Code
graph LR
A[data.csv<br/>10,150 tows] --> B[euphausiids_tow<br/>position + keys]
B --> C[euphausiids_measurement<br/>long format]
C --> D[euphausiids_summary<br/>avg/stddev]
B -.ship/cruise/grid.-> E[(shared refs)]Source: CCE-LTER euphausiid abundance time series (data.csv, ~1.2 MB, 10,150 tows, 1951–2019), curated by CCE-LTER (Rasmus Swalethorp, Linsey Sala) and published on EDI.
cce-lterAbundance measurementeuphausiids_tow position table; resolve ship_key, cruise_key, site_key, and grid_key against the shared reference tables; pivot Abundance into long-format euphausiids_measurement; summarize replicates into euphausiids_summary.This ingest proceeds with documented best-guess decisions for the open provider questions (units, taxonomic scope, coordinate/cruise/ship fixes); each decision is flagged inline and tracked, ranked by importance, in the Questions for Data Providers section at the end.
graph LR
A[data.csv<br/>10,150 tows] --> B[euphausiids_tow<br/>position + keys]
B --> C[euphausiids_measurement<br/>long format]
C --> D[euphausiids_summary<br/>avg/stddev]
B -.ship/cruise/grid.-> E[(shared refs)]devtools::load_all(here::here("../calcofi4db"))
devtools::load_all(here::here("../calcofi4r"))
librarian::shelf(
CalCOFI/calcofi4db, CalCOFI/calcofi4r,
DBI, dplyr, DT, fs, glue, here, htmltools, janitor, jsonlite, knitr,
lubridate, purrr, readr, sf, stringr, tibble, tidyr, units,
quiet = T)
options(readr.show_col_types = F)
options(DT.options = list(scrollX = TRUE))
# common ingest settings (overwrite, dir_data)
source(here("libs/ingest.R"))
# provider/dataset/metadata from this file's authoritative YAML block
cc <- read_calcofi_meta(here("ingest_cce-lter_euphausiids.qmd"))
provider <- cc$provider
dataset <- cc$dataset
dataset_name <- cc$dataset_meta$dataset_name
tables_owned <- cc$tables_owned
dir_label <- glue("{provider}_{dataset}")
dir_parquet <- here(glue("data/parquet/{dir_label}"))
db_path <- here(glue("data/wrangling/{dir_label}.duckdb"))
if (overwrite) {
if (file_exists(db_path)) file_delete(db_path)
if (file_exists(paste0(db_path, ".wal"))) file_delete(paste0(db_path, ".wal"))
if (dir_exists(paste0(db_path, ".tmp"))) dir_delete(paste0(db_path, ".tmp"))
}
dir_create(dirname(db_path))
con <- get_duckdb_con(db_path)
load_duckdb_extension(con, "spatial")
# load unified measurement_type reference
meas_type_csv <- here("metadata/measurement_type.csv")
d_meas_type <- read_csv(meas_type_csv)The source CSV currently lives at {dir_data}/euphausiids/data.csv (not under a cce-lter/ subdirectory), so it is read directly rather than via read_csv_files(). Source columns are renamed to canonical names per metadata/cce-lter/euphausiids/flds_redefine.csv.
euph_csv <- path_expand(glue("{dir_data}/euphausiids/data.csv"))
stopifnot("euphausiids data.csv not found" = file_exists(euph_csv))
# archive source to GCS for provenance
sync_to_gcs(
local_dir = path_dir(euph_csv),
gcs_prefix = glue("archive/{provider}/{dataset}"),
bucket = "calcofi-files-public",
exclude = c(".DS_Store", "*.tmp", "*.gdoc")) # .gdoc is a Drive stub# A tibble: 1 × 4
file action size reason
<chr> <chr> <dbl> <chr>
1 data.csv skipped 1264334 checksum matchd_raw <- read_csv(euph_csv)
cat(glue("Read {format(nrow(d_raw), big.mark=',')} rows, ",
"{ncol(d_raw)} columns from {basename(euph_csv)}"), "\n")Read 10,150 rows, 12 columns from data.csv Apply the documented data-quality decisions (each tied to a ranked provider question). Canonical field names follow metadata/field_dictionary.csv.
