Code
graph LR
A[PNTtable.csv<br/>148,129 tows] --> B[filter CalCOFI bbox]
B --> C[zooplankton_tow<br/>position + gear + keys]
C -.ship/cruise/grid.-> D[(shared refs)]
C -.biovolume pending.-> E[zooplankton_measurement]
Source: SIOPIC_DB_PNTtable_allRecords_9Feb2026.csv (~19 MB, 148,129 net tows), the parent-net-tow (PNT) registry of the SIO Pelagic Invertebrate Collection (PI: Rasmus Swalethorp, Ed Weber, Linsey Sala).
piczooplankton_tow; the biovolume measurement table is pending from the provider (blocker Q01) and will be added as zooplankton_measurement.graph LR
A[PNTtable.csv<br/>148,129 tows] --> B[filter CalCOFI bbox]
B --> C[zooplankton_tow<br/>position + gear + keys]
C -.ship/cruise/grid.-> D[(shared refs)]
C -.biovolume pending.-> E[zooplankton_measurement]
devtools::load_all(here::here("../calcofi4db"))
devtools::load_all(here::here("../calcofi4r"))
librarian::shelf(
CalCOFI/calcofi4db, CalCOFI/calcofi4r,
DBI, dplyr, DT, fs, glue, here, htmltools, janitor, jsonlite, knitr,
lubridate, purrr, readr, sf, stringr, tibble, tidyr, units,
quiet = T)
options(readr.show_col_types = F)
options(DT.options = list(scrollX = TRUE))
source(here("libs/ingest.R"))
cc <- read_calcofi_meta(here("ingest_pic_zooplankton.qmd"))
provider <- cc$provider
dataset <- cc$dataset
dataset_name <- cc$dataset_meta$dataset_name
tables_owned <- cc$tables_owned
dir_label <- glue("{provider}_{dataset}")
dir_parquet <- here(glue("data/parquet/{dir_label}"))
db_path <- here(glue("data/wrangling/{dir_label}.duckdb"))
if (overwrite) {
if (file_exists(db_path)) file_delete(db_path)
if (file_exists(paste0(db_path, ".wal"))) file_delete(paste0(db_path, ".wal"))
if (dir_exists(paste0(db_path, ".tmp"))) dir_delete(paste0(db_path, ".tmp"))
}
dir_create(dirname(db_path))
con <- get_duckdb_con(db_path)
load_duckdb_extension(con, "spatial")Read directly from {dir_data}/calcofi/zooplankton/ (the file is not under a pic/ subdirectory). Columns renamed per metadata/pic/zooplankton/flds_redefine.csv.
zoo_csv <- path_expand(glue(
"{dir_data}/calcofi/zooplankton/SIOPIC_DB_PNTtable_allRecords_9Feb2026.csv"))
stopifnot("zooplankton CSV not found" = file_exists(zoo_csv))
sync_to_gcs(
local_dir = path_dir(zoo_csv),
gcs_prefix = glue("archive/{provider}/{dataset}"),
bucket = "calcofi-files-public",
exclude = c(".DS_Store", "*.tmp", "*.gdoc"))# A tibble: 2 × 4
file action size reason
<chr> <chr> <dbl> <chr>
1 SIOPIC_DB_PNTtable_allRecords_9Feb2026.csv skipped 19730214 checksum match
2 SIOPIC_DB_PNTtable_fieldDetails_9Feb2026.xlsx skipped 10932 checksum matchd_raw <- read_csv(zoo_csv, col_types = cols(.default = "c")) # read all as text, cast below
cat(glue("Read {format(nrow(d_raw), big.mark=',')} tows, {ncol(d_raw)} columns"), "\n")Read 148,129 tows, 20 columns Canonical names from metadata/field_dictionary.csv. Tows are filtered to the CalCOFI bounding box (the scope decision); this also excludes the |lon|>180 coordinate errors (Q04). Datetimes are built from date (MM/DD/YYYY) + HHMM time (treated as given pending the timezone answer, Q03).
