT NULL
AND NOT regexp_matches(cruise_key, '^\\d{4}-\\d{2}-.+$')"
)
if (nrow(bad_ck) > 0) {
warning(glue("cruise_key format violations: {nrow(bad_ck)} rows"))
} else {
message("cruise_key: all match YYYY-MM-NODC format")
}
}
# Warning message: cruise_key format violations: 1 rows
# cruise_key: 2019-07-
# site_key format validation (NNN.N NNN.N)
for (tbl_name in intersect(c("site", "casts", "ctd_cast"), tbls)) {
tbl_cols <- dbGetQuery(
con_wdl,
glue(
"SELECT column_name FROM information_schema.columns
WHERE table_name = '{tbl_name}'"
)
)$column_name
if ("site_key" %in% tbl_cols) {
bad_sk <- dbGetQuery(
con_wdl,
glue(
"SELECT COUNT(*) AS n FROM {tbl_name}
WHERE site_key IS NOT NULL
AND NOT regexp_matches(site_key, '^\\d{{3}}\\.\\d \\d{{3}}\\.\\d$')"
)
)$n
if (bad_sk > 0) {
warning(glue("site_key format violations in {tbl_name}: {bad_sk} rows"))
} else {
message(glue("site_key in {tbl_name}: all match NNN.N NNN.N format"))
}
}
}
# site_key in casts: all match NNN.N NNN.N format
# Warning message: site_key format violations in site: 982 rows
# enrich the `cruise` reference in place with per-cruise x dataset event counts
# from the consolidated obs/sample (this is the former `cruise_summary`, folded
# into `cruise` so there is a single cruise table). count(DISTINCT root_sample_key)
# = distinct sampling-event roots (station occupations for net tows; casts for
# bottle/CTD/DIC). LEFT JOINs keep every reference cruise (no cruise dropped, so
# cruise_key FKs stay valid) and all its columns (cr.*). Add a FILTER column to
# extend to new datasets.
if (all(c("cruise", "ship") %in% tbls)) {
dbExecute(con_wdl, "CREATE OR REPLACE TEMP TABLE cruise_ref AS SELECT * FROM cruise")
dbExecute(con_wdl, "DROP VIEW IF EXISTS cruise")
dbExecute(con_wdl, "DROP TABLE IF EXISTS cruise")
dbExecute(
con_wdl,
"CREATE TABLE cruise AS
WITH ev AS (
SELECT o.cruise_key, o.dataset_key, COUNT(DISTINCT s.root_sample_key) AS n_events
FROM obs o JOIN sample s ON o.sample_key = s.sample_key
WHERE o.cruise_key IS NOT NULL
GROUP BY 1, 2),
piv AS (
SELECT cruise_key,
COALESCE(MAX(n_events) FILTER (WHERE dataset_key = 'swfsc_ichthyo'), 0) AS ichthyo,
COALESCE(MAX(n_events) FILTER (WHERE dataset_key = 'calcofi_bottle'), 0) AS bottle,
COALESCE(MAX(n_events) FILTER (WHERE dataset_key = 'calcofi_ctd-cast'), 0) AS ctd_cast,
COALESCE(MAX(n_events) FILTER (WHERE dataset_key = 'calcofi_dic'), 0) AS dic
FROM ev GROUP BY 1)
SELECT cr.*,
EXTRACT(YEAR FROM cr.date_ym)::INTEGER AS year,
EXTRACT(MONTH FROM cr.date_ym)::INTEGER AS month,
sh.ship_name, sh.ship_nodc,
COALESCE(piv.ichthyo, 0) AS ichthyo,
COALESCE(piv.bottle, 0) AS bottle,
COALESCE(piv.ctd_cast, 0) AS ctd_cast,
COALESCE(piv.dic, 0) AS dic
FROM cruise_ref cr
LEFT JOIN ship sh ON cr.ship_key = sh.ship_key
LEFT JOIN piv USING (cruise_key)
ORDER BY year DESC, month DESC")
n_cs <- dbGetQuery(con_wdl, "SELECT COUNT(*) AS n FROM cruise")$n
message(glue("Enriched cruise table: {n_cs} rows"))
}
tbl(con_wdl, "cruise") |>
collect() |>
datatable(caption = "cruise (enriched with per-dataset event counts)")
# run standard release validation (wrapped in tryCatch for GEOMETRY compat)
tryCatch(
{
validation <- validate_for_release(con_wdl)
if (validation$passed) {
message("Release validation passed!")