d_clean <- d_raw |>
transmute(
tow_id = as.integer(RowNumber),
cruise_orig = Cruise,
ship_name = Ship,
date = as.Date(Date),
line = suppressWarnings(as.numeric(Line)),
station = suppressWarnings(as.numeric(Station)),
region = Region,
datetime_start_utc = as_datetime(TowBegin), # Q07: assumed already UTC
datetime_end_utc = as_datetime(TowEnd),
latitude = as.numeric(Latitude),
longitude = as.numeric(Longitude),
abundance = as.numeric(Abundance)) |>
mutate(
# Q05: ~15 tows have positive longitudes (sign errors) -> flip to negative
longitude = if_else(longitude > 0, -longitude, longitude),
# Q05: one garbage coordinate (lat 87.25, far outside survey) -> drop coords
bad_coord = latitude > 51 | latitude < 20 | longitude < -135 | longitude > -105,
latitude = if_else(bad_coord, NA_real_, latitude),
longitude = if_else(bad_coord, NA_real_, longitude),
# Q06: one TowEnd in year 2371 (typo) -> null out-of-range tow-end times
datetime_end_utc = if_else(
year(datetime_end_utc) > 2025 | year(datetime_end_utc) < 1949,
as_datetime(NA), datetime_end_utc),
# canonical CalCOFI site_key "LLL.L SSS.S" from line + station
site_key = if_else(
is.na(line) | is.na(station), NA_character_,
sprintf("%05.1f %05.1f", line, station)))
cat(glue("Cleaned {nrow(d_clean)} tows; ",
"{sum(d_clean$bad_coord, na.rm=TRUE)} coordinate(s) nulled (Q05), ",
"{sum(is.na(d_clean$datetime_end_utc))} tow-end null (incl. Q06)"), "\n")Cleaned 10150 tows; 1 coordinate(s) nulled (Q05), 1 tow-end null (incl. Q06) Load shared reference tables, normalize the messy vessel names (Q04), resolve ship_key/ship_nodc, then derive cruise_key as {YYYY}-{MM}-{ship_nodc} (the CalCOFI natural-key form) and validate against the cruise table (Q03).
# shared reference tables from the ichthyo ingest
load_prior_tables(
con,
parquet_dir = here("data/parquet/swfsc_ichthyo"),
tables = c("ship", "cruise", "grid"),
geom_tables = c("grid"),
as_view = TRUE)# A tibble: 3 × 3
table rows has_geom
<chr> <dbl> <lgl>
1 cruise 691 FALSE
2 grid 218 TRUE
3 ship 48 FALSE d_ship <- dbGetQuery(con, "SELECT ship_key, ship_name, ship_nodc FROM ship") |>
mutate(ship_name_norm = ship_name |> str_to_upper() |> str_squish())
# normalize euphausiids vessel names (strip 'R/V ', collapse spaces, upper-case)
d_keys <- d_clean |>
mutate(
ship_name_norm = ship_name |>
str_replace("^R/?V\\.?\\s+", "") |> str_to_upper() |> str_squish()) |>
left_join(
d_ship |> select(ship_name_norm, ship_key, ship_nodc),
by = "ship_name_norm") |>
mutate(
# cruise_key = YYYY-MM-{ship_nodc} (NA when ship unresolved)
cruise_key = if_else(
is.na(ship_nodc), NA_character_,
glue("{format(date, '%Y-%m')}-{ship_nodc}") |> as.character()))
n_ship <- sum(!is.na(d_keys$ship_key))
# validate derived cruise_key exists in the cruise table
valid_ck <- dbGetQuery(con, "SELECT DISTINCT cruise_key FROM cruise")$cruise_key
d_keys <- d_keys |>
mutate(cruise_key = if_else(cruise_key %in% valid_ck, cruise_key, NA_character_))
n_cruise <- sum(!is.na(d_keys$cruise_key))
cat(glue(
"Ship match: {n_ship}/{nrow(d_keys)} ({round(100*n_ship/nrow(d_keys),1)}%); ",
"cruise_key match: {n_cruise}/{nrow(d_keys)} ",
"({round(100*n_cruise/nrow(d_keys),1)}%)"), "\n")Ship match: 9978/10150 (98.3%); cruise_key match: 8316/10150 (81.9%) # report unresolved ship names for the provider follow-up (Q04)
d_keys |> filter(is.na(ship_key)) |> count(ship_name, sort = TRUE) |>
datatable(caption = "Unresolved vessel names (Q04)")euphausiids_tow carries position, time, and FK columns only — the abundance measurement is pivoted out in the next step.