hhmm_to_dt <- function(date, hhmm) {
t <- str_pad(na_if(str_trim(hhmm), ""), 4, pad = "0")
out <- suppressWarnings(as_datetime(paste0(
date, " ", substr(t, 1, 2), ":", substr(t, 3, 4), ":00")))
out[is.na(t) & !is.na(date)] <- as_datetime(as.character(date[is.na(t) & !is.na(date)]))
out
}
d_clean <- d_raw |>
transmute(
expedition = EXPEDITION_pnt,
expedition_code = EXPED_CODE_pnt,
expedition_type = Expedition_Type_pnt,
ship_name = SHIP_pnt,
order_occ = suppressWarnings(as.integer(SWFOrder_Occ)),
line = suppressWarnings(as.numeric(STATION_LINE_pnt)),
station = suppressWarnings(as.numeric(STATION_NUMBER_pnt)),
latitude = suppressWarnings(as.numeric(LAT_DECIMAL_pnt)),
longitude = suppressWarnings(as.numeric(LONG_DECIMAL_pnt)),
date = suppressWarnings(as.Date(SAMPLE_DATE_pnt, format = "%m/%d/%Y")),
datetime_start_utc = hhmm_to_dt(date, START_TIME_pnt), # Q03: assumed UTC
datetime_end_utc = hhmm_to_dt(date, END_TIME_pnt),
depth_min_m = suppressWarnings(as.numeric(DEPTH_MIN_pnt)),
depth_max_m = suppressWarnings(as.numeric(DEPTH_MAX_pnt)),
max_wire_out_m = suppressWarnings(as.numeric(MAX_MWO_pnt)),
net_type = NET_TYPE_pnt,
mesh_size_mm = suppressWarnings(as.numeric(MESH_SIZE_pnt)),
tow_type = TOW_TYPE_pnt,
fixative = FIXATIVE_pnt,
preservative = PRESERVATIVE_pnt)
n_all <- nrow(d_clean)
# scope filter: CalCOFI region bounding box (incl. Baja); drops global + bad coords
d_cc <- d_clean |>
filter(!is.na(latitude), !is.na(longitude),
latitude >= 23, latitude <= 51,
longitude >= -135, longitude <= -117) |>
mutate(
site_key = if_else(
is.na(line) | is.na(station), NA_character_,
sprintf("%05.1f %05.1f", line, station)),
tow_id = row_number())
cat(glue(
"CalCOFI-region filter: {format(nrow(d_cc), big.mark=',')}/",
"{format(n_all, big.mark=',')} tows retained ",