} else {
cat("Validation FAILED:\n")
cat(paste("-", validation$errors, collapse = "\n"))
}
},
error = function(e) {
message(glue("validate_for_release skipped: {e$message}"))
}
)
```
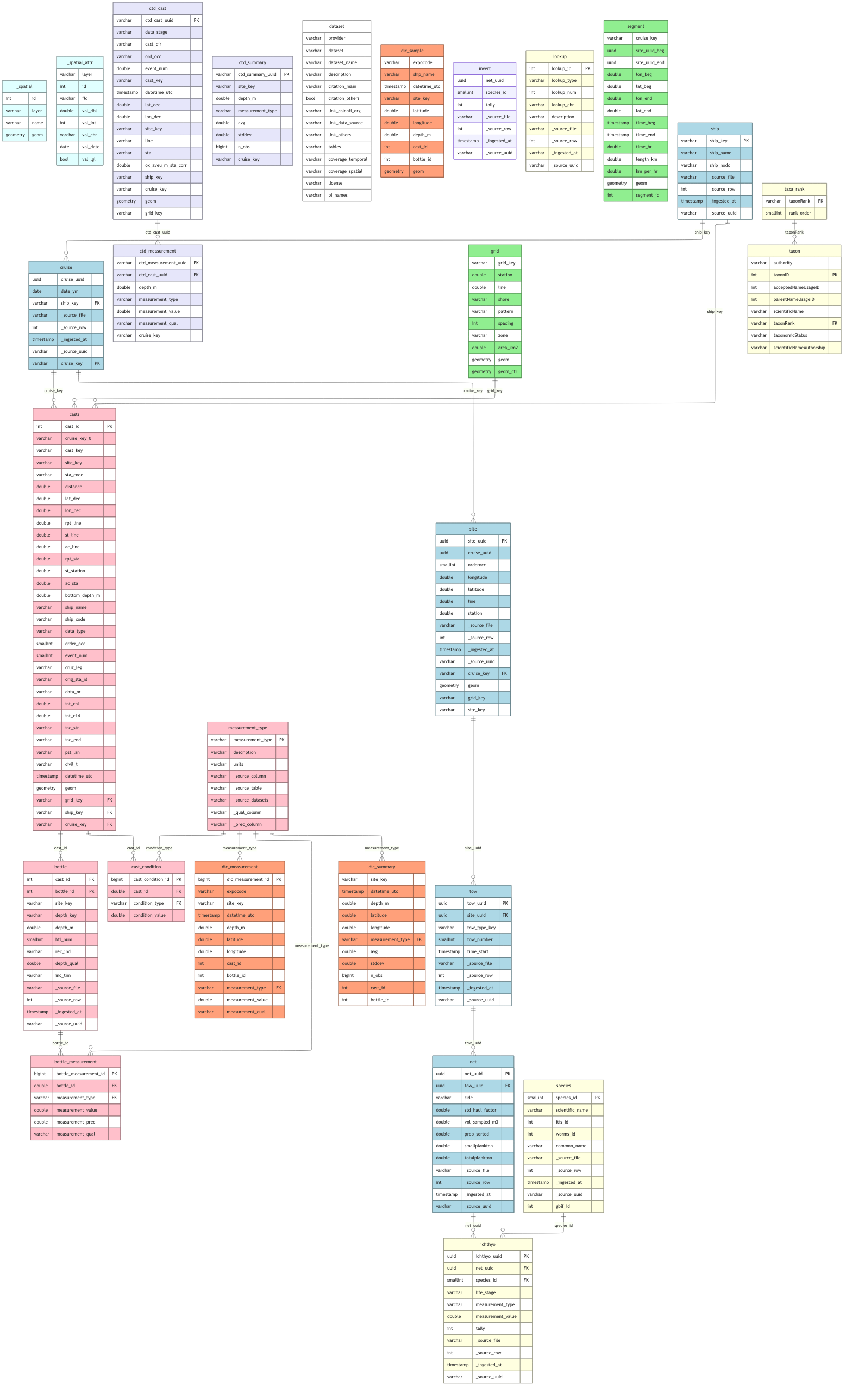
## Show Combined Schema
```{r}
# dir_frozen used later; define early so ERD can reference it
dir_frozen <- here(glue("data/releases/{release_version}"))
dir.create(dir_frozen, recursive = TRUE, showWarnings = FALSE)
# --- retire the per-dataset event/measurement/summary + per-dataset taxon tables
# the consolidated core (obs/sample/obs_attribute/sample_measurement) + unified
# taxon/dataset_taxon/taxon_group replace them; all were materialized upstream, so
# drop them now. `core_keep` = the DEFAULT published set (in the ERD + catalog);
# `supplemental_keep` = ancillary full tables that are hosted + tagged to the
# release but excluded from the ERD and default table list (opt-in deep dives).
core_keep <- c(
"obs", "sample", "obs_attribute", "sample_measurement", # core facts
"grid", "cruise", "ship", "measurement_type", "dataset", "region", # refs
"taxon", "dataset_taxon", "taxon_group", "lookup", # taxa + lookups
"_spatial", "_spatial_attr")
supplemental_keep <- c("obs_ctd_full") # hosted, hidden by default
# drop by the object's actual type (DROP VIEW on a TABLE — or vice versa — errors
# even with IF EXISTS; some are parquet VIEWs, some are temp tables like cruise_ref)
retire_objs <- DBI::dbGetQuery(con_wdl,
"SELECT table_name, table_type FROM information_schema.tables")
retire_objs <- retire_objs[!retire_objs$table_name %in% c(core_keep, supplemental_keep) &
retire_objs$table_name != "_measurement_taxon", , drop = FALSE]
for (i in seq_len(nrow(retire_objs))) {
kind <- if (grepl("VIEW", retire_objs$table_type[i], ignore.case = TRUE)) "VIEW" else "TABLE"
DBI::dbExecute(con_wdl, glue('DROP {kind} IF EXISTS "{retire_objs$table_name[i]}"'))
}
retire_tbls <- retire_objs$table_name
message(glue("retired {length(retire_tbls)} per-dataset tables: ",
"{paste(head(retire_tbls, 8), collapse=', ')}…"))
erd <- cc_erd(con_wdl, layout = "elk")
plot(erd)
erd <- cc_erd(con_wdl, colors = color_map)
plot(erd)