d_tow <- d_keys |>
transmute(
tow_id, cruise_key, ship_key, ship_name, cruise_orig,
site_key, line, station, region,
datetime_start_utc, datetime_end_utc,
latitude, longitude, abundance)
dbWriteTable(con, "euphausiids_tow_wide", d_tow, overwrite = TRUE)
# tidy tow table: drop the raw measurement column
dbExecute(con,
"CREATE OR REPLACE TABLE euphausiids_tow AS
SELECT tow_id, cruise_key, ship_key, ship_name, cruise_orig,
site_key, line, station, region,
datetime_start_utc, datetime_end_utc, latitude, longitude
FROM euphausiids_tow_wide")[1] 10150cat(glue("euphausiids_tow: {dbGetQuery(con,'SELECT COUNT(*) FROM euphausiids_tow')[[1]]} rows"), "\n")euphausiids_tow: 10150 rows add_point_geom(con, "euphausiids_tow", lon_col = "longitude", lat_col = "latitude")
grid_stats <- assign_grid_key(con, "euphausiids_tow")
grid_stats |> datatable(caption = "Grid assignment")A single measurement type, euphausiid_abundance. Q01 (units) and Q02 (taxonomic scope) are unresolved — registered provisionally and flagged.
dbExecute(con,
"CREATE OR REPLACE TABLE euphausiids_measurement AS
SELECT ROW_NUMBER() OVER (ORDER BY tow_id) AS euphausiids_measurement_id,
tow_id,
'euphausiid_abundance' AS measurement_type,
CAST(abundance AS DOUBLE) AS measurement_value,
NULL::VARCHAR AS measurement_qual
FROM euphausiids_tow_wide
WHERE abundance IS NOT NULL
AND NOT isnan(CAST(abundance AS DOUBLE))
AND isfinite(CAST(abundance AS DOUBLE))")[1] 10150dbExecute(con, "DROP TABLE euphausiids_tow_wide")[1] 0n_meas <- dbGetQuery(con, "SELECT COUNT(*) FROM euphausiids_measurement")[[1]]
cat(glue("euphausiids_measurement: {format(n_meas, big.mark=',')} rows"), "\n")euphausiids_measurement: 10,150 rows Aggregate replicate tows at each unique position (site + datetime + type) into mean and standard deviation, following the dic_summary/ctd_summary pattern.
dbExecute(con,
"CREATE OR REPLACE TABLE euphausiids_summary AS
SELECT
t.site_key, t.datetime_start_utc, t.latitude, t.longitude,
m.measurement_type,
AVG(m.measurement_value) AS avg,
CASE WHEN COUNT(*) = 1 THEN 0
ELSE COALESCE(STDDEV_SAMP(m.measurement_value), 0) END AS stddev,
COUNT(*) AS n_obs
FROM euphausiids_measurement m
JOIN euphausiids_tow t USING (tow_id)
WHERE NOT isnan(m.measurement_value) AND isfinite(m.measurement_value)
GROUP BY t.site_key, t.datetime_start_utc, t.latitude, t.longitude,
m.measurement_type")[1] 10145cat(glue("euphausiids_summary: {dbGetQuery(con,'SELECT COUNT(*) FROM euphausiids_summary')[[1]]} positions"), "\n")euphausiids_summary: 10145 positions euph_types <- tibble(