"({round(100*nrow(d_cc)/n_all, 1)}%)"), "\n")CalCOFI-region filter: 99,530/148,129 tows retained (67.2%) dbWriteTable(con, "zooplankton_tow", d_cc, overwrite = TRUE)load_prior_tables(
con, parquet_dir = here("data/parquet/swfsc_ichthyo"),
tables = c("ship", "cruise", "grid"), geom_tables = c("grid"), as_view = TRUE)# A tibble: 3 × 3
table rows has_geom
<chr> <dbl> <lgl>
1 cruise 691 FALSE
2 grid 218 TRUE
3 ship 48 FALSE d_ship <- dbGetQuery(con, "SELECT ship_key, ship_name, ship_nodc FROM ship") |>
mutate(ship_name_norm = ship_name |> str_to_upper() |> str_squish())
zt <- dbGetQuery(con, "SELECT tow_id, ship_name, date FROM zooplankton_tow") |>
mutate(ship_name_norm = ship_name |>
str_replace("^R/?V\\.?\\s+", "") |> str_to_upper() |> str_squish()) |>
left_join(d_ship |> select(ship_name_norm, ship_key, ship_nodc), by = "ship_name_norm") |>
mutate(cruise_key = if_else(
is.na(ship_nodc) | is.na(date), NA_character_,
as.character(glue("{format(date, '%Y-%m')}-{ship_nodc}"))))
valid_ck <- dbGetQuery(con, "SELECT DISTINCT cruise_key FROM cruise")$cruise_key
zt <- zt |> mutate(cruise_key = if_else(cruise_key %in% valid_ck, cruise_key, NA_character_))
# write resolved keys back
dbWriteTable(con, "zt_keys", zt |> select(tow_id, ship_key, cruise_key), overwrite = TRUE)
dbExecute(con, "ALTER TABLE zooplankton_tow ADD COLUMN IF NOT EXISTS ship_key VARCHAR")[1] 0dbExecute(con, "ALTER TABLE zooplankton_tow ADD COLUMN IF NOT EXISTS cruise_key VARCHAR")[1] 0dbExecute(con,
"UPDATE zooplankton_tow t SET ship_key = k.ship_key, cruise_key = k.cruise_key
FROM zt_keys k WHERE t.tow_id = k.tow_id")[1] 99530dbExecute(con, "DROP TABLE zt_keys")[1] 0cat(glue(
"ship match: {sum(!is.na(zt$ship_key))}/{nrow(zt)} ",
"({round(100*mean(!is.na(zt$ship_key)),1)}%); ",