```
```{r}
#| label: combined_schema
#| fig-width: 12
#| fig-height: 10
# exclude internal tables and the SUPPLEMENTAL tables (obs_ctd_full) so the ERD
# stays the default core schema. Use the CURRENT tables (the retire step above
# dropped the per-dataset tables) so the ERD + FK checks are core-only.
schema_tbls <- setdiff(
DBI::dbListTables(con_wdl),
c("_meta", "_sp_update", "casts_derived", "ctd_cast_derived",
"_measurement_taxon", supplemental_keep))
# merge per-dataset relationships.json files (auto-discovered — every ingest
# writes data/parquet/{provider}_{dataset}/relationships.json, so new datasets
# are picked up without editing this list)
rels_paths <- Sys.glob(here("data/parquet/*/relationships.json"))
dir_frozen <- here(glue("data/releases/{release_version}"))
dir.create(dir_frozen, recursive = TRUE, showWarnings = FALSE)
rels_merged_path <- file.path(dir_frozen, "relationships.json")
if (length(rels_paths) > 0) {
merge_relationships_json(rels_paths, rels_merged_path)
# append cross-dataset FKs authored in metadata/relationships_cross.csv
rels_merged <- jsonlite::fromJSON(
rels_merged_path, simplifyVector = FALSE)
rels_merged$foreign_keys <- c(
rels_merged$foreign_keys, cross_fks)
jsonlite::write_json(
rels_merged, rels_merged_path,
auto_unbox = TRUE, pretty = TRUE, null = "null")
# emit a flat, reviewable view of every relationship (intra + cross) alongside
# relationships.json / erd.mmd, so the cross-dataset graph is legible as a table
g <- function(x, k) { v <- x[[k]]; if (is.null(v)) NA_character_ else as.character(v) }
fk_df <- do.call(rbind, lapply(rels_merged$foreign_keys, function(fk)
data.frame(
from_table = g(fk, "table"), from_column = g(fk, "column"),
to_table = g(fk, "ref_table"), to_column = g(fk, "ref_column"),
stringsAsFactors = FALSE)))
cross_keys <- paste(cross_fks_df$table, cross_fks_df$column,
cross_fks_df$ref_table, cross_fks_df$ref_column)
fk_df$scope <- ifelse(
paste(fk_df$from_table, fk_df$from_column,
fk_df$to_table, fk_df$to_column) %in% cross_keys, "cross", "intra")
readr::write_csv(fk_df, file.path(dir_frozen, "relationships_all.csv"))
# validate: every cross-FK target column exists in the assembled release schema
schema_cols <- unlist(lapply(schema_tbls, function(t)
paste(t, DBI::dbListFields(con_wdl, t))))
cross_targets <- paste(cross_fks_df$ref_table, cross_fks_df$ref_column)
missing_targets <- cross_fks_df[!(cross_targets %in% schema_cols), , drop = FALSE]
if (nrow(missing_targets) > 0) {
warning(glue(
"cross-FK target(s) missing from release schema: ",
"{paste(missing_targets$ref_table, missing_targets$ref_column, collapse = ', ')}"))
} else {
message(glue(
"cross-FK check: all {nrow(cross_fks_df)} cross-dataset targets present; ",
"wrote {nrow(fk_df)} relationships to relationships_all.csv"))
}
}
# render dataset-colored ERD (stroke outlines; cc_erd handles GEOMETRY natively)
cc_erd(
con_wdl,
tables = schema_tbls,
rels_path = rels_merged_path,
colors = color_map)
```
## Create Frozen Release
Strip provenance columns and export clean parquet files for public
access. See
[Frozen DuckLake](https://ducklake.select/2025/10/24/frozen-ducklake/)
pattern.
```{r}
#| label: freeze_release
dir_frozen <- here(glue("data/releases/{release_version}"))
dir_frozen_pq <- file.path(dir_frozen, "parquet")
dir.create(dir_frozen_pq, recursive = TRUE, showWarnings = FALSE)
message(glue("Creating frozen release: {release_version}"))
# `cruise` is enriched (derived) in this notebook — export locally
# all other tables are GCS-copied from ingest/ (including provenance columns)
derived_tables <- "cruise"
if (nrow(new_tables) > 0) {
# tables with _new additions need local merge + export
merged_base <- unique(sub("_new$", "", new_tables$table))
derived_tables <- c(derived_tables, merged_base)
}
# export only derived/merged tables to local parquet
export_parquet(con_wdl, "cruise",
file.path(dir_frozen_pq, "cruise.parquet"), compression = "zstd")
message("Exported cruise.parquet")
# export merged tables (e.g., ship with _new additions)
for (tbl in setdiff(derived_tables, "cruise")) {
export_parquet(con_wdl, tbl,
file.path(dir_frozen_pq, paste0(tbl, ".parquet")), compression = "zstd")
message(glue("Exported {tbl}.parquet (merged)"))