measurement_type = "euphausiid_abundance",
description = paste(
"Euphausiid (krill) abundance per net tow. PROVISIONAL: units and",
"taxonomic scope unconfirmed (see questions Q01, Q02)."),
units = "count/1000m3", # Q01: PROVISIONAL best guess
`_source_column` = "Abundance",
`_source_table` = "euphausiids_measurement",
`_source_datasets` = "cce-lter_euphausiids",
`_qual_column` = NA_character_,
`_prec_column` = NA_character_)
if (!"euphausiid_abundance" %in% d_meas_type$measurement_type) {
d_meas_type <- bind_rows(d_meas_type, euph_types)
write_csv(d_meas_type, meas_type_csv)
cat("Added measurement type: euphausiid_abundance (provisional units)\n")
} else {
cat("euphausiid_abundance already registered\n")
}euphausiid_abundance already registereddbWriteTable(con, "measurement_type", d_meas_type, overwrite = TRUE)d_dataset <- ingest_yaml_to_dataset_df(read_ingest_yaml(here()))
dbWriteTable(con, "dataset", d_dataset, overwrite = TRUE)
cat(glue("dataset: {nrow(d_dataset)} datasets registered"), "\n")dataset: 5 datasets registered euph_rels <- list(
primary_keys = list(
euphausiids_tow = "tow_id",
euphausiids_measurement = "euphausiids_measurement_id",
measurement_type = "measurement_type"),
foreign_keys = list(
list(table = "euphausiids_measurement", column = "tow_id",
ref_table = "euphausiids_tow", ref_column = "tow_id"),
list(table = "euphausiids_measurement", column = "measurement_type",
ref_table = "measurement_type", ref_column = "measurement_type")))
euph_tables <- c(
"euphausiids_tow", "euphausiids_measurement", "euphausiids_summary",
"measurement_type", "dataset")
cc_erd(
con, tables = euph_tables, rels = euph_rels,
colors = list(
lightblue = c("euphausiids_tow", "euphausiids_measurement", "euphausiids_summary"),
lightyellow = "measurement_type",
white = "dataset"))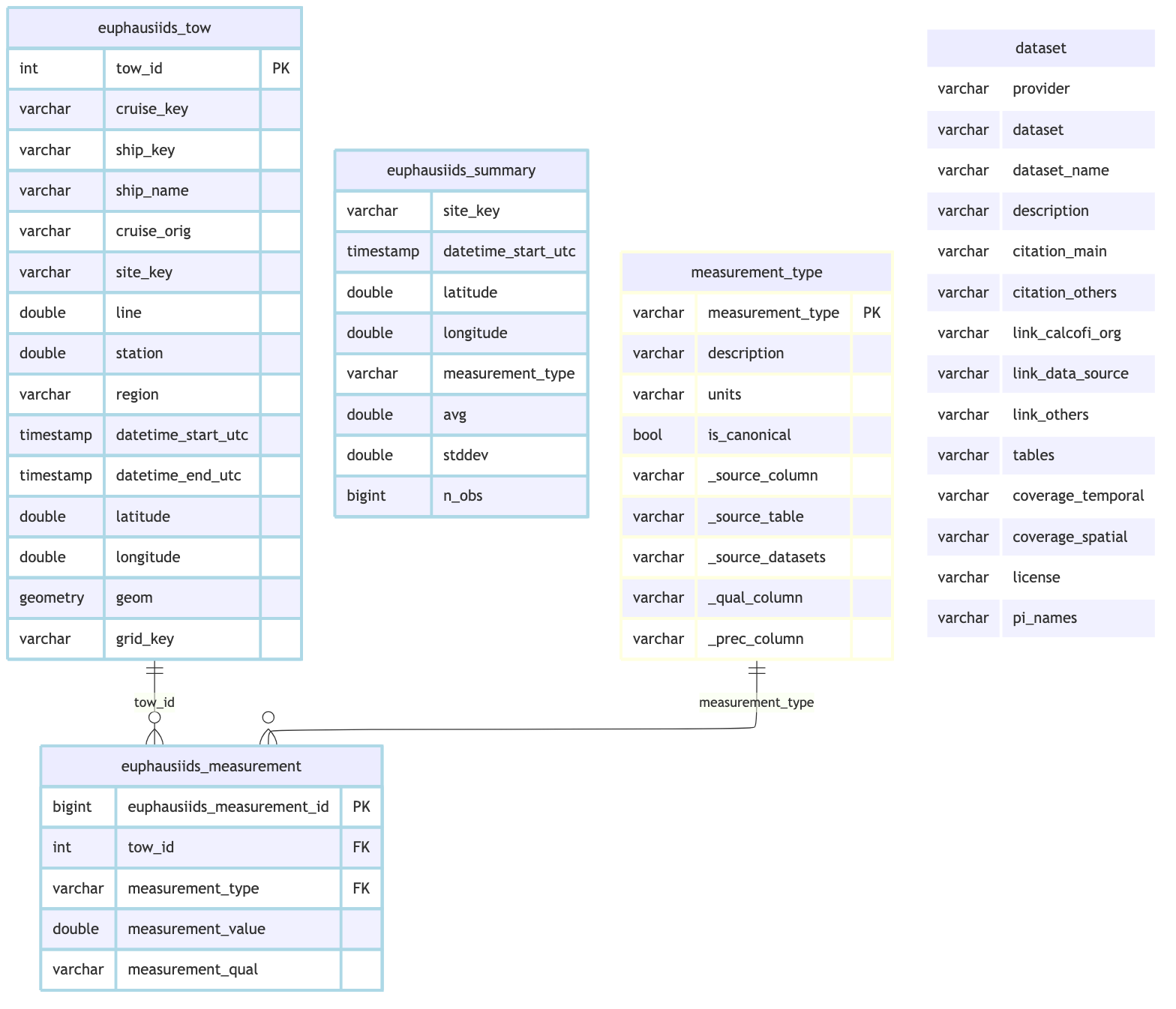
build_relationships_json(
rels = euph_rels, output_dir = dir_parquet,
provider = provider, dataset = dataset)[1] "/Users/bbest/Github/CalCOFI/workflows/data/parquet/cce-lter_euphausiids/relationships.json"results <- validate_for_release(con, checks = "all", strict = FALSE)
cat("Validation:", ifelse(results$passed, "PASSED", "FAILED"), "\n")Validation: FAILED if (length(results$errors) > 0)
cat("Errors:\n", paste("-", results$errors, collapse = "\n"), "\n")Errors:
- Table 'euphausiids_summary' has 30 NULL values in required column 'site_key'
- Table 'euphausiids_tow' has 1834 NULL values in required column 'cruise_key'