"cruise_key match: {sum(!is.na(zt$cruise_key))}/{nrow(zt)} ",
"({round(100*mean(!is.na(zt$cruise_key)),1)}%)"), "\n")ship match: 85320/99530 (85.7%); cruise_key match: 66280/99530 (66.6%) add_point_geom(con, "zooplankton_tow", lon_col = "longitude", lat_col = "latitude")
assign_grid_key(con, "zooplankton_tow") |> datatable(caption = "Grid assignment")d_dataset <- ingest_yaml_to_dataset_df(read_ingest_yaml(here()))
dbWriteTable(con, "dataset", d_dataset, overwrite = TRUE)
cat(glue("dataset: {nrow(d_dataset)} datasets registered"), "\n")dataset: 12 datasets registered zoo_rels <- list(
primary_keys = list(zooplankton_tow = "tow_id"),
foreign_keys = list()) # cross-dataset FKs (cruise/ship/grid) in relationships_cross.csv
cc_erd(
con, tables = c("zooplankton_tow", "dataset"), rels = zoo_rels,
colors = list(lightblue = "zooplankton_tow", white = "dataset"))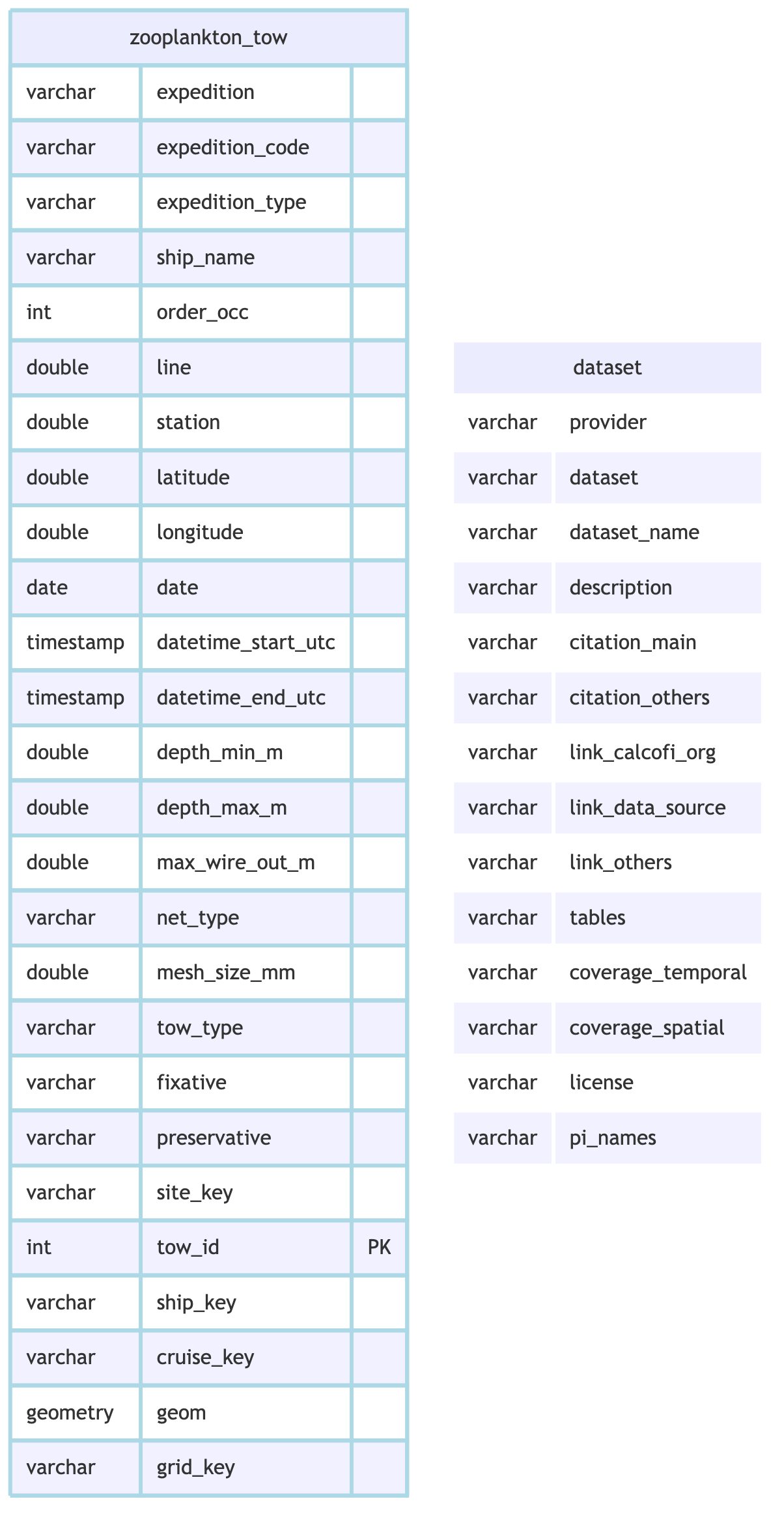
build_relationships_json(
rels = zoo_rels, output_dir = dir_parquet, provider = provider, dataset = dataset)[1] "/Users/bbest/Github/CalCOFI/workflows/data/parquet/pic_zooplankton/relationships.json"results <- validate_for_release(con, checks = "all", strict = FALSE)
cat("Validation:", ifelse(results$passed, "PASSED", "FAILED"), "\n")Validation: FAILED if (length(results$errors) > 0)
cat("Errors:\n", paste("-", results$errors, collapse = "\n"), "\n")Errors:
- Table 'zooplankton_tow' has 16000 NULL values in required column 'site_key'
- Table 'zooplankton_tow' has 14210 NULL values in required column 'ship_key'
- Table 'zooplankton_tow' has 33250 NULL values in required column 'cruise_key'
- Table 'zooplankton_tow' has 1334 NULL values in required column 'grid_key' # NULL cruise_key/ship_key/site_key are the expected unmatched remainder (Q03/Q05),