}
# --- consolidated core tables (derived here in Phase 2) ---------------------
# single-file exports (sample carries geom as GeoParquet; the long tables +
# measurement_type are plain); obs / obs_ctd_full are Hive-partitioned + sorted
# for compression + predicate pushdown (see design "Parquet partitioning").
core_single <- intersect(
c("sample", "obs_attribute", "sample_measurement", "measurement_type",
"taxon", "dataset_taxon", "taxon_group"), # unified taxa refs, rebuilt here
dbListTables(con_wdl))
for (tbl in core_single)
export_parquet(con_wdl, tbl,
file.path(dir_frozen_pq, paste0(tbl, ".parquet")), compression = "zstd")
core_sort <- "grid_key NULLS LAST, depth_min_m NULLS LAST, measurement_type"
if ("obs" %in% dbListTables(con_wdl)) {
dbExecute(con_wdl, glue(
"COPY (SELECT * FROM obs ORDER BY dataset_key, {core_sort})
TO '{file.path(dir_frozen_pq, 'obs')}'
(FORMAT PARQUET, COMPRESSION 'zstd', PARTITION_BY (dataset_key), OVERWRITE_OR_IGNORE)"))
# also a single-file obs.parquet: browser DuckDB-WASM (db-query/match.js) and
# plain-HTTPS consumers can't glob the Hive-partitioned obs/ dir over GCS.
export_parquet(con_wdl, glue("SELECT * FROM obs ORDER BY dataset_key, {core_sort}"),
file.path(dir_frozen_pq, "obs.parquet"), compression = "zstd")
}
if (build_obs_ctd_full && "obs_ctd_full" %in% dbListTables(con_wdl))
dbExecute(con_wdl, glue(
"COPY (SELECT * FROM obs_ctd_full ORDER BY cruise_key, {core_sort})
TO '{file.path(dir_frozen_pq, 'obs_ctd_full')}'
(FORMAT PARQUET, COMPRESSION 'zstd', PARTITION_BY (cruise_key), OVERWRITE_OR_IGNORE)"))
message(glue("Exported core tables: {paste(core_single, collapse=', ')}, obs (partitioned)"))
# build freeze stats from registry (auto-discovered)
# exclude _new delta tables (intermediate) and supplemental
freeze_stats <- reg_canon |>
filter(!supplemental, !grepl("_new$", table)) |>
select(table, rows, partitioned, gcs_prefix)
# merged tables (from _new additions) → mark as derived (gcs_prefix = NA → upload from local)
if (nrow(new_tables) > 0) {
merged_base <- unique(sub("_new$", "", new_tables$table))
freeze_stats <- freeze_stats |>
mutate(gcs_prefix = if_else(table %in% merged_base, NA_character_, gcs_prefix))
}
# add derived tables (cruise, etc.)
for (dt in derived_tables) {
if (!dt %in% freeze_stats$table) {
n <- dbGetQuery(con_wdl, glue("SELECT COUNT(*) AS n FROM {dt}"))$n
freeze_stats <- freeze_stats |>
bind_rows(tibble(
table = dt, rows = n, partitioned = FALSE, gcs_prefix = NA_character_))
}
}
# `measurement_type` (rebuilt from the authoritative CSV), `cruise` (enriched
# with per-dataset event counts), and the unified taxon refs (taxon/dataset_taxon/
# taxon_group, rebuilt from the per-dataset taxon tables) are derived + exported
# locally here, so upload the local copy rather than GCS-copying the stale ingest
# parquet (esp. the old ichthyo `taxon` hierarchy the new `taxon` replaces).
freeze_stats <- freeze_stats |>
mutate(gcs_prefix = if_else(
table %in% c("measurement_type", "cruise", "taxon", "dataset_taxon", "taxon_group"),
NA_character_, gcs_prefix))
# add consolidated core + supplemental tables (gcs_prefix = NA → upload from local)
core_spec <- tibble(
table = c("sample", "obs", "obs_attribute", "sample_measurement", "obs_ctd_full",
"dataset_taxon", "taxon_group"),
partitioned = c(FALSE, TRUE, FALSE, FALSE, TRUE,
FALSE, FALSE))
core_spec <- core_spec |>
filter(table %in% dbListTables(con_wdl), !table %in% freeze_stats$table) |>
mutate(
rows = vapply(table, function(t)
as.numeric(dbGetQuery(con_wdl, glue("SELECT COUNT(*) AS n FROM {t}"))$n), numeric(1)),
gcs_prefix = NA_character_)
freeze_stats <- bind_rows(freeze_stats, core_spec)
# keep only the DEFAULT core + shared refs + unified taxa (`core_keep`) plus the
# SUPPLEMENTAL tables (`obs_ctd_full`); flag the latter so the catalog/metadata
# mark them and cc_get_db()/db-schema hide them by default.
freeze_stats <- freeze_stats |>
filter(table %in% c(core_keep, supplemental_keep)) |>
mutate(supplemental = table %in% supplemental_keep)