- Table 'euphausiids_tow' has 172 NULL values in required column 'ship_key'
- Table 'euphausiids_tow' has 34 NULL values in required column 'site_key'
- Table 'euphausiids_tow' has 10 NULL values in required column 'grid_key' if (length(results$warnings) > 0)
cat("Warnings:\n", paste("-", results$warnings, collapse = "\n"), "\n")Warnings:
- Missing expected tables: site, tow, net, larva, species # NOTE: NULLs in the cross-dataset FK keys (cruise_key, ship_key, site_key,
# grid_key) are the EXPECTED unmatched remainder of partial matching — the same
# accepted behavior as calcofi_dic's nullable cast_id/bottle_id (issue #47).
# They are tracked in questions Q03 (cruise) and Q04 (ship), not a hard failure.
cat(glue(
"\nMatch coverage (non-NULL): ",
"ship_key {round(100*dbGetQuery(con,\"SELECT AVG(CASE WHEN ship_key IS NOT NULL THEN 1 ELSE 0 END) FROM euphausiids_tow\")[[1]],1)}%, ",
"cruise_key {round(100*dbGetQuery(con,\"SELECT AVG(CASE WHEN cruise_key IS NOT NULL THEN 1 ELSE 0 END) FROM euphausiids_tow\")[[1]],1)}%, ",
"grid_key {round(100*dbGetQuery(con,\"SELECT AVG(CASE WHEN grid_key IS NOT NULL THEN 1 ELSE 0 END) FROM euphausiids_tow\")[[1]],1)}%"), "\n")Match coverage (non-NULL): ship_key 98.3%, cruise_key 81.9%, grid_key 99.9% # composite-key duplicate check
n_dup <- dbGetQuery(con,
"SELECT COUNT(*) FROM (
SELECT tow_id, COUNT(*) n FROM euphausiids_tow GROUP BY tow_id HAVING COUNT(*)>1)")[[1]]
cat(glue("euphausiids_tow tow_id duplicates: {n_dup}"), "\n")euphausiids_tow tow_id duplicates: 0 tow_cols <- dbGetQuery(con,
"SELECT column_name FROM information_schema.columns
WHERE table_name='euphausiids_tow' AND data_type NOT LIKE 'GEOMETRY%'")$column_name
dbGetQuery(con, glue("SELECT {paste(tow_cols, collapse=', ')} FROM euphausiids_tow LIMIT 100")) |>
datatable(caption = "euphausiids_tow — first 100 rows", rownames = FALSE, filter = "top")dbGetQuery(con, "SELECT * FROM euphausiids_measurement LIMIT 100") |>
datatable(caption = "euphausiids_measurement — first 100 rows", rownames = FALSE)dir_create(dir_parquet)
mismatches <- list(
measurement_types = collect_measurement_type_mismatches(
con, here("metadata/measurement_type.csv")),
cruise_keys = collect_cruise_key_mismatches(con, "euphausiids_tow"))
parquet_stats <- write_parquet_outputs(
con = con,
output_dir = dir_parquet,
tables = c("euphausiids_tow", "euphausiids_measurement",
"euphausiids_summary", "measurement_type", "dataset"),
sort_by = list(euphausiids_summary = "measurement_type"),
strip_provenance = FALSE,