# the same accepted behavior as calcofi_dic; not a hard failure.
n_dup <- dbGetQuery(con,
"SELECT COUNT(*) FROM (SELECT tow_id, COUNT(*) n FROM zooplankton_tow GROUP BY tow_id HAVING COUNT(*)>1)")[[1]]
cat(glue("zooplankton_tow tow_id duplicates: {n_dup}"), "\n")zooplankton_tow tow_id duplicates: 0 cols <- dbGetQuery(con,
"SELECT column_name FROM information_schema.columns
WHERE table_name='zooplankton_tow' AND data_type NOT LIKE 'GEOMETRY%'")$column_name
dbGetQuery(con, glue("SELECT {paste(cols, collapse=', ')} FROM zooplankton_tow LIMIT 100")) |>
datatable(caption = "zooplankton_tow — first 100 rows", rownames = FALSE, filter = "top")Project this dataset into the shared consolidated core model (design_env-bio-consolidation.md) via calcofi4db::emit_core_tables() — the single source of truth for the per-dataset projection into sample / obs / obs_freq / sample_measurement, also used by release_database.qmd to assemble the authoritative cross-dataset release.
core <- emit_core_tables(con, "pic_zooplankton")
cat(glue(
"core projection — sample={core$sample %||% 0} obs={core$obs %||% 0} ",
"obs_freq={core$obs_freq %||% 0} sample_measurement={core$sample_measurement %||% 0}\n"))core projection — sample=99530 obs=0 obs_freq=0 sample_measurement=0# the frozen release assembles the authoritative cross-dataset core; keep this
# ingest's parquet output per-dataset by dropping the local core projection here.
for (tbl_core in c("obs", "obs_freq", "sample_measurement", "sample"))
dbExecute(con, glue("DROP TABLE IF EXISTS {tbl_core}"))dir_create(dir_parquet)
mismatches <- list(cruise_keys = collect_cruise_key_mismatches(con, "zooplankton_tow"))
parquet_stats <- write_parquet_outputs(
con = con, output_dir = dir_parquet,
tables = c("zooplankton_tow", "dataset"),
strip_provenance = FALSE, mismatches = mismatches)
parquet_stats |> mutate(file = basename(path)) |> select(-path) |>
datatable(caption = "Parquet export statistics")d_tbls_rd <- read_csv(here("metadata/pic/zooplankton/tbls_redefine.csv"))
d_flds_rd <- read_csv(here("metadata/pic/zooplankton/flds_redefine.csv"))
metadata_path <- build_metadata_json(
con = con, d_tbls_rd = d_tbls_rd, d_flds_rd = d_flds_rd,
metadata_derived_csv = here("metadata/pic/zooplankton/metadata_derived.csv"),
output_dir = dir_parquet, tables = c("zooplankton_tow"),
set_comments = TRUE, provider = provider, dataset = dataset,
workflow_url = cc$workflow_url, tables_owned = tables_owned)sync_to_gcs(local_dir = dir_parquet, gcs_prefix = glue("ingest/{dir_label}"), bucket = "calcofi-db")# A tibble: 5 × 4
file action size reason
<chr> <chr> <dbl> <chr>
1 dataset.parquet uploaded 8904 crc32c changed
2 manifest.json uploaded 1719 crc32c changed
3 metadata.json skipped 4985 checksum match
4 relationships.json skipped 158 checksum match
5 zooplankton_tow.parquet skipped 1632196 checksum matchFollow-up questions for SIO PIC (Rasmus Swalethorp, Ed Weber, Linsey Sala), ranked by importance. The headline blocker (Q01) is that biovolume is absent from the provided file, so only the tow registry is ingested here. Tracked in metadata/pic/zooplankton/questions.csv; aggregated by questions_email.qmd.
read_csv(here(glue("metadata/{provider}/{dataset}/questions.csv"))) |>
arrange(factor(priority, c("blocker", "high", "normal")), id) |>
select(priority, question, context, related_field, status) |>
datatable(caption = "Questions for data providers (ranked)",
options = list(dom = "t", pageLength = 20), rownames = FALSE)close_duckdb(con)
cat(glue("Parquet outputs written to: {dir_parquet}"), "\n")Parquet outputs written to: /Users/bbest/Github/CalCOFI/workflows/data/parquet/pic_zooplankton