# refresh row counts from the ASSEMBLED DB — reg_canon carries stale ingest-manifest
# counts for the rebuilt/derived tables (measurement_type from CSV, the unified
# `taxon` that replaces the old hierarchy, cruise, …), so the catalog/metadata
# would otherwise show wrong `rows`. The frozen parquet is already correct.
.present <- intersect(freeze_stats$table, DBI::dbListTables(con_wdl))
.rows_now <- setNames(
vapply(.present, function(t)
as.numeric(dbGetQuery(con_wdl, glue("SELECT COUNT(*) AS n FROM \"{t}\""))$n), numeric(1)),
.present)
freeze_stats <- freeze_stats |>
mutate(rows = ifelse(table %in% .present, .rows_now[table], rows))
freeze_stats |>
datatable(caption = glue("Frozen release {release_version} — {nrow(freeze_stats)} core+ref tables"))
```
## Release Notes
```{r}
#| label: release_notes
#| results: asis
# build release notes
tables_list <- paste0(
"- ",
freeze_stats$table,
" (",
format(freeze_stats$rows, big.mark = ","),
" rows)"
)
release_notes <- paste0(
"# CalCOFI Database Release ",
release_version,
"\n\n",
"**Release Date**: ",
Sys.Date(),
"\n\n",
"## Tables Included\n\n",
paste(tables_list, collapse = "\n"),
"\n\n",
"## Total\n\n",
"- **Tables**: ",
nrow(freeze_stats),
"\n",
"- **Total Rows**: ",
format(sum(freeze_stats$rows, na.rm = TRUE), big.mark = ","),
"\n\n",
"## Data Sources\n\n",
"- `ingest_swfsc_ichthyo.qmd` - Ichthyo tables (cruise, ship, site, tow, net, species, ichthyo, grid, segment, lookup, taxon, taxa_rank)\n",
"- `ingest_calcofi_bottle.qmd` - Bottle/cast tables (casts, bottle, bottle_measurement, cast_condition, measurement_type)\n",
"- `ingest_calcofi_ctd-cast.qmd` - CTD tables (ctd_cast, ctd_thin, ctd_summary, measurement_type; full ctd_measurement available as supplemental)\n",
"- `ingest_calcofi_dic.qmd` - DIC/alkalinity tables (dic_sample, dic_measurement, dic_summary, dataset)\n\n",
"## Cross-Dataset Integration\n\n",
"- **Ship matching**: Reconciled ship codes between bottle casts and swfsc ship reference\n",
"- **Cruise bridge**: Derived cruise_key (YYYY-MM-NODC) for bottle casts via ship matching + datetime\n",
"- **Taxonomy**: Standardized species with WoRMS AphiaID, ITIS TSN, GBIF backbone key\n",
"- **Taxon hierarchy**: Built taxon + taxa_rank tables from WoRMS/ITIS classification\n\n",
"## Access\n\n",
"Parquet files can be queried directly from GCS:\n\n",
"```r\n",
"library(duckdb)\n",
"con <- dbConnect(duckdb())\n",
"dbExecute(con, 'INSTALL httpfs; LOAD httpfs;')\n",
"dbGetQuery(con, \"\n",
" SELECT * FROM read_parquet(\n",
" 'https://storage.googleapis.com/calcofi-db/ducklake/releases/",
release_version,
"/parquet/ichthyo.parquet')\n",
" LIMIT 10\")\n",
"```\n\n",
"Or use calcofi4r:\n\n",
"```r\n",
"library(calcofi4r)\n",
"con <- cc_get_db(version = '",
release_version,
"')\n",
"```\n"
)
writeLines(release_notes, file.path(dir_frozen, "RELEASE_NOTES.md"))
message(glue(
"Release notes written to {file.path(dir_frozen, 'RELEASE_NOTES.md')}"
))
cat(release_notes)
```
## Upload Frozen Release to GCS
```{r}
#| label: upload_frozen
gcs_bucket <- "calcofi-db"
gcs_release <- glue("ducklake/releases/{release_version}")
gcloud <- find_gcloud()
# 1. GCS server-side copy for ingest tables (auto-discovered from registry)
copy_rows <- freeze_stats |> filter(!is.na(gcs_prefix))
message(glue("Copying {nrow(copy_rows)} tables from ingest/ to releases/ on GCS..."))