mismatches = mismatches)
parquet_stats |> mutate(file = basename(path)) |> select(-path) |>
datatable(caption = "Parquet export statistics")d_tbls_rd <- read_csv(here("metadata/cce-lter/euphausiids/tbls_redefine.csv"))
d_flds_rd <- read_csv(here("metadata/cce-lter/euphausiids/flds_redefine.csv"))
metadata_path <- build_metadata_json(
con = con,
d_tbls_rd = d_tbls_rd,
d_flds_rd = d_flds_rd,
output_dir = dir_parquet,
tables = c("euphausiids_tow", "euphausiids_measurement", "euphausiids_summary"),
set_comments = TRUE,
provider = provider,
dataset = dataset,
workflow_url = cc$workflow_url,
tables_owned = tables_owned)sync_to_gcs(
local_dir = dir_parquet,
gcs_prefix = glue("ingest/{dir_label}"),
bucket = "calcofi-db")# A tibble: 8 × 4
file action size reason
<chr> <chr> <dbl> <chr>
1 dataset.parquet skipped 5396 checksum match
2 euphausiids_measurement.parquet skipped 69921 checksum match
3 euphausiids_summary.parquet skipped 181570 checksum match
4 euphausiids_tow.parquet skipped 191229 checksum match
5 manifest.json skipped 2610 checksum match
6 measurement_type.parquet skipped 4949 checksum match
7 metadata.json skipped 5316 checksum match
8 relationships.json skipped 587 checksum matchFollow-up questions for CCE-LTER (Rasmus Swalethorp, Linsey Sala), ranked by importance. This ingest proceeded with the documented provisional decisions noted above; blocker/high answers may change registered units, taxonomy, or matched rows on the next run. Tracked in metadata/cce-lter/euphausiids/questions.csv; aggregated per provider by questions_email.qmd.
q_path <- here(glue("metadata/{provider}/{dataset}/questions.csv"))
read_csv(q_path) |>
arrange(factor(priority, c("blocker", "high", "normal")), id) |>
select(priority, question, context, related_field, status) |>
datatable(
caption = "Questions for data providers (ranked by importance)",
options = list(dom = "t", pageLength = 20), rownames = FALSE)close_duckdb(con)
cat(glue("Parquet outputs written to: {dir_parquet}"), "\n")Parquet outputs written to: /Users/bbest/Github/CalCOFI/workflows/data/parquet/cce-lter_euphausiids devtools::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.5.2 (2025-10-31)
os macOS Sequoia 15.7.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Europe/Rome
date 2026-06-07
pandoc 3.8.3 @ /opt/homebrew/bin/ (via rmarkdown)
quarto 1.8.25 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
! package * version date (UTC) lib source
abind 1.4-8 2024-09-12 [1] CRAN (R 4.5.0)