for (i in seq_len(nrow(copy_rows))) {
tbl <- copy_rows$table[i]
pfx <- copy_rows$gcs_prefix[i]
part <- copy_rows$partitioned[i]
if (part) {
# partitioned: copy directory
src <- glue("gs://{gcs_bucket}/{pfx}/{tbl}")
dst <- glue("gs://{gcs_bucket}/{gcs_release}/parquet/{tbl}")
res <- system2(gcloud, c("storage", "cp", "-r",
paste0(src, "/*"), dst), stdout = TRUE, stderr = TRUE)
} else {
src <- glue("gs://{gcs_bucket}/{pfx}/{tbl}.parquet")
dst <- glue("gs://{gcs_bucket}/{gcs_release}/parquet/{tbl}.parquet")
res <- system2(gcloud, c("storage", "cp",
src, dst), stdout = TRUE, stderr = TRUE)
}
rc <- attr(res, "status") %||% 0L
if (rc != 0) {
stop(glue("GCS copy failed for {tbl}: {src} -> {dst}\n",
" exit code {rc}: {paste(res, collapse = '\n')}"))
}
message(glue(" {tbl}: copied from {pfx}"))
}
# 2. upload derived tables from local parquet — single files (cruise,
# measurement_type, sample, obs_attribute, sample_measurement) AND partitioned dirs
# (obs, obs_ctd_full: Hive-partitioned, uploaded recursively).
derived_local <- list.files(dir_frozen_pq, pattern = "[.]parquet$",
full.names = TRUE)
for (pq in derived_local) {
tbl <- tools::file_path_sans_ext(basename(pq))
gcs_path <- glue("gs://{gcs_bucket}/{gcs_release}/parquet/{tbl}.parquet")
put_gcs_file(pq, gcs_path)
message(glue(" {tbl}: uploaded (derived)"))
}
# partitioned derived dirs (obs, obs_ctd_full)
derived_dirs <- list.dirs(dir_frozen_pq, recursive = FALSE)
for (d in derived_dirs) {
tbl <- basename(d)
dst <- glue("gs://{gcs_bucket}/{gcs_release}/parquet/{tbl}")
res <- system2(gcloud, c("storage", "cp", "-r", paste0(d, "/*"), dst),
stdout = TRUE, stderr = TRUE)
if ((attr(res, "status") %||% 0L) != 0)
stop(glue("GCS copy failed for derived partitioned {tbl}: {paste(res, collapse='\n')}"))
message(glue(" {tbl}: uploaded (derived, partitioned)"))
}
# 3. build and upload catalog.json (needed by cc_get_db())
tables_df <- freeze_stats |>
mutate(supplemental = dplyr::coalesce(supplemental, FALSE)) |>
select(name = table, rows, partitioned, supplemental)
# sum bytes of the uploaded parquet tree on GCS
du_out <- system2(
gcloud,
c("storage", "du", "--summarize",
glue("gs://{gcs_bucket}/{gcs_release}/parquet/")),
stdout = TRUE, stderr = TRUE)
total_bytes <- suppressWarnings(
as.numeric(sub("\\s.*$", "", trimws(du_out[1]))))
if (is.na(total_bytes)) {
warning(glue("Could not parse gcloud storage du output: {paste(du_out, collapse='; ')}"))
total_bytes <- 0
}
catalog <- list(
version = release_version,
release_date = as.character(Sys.Date()),
total_rows = sum(tables_df$rows, na.rm = TRUE),
total_size = total_bytes,
tables = tables_df)
catalog_path <- file.path(dir_frozen, "catalog.json")
jsonlite::write_json(catalog, catalog_path, auto_unbox = TRUE, pretty = TRUE)
put_gcs_file(catalog_path,
glue("gs://{gcs_bucket}/{gcs_release}/catalog.json"))
# upload RELEASE_NOTES.md
notes_path <- file.path(dir_frozen, "RELEASE_NOTES.md")
if (file.exists(notes_path))
put_gcs_file(notes_path,
glue("gs://{gcs_bucket}/{gcs_release}/RELEASE_NOTES.md"))
# upload relationships.json
rels_json <- file.path(dir_frozen, "relationships.json")
if (file.exists(rels_json))
put_gcs_file(rels_json,
glue("gs://{gcs_bucket}/{gcs_release}/relationships.json"))
# build and upload metadata.json (table/column descriptions + units).
# auto-discover every ingest's metadata.json (same as rels_paths) so newly added
# datasets' tables/columns are merged in — not just a hardcoded set.
meta_paths <- Sys.glob(here("data/parquet/*/metadata.json"))
meta_json_path <- file.path(dir_frozen, "metadata.json")
if (length(meta_paths) > 0) {
# data-derived one-to-many measurement_type -> dataset(s) map. build the
# table -> owning-dataset(s) lookup from the ingest YAML's tables_owned (the
# `measurement_type` lookup table is excluded — its measurement_type column is
# the vocabulary, not measured rows), then scan each measurement table in the
# assembled DB for the types it actually reports.
table_datasets <- list()
for (key in names(ingest_yaml)) {
cc <- ingest_yaml[[key]]
for (e in cc$tables_owned %||% list())
table_datasets[[e$table]] <- union(table_datasets[[e$table]], key)
for (ad in cc$additional_datasets %||% list()) {
k2 <- paste0(ad$provider, "_", ad$dataset)
for (e in ad$tables_owned %||% list())
table_datasets[[e$table]] <- union(table_datasets[[e$table]], k2)
}
}
table_datasets[["measurement_type"]] <- NULL
meas_ds <- derive_measurement_type_datasets(con_wdl, table_datasets)
cat(glue("derived dataset membership for {length(meas_ds)} measurement types\n"))
merge_metadata_json(
paths = meta_paths,
output_path = meta_json_path,
release_version = release_version,
release_tables_csv = here("metadata/release_tables.csv"),
release_columns_csv = here("metadata/release_columns.csv"),
measurement_type_csv = here("metadata/measurement_type.csv"),
ingest_yaml = ingest_yaml,
table_rows = setNames(freeze_stats$rows, freeze_stats$table),
measurement_datasets = meas_ds)
# enrich columns with data_type from the working DuckDB (so the schema
# site can render types without spinning up DuckDB-WASM)
schema_cols <- DBI::dbGetQuery(con_wdl, "
SELECT table_name, column_name, data_type
FROM information_schema.columns
WHERE table_schema = 'main'")
meta <- jsonlite::read_json(meta_json_path, simplifyVector = FALSE)
n_typed <- 0L
for (i in seq_len(nrow(schema_cols))) {
key <- paste0(schema_cols$table_name[i], ".", schema_cols$column_name[i])
if (key %in% names(meta$columns)) {
meta$columns[[key]]$data_type <- schema_cols$data_type[i]
} else {
meta$columns[[key]] <- list(data_type = schema_cols$data_type[i])
}
n_typed <- n_typed + 1L
}
# --- contributions + observed temporal for the derived core tables ---------
# obs/sample/obs_attribute/sample_measurement are materialized here (no per-ingest
# metadata.json), so compute each dataset's row share directly from the data.
# Unlike the measurement_type vocabulary lookup, every core row belongs to
# exactly one dataset (dataset_key) -> clean, non-over-attributed stacks.
ds_workflow <- vapply(ingest_yaml,
function(cc) cc$workflow_url %||% NA_character_, character(1))
for (tbl in intersect(c("obs", "sample", "obs_attribute", "sample_measurement"),
dbListTables(con_wdl))) {
by_ds <- DBI::dbGetQuery(con_wdl, glue(
"SELECT dataset_key, COUNT(*) AS n FROM {tbl} GROUP BY 1 ORDER BY n DESC"))
total <- sum(by_ds$n)
meta$contributions[[tbl]] <- list(
total_rows = total,
over_attributed = FALSE,
by_dataset = lapply(seq_len(nrow(by_ds)), function(i) list(
provider_dataset = by_ds$dataset_key[i],
rows = by_ds$n[i],
pct = round(by_ds$n[i] / total * 100, 1),
workflow = unname(ds_workflow[by_ds$dataset_key[i]]))))
}
# observed temporal extent per dataset from the real data (obs + sample),
# replacing the static coverage_temporal from QMD frontmatter on the cards.
obs_time <- DBI::dbGetQuery(con_wdl,
"SELECT dataset_key, strftime(min(datetime), '%Y-%m') AS t_min,
strftime(max(datetime), '%Y-%m') AS t_max
FROM (SELECT dataset_key, datetime FROM obs WHERE datetime IS NOT NULL
UNION ALL SELECT dataset_key, datetime FROM sample WHERE datetime IS NOT NULL)
GROUP BY 1")
for (i in seq_len(nrow(obs_time))) {
k <- obs_time$dataset_key[i]
if (k %in% names(meta$datasets))
meta$datasets[[k]]$coverage_temporal_observed <-
paste(obs_time$t_min[i], "to", obs_time$t_max[i])
}
# retire per-dataset tables from metadata.json too (core_keep + supplemental
# from the retire step) so the schema site's Tables/ERD/contributions show only
# the core+refs+taxa (obs_ctd_full is kept but flagged supplemental below).
keep_meta <- c(core_keep, supplemental_keep)
meta$tables <- meta$tables[names(meta$tables) %in% keep_meta]
meta$contributions <- meta$contributions[names(meta$contributions) %in% keep_meta]
meta$columns <- meta$columns[
vapply(names(meta$columns), function(k) sub("[.].*$", "", k) %in% keep_meta, logical(1))]
# mark the supplemental tables in metadata.json so db-schema can badge + hide
for (t in intersect(supplemental_keep, names(meta$tables)))
meta$tables[[t]]$supplemental <- TRUE
jsonlite::write_json(meta, meta_json_path,
auto_unbox = TRUE, pretty = TRUE, null = "null")
message(glue("metadata.json enriched with data_type for {n_typed} columns"))
put_gcs_file(meta_json_path,
glue("gs://{gcs_bucket}/{gcs_release}/metadata.json"))
# erd.mmd sidecar: Mermaid ER diagram driven by relationships.json
rels_for_erd <- file.path(dir_frozen, "relationships.json")
if (file.exists(rels_for_erd)) {
erd <- cc_erd(
con = con_wdl,
rels_path = rels_for_erd,
colors = color_map,
view_type = "all")
erd_path <- file.path(dir_frozen, "erd.mmd")
writeLines(unclass(erd), erd_path)
# validate the Mermaid parses before publishing — a malformed erd.mmd
# (e.g. erDiagram styling unsupported by an older mermaid) would break the
# schema site, which renders it client-side with mermaid. Validate with
# mermaid-cli (mmdc); KEEP schema/_config.yml `mermaid_version` >= this
# mmdc's bundled mermaid so the site accepts what passes here.
mmdc <- Sys.which("mmdc")
if (nzchar(mmdc)) {
erd_svg_check <- tempfile(fileext = ".svg")
erd_val <- suppressWarnings(system2(
mmdc, c("-i", erd_path, "-o", erd_svg_check),
stdout = TRUE, stderr = TRUE))
if (!identical(attr(erd_val, "status"), NULL) &&
!identical(attr(erd_val, "status"), 0L)) {
stop(glue(
"erd.mmd failed Mermaid validation; not uploading.\n",
"{paste(erd_val, collapse = '\n')}"))
}
message("erd.mmd passed Mermaid validation (mmdc)")
} else {
warning("mmdc not found; skipping Mermaid validation of erd.mmd")
}
put_gcs_file(erd_path,
glue("gs://{gcs_bucket}/{gcs_release}/erd.mmd"))
message(glue("erd.mmd uploaded ({length(attr(erd, 'tables'))} tables)"))
} else {
warning("relationships.json missing; skipping erd.mmd sidecar")
}
} else {
warning("No per-ingest metadata.json files found; skipping release metadata.json")
}
# 4. update versions.json (latest.txt promotion is deferred to test_release.qmd)
# discover all releases from GCS and rebuild versions.json
gcs_ls <- system2(gcloud, c("storage", "ls",
glue("gs://{gcs_bucket}/ducklake/releases/")),
stdout = TRUE, stderr = TRUE)
release_vers <- regmatches(gcs_ls,
regexpr("v[0-9]{4}[.][0-9]{2}[.]*[0-9]*", gcs_ls))
https_base <- glue("https://storage.googleapis.com/{gcs_bucket}/ducklake/releases")
all_versions <- purrr::compact(lapply(release_vers, function(v) {
tryCatch({
cat_data <- jsonlite::fromJSON(glue("{https_base}/{v}/catalog.json"))
list(
version = cat_data$version,
release_date = cat_data$release_date %||% NA_character_,
tables = if (is.data.frame(cat_data$tables)) nrow(cat_data$tables)
else length(cat_data$tables),
total_rows = as.integer(cat_data$total_rows %||% 0),
size_mb = round((cat_data$total_size %||% 0) / 1024 / 1024, 1))
}, error = function(e) NULL)
}))
all_versions <- all_versions[order(
sapply(all_versions, `[[`, "version"), decreasing = TRUE)]
versions_local <- tempfile(fileext = ".json")
jsonlite::write_json(list(versions = all_versions), versions_local,
auto_unbox = TRUE, pretty = TRUE)
put_gcs_file(versions_local,
glue("gs://{gcs_bucket}/ducklake/releases/versions.json"))
# the schema site (calcofi.io/db-schema) fetches these JSON/mmd sidecars at runtime
# and they are OVERWRITTEN in place when a release is re-run (e.g. to fix a bug).
# GCS defaults to `cache-control: public, max-age=3600`, so a corrected re-upload
# stays masked by browser/CDN caches for up to an hour. Tag the mutable sidecars
# `no-cache` (revalidate-always; cheap 304s) so a re-render is visible immediately.
sidecar_urls <- c(
glue("gs://{gcs_bucket}/ducklake/releases/versions.json"),
glue("gs://{gcs_bucket}/{gcs_release}/catalog.json"),
glue("gs://{gcs_bucket}/{gcs_release}/metadata.json"),
glue("gs://{gcs_bucket}/{gcs_release}/relationships.json"),
glue("gs://{gcs_bucket}/{gcs_release}/erd.mmd"),
glue("gs://{gcs_bucket}/{gcs_release}/RELEASE_NOTES.md"))
cc_res <- system2(gcloud,
c("storage", "objects", "update", "--cache-control=no-cache", sidecar_urls),
stdout = TRUE, stderr = TRUE)
if (!identical(attr(cc_res, "status") %||% 0L, 0L))
warning(glue("could not set no-cache on sidecars: {paste(cc_res, collapse='; ')}"))
message("runtime sidecars tagged cache-control: no-cache")
# NOTE: latest.txt is NOT updated here. Promotion is gated on the
# query-test pass in test_release.qmd, which writes latest.txt only
# when every pre-baked query in CalCOFI/db-query/_queries succeeds.
message(glue(
"Release {release_version} uploaded ({length(all_versions)} versions tracked); ",
"latest.txt promotion deferred to test_release.qmd"))
```
## Cleanup
```{r}
#| label: cleanup
# close in-memory DuckDB connection
close_duckdb(con_wdl)
message("Assembly DuckDB connection closed")
# summary
message(glue("\n=== Summary ==="))
message(glue("Frozen release: {release_version} created at {dir_frozen}"))
message(glue("Tables: {nrow(freeze_stats)}"))
message(glue("Total rows: {format(sum(freeze_stats$rows, na.rm = TRUE), big.mark = ',')}"))
```
::: {.callout-caution collapse="true"}
## Session Info
```{r session_info}
devtools::session_info()
```
:::