arrow 24.0.0 2026-04-29 [1] CRAN (R 4.5.2)
assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.5.0)
backports 1.5.1 2026-04-03 [1] CRAN (R 4.5.2)
base64enc 0.1-6 2026-02-02 [1] CRAN (R 4.5.2)
bit 4.6.0 2025-03-06 [1] CRAN (R 4.5.0)
bit64 4.8.2 2026-05-19 [1] CRAN (R 4.5.2)
blob 1.3.0 2026-01-14 [1] CRAN (R 4.5.2)
broom 1.0.13 2026-05-14 [1] CRAN (R 4.5.2)
bslib 0.11.0 2026-05-16 [1] CRAN (R 4.5.2)
cachem 1.1.0 2024-05-16 [1] CRAN (R 4.5.0)
P calcofi4db * 2.8.2 2026-06-07 [?] load_all()
P calcofi4r * 1.3.0 2026-06-05 [?] load_all()
class 7.3-23 2025-01-01 [1] CRAN (R 4.5.2)
classInt 0.4-11 2025-01-08 [1] CRAN (R 4.5.0)
cli 3.6.6 2026-04-09 [1] CRAN (R 4.5.2)
codetools 0.2-20 2024-03-31 [1] CRAN (R 4.5.2)
crayon 1.5.3 2024-06-20 [1] CRAN (R 4.5.0)
crosstalk 1.2.2 2025-08-26 [1] CRAN (R 4.5.0)
curl 7.1.0 2026-04-22 [1] CRAN (R 4.5.2)
data.table 1.18.4 2026-05-06 [1] CRAN (R 4.5.2)
DBI * 1.3.0 2026-02-25 [1] CRAN (R 4.5.2)
dbplyr 2.5.2 2026-02-13 [1] CRAN (R 4.5.2)
desc 1.4.3 2023-12-10 [1] CRAN (R 4.5.0)
devtools 2.5.0 2026-03-14 [1] CRAN (R 4.5.2)
DiagrammeR 1.0.12 2026-04-27 [1] CRAN (R 4.5.2)
DiagrammeRsvg 0.1 2016-02-04 [1] CRAN (R 4.5.0)
digest 0.6.39 2025-11-19 [1] CRAN (R 4.5.2)
dm 1.1.2 2026-05-17 [1] CRAN (R 4.5.2)
dplyr * 1.2.1 2026-04-03 [1] CRAN (R 4.5.2)
DT * 0.34.0 2025-09-02 [1] CRAN (R 4.5.0)
duckdb 1.5.2 2026-04-13 [1] CRAN (R 4.5.2)
dygraphs 1.1.1.6 2018-07-11 [1] CRAN (R 4.5.0)
e1071 1.7-17 2025-12-18 [1] CRAN (R 4.5.2)
ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.5.0)
evaluate 1.0.5 2025-08-27 [1] CRAN (R 4.5.0)
farver 2.1.2 2024-05-13 [1] CRAN (R 4.5.0)
fastmap 1.2.0 2024-05-15 [1] CRAN (R 4.5.0)
fs * 2.1.0 2026-04-18 [1] CRAN (R 4.5.2)
fuzzyjoin 0.1.8 2026-02-20 [1] CRAN (R 4.5.2)
gargle 1.6.1 2026-01-29 [1] CRAN (R 4.5.2)
generics 0.1.4 2025-05-09 [1] CRAN (R 4.5.0)
geojsonsf 2.0.5 2025-11-26 [1] CRAN (R 4.5.2)
ggplot2 4.0.3 2026-04-22 [1] CRAN (R 4.5.2)
glue * 1.8.1 2026-04-17 [1] CRAN (R 4.5.2)
googledrive 2.1.2 2025-09-10 [1] CRAN (R 4.5.0)
gtable 0.3.6 2024-10-25 [1] CRAN (R 4.5.0)
here * 1.0.2 2025-09-15 [1] CRAN (R 4.5.0)
highcharter 0.9.5 2026-04-22 [1] CRAN (R 4.5.2)
hms 1.1.4 2025-10-17 [1] CRAN (R 4.5.0)
htmltools * 0.5.9 2025-12-04 [1] CRAN (R 4.5.2)
htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.5.0)
httpuv 1.6.17 2026-03-18 [1] CRAN (R 4.5.2)
httr 1.4.8 2026-02-13 [1] CRAN (R 4.5.2)
httr2 1.2.2 2025-12-08 [1] CRAN (R 4.5.2)
igraph 2.3.2 2026-05-29 [1] CRAN (R 4.5.2)
isoband 0.3.0 2025-12-07 [1] CRAN (R 4.5.2)
janitor * 2.2.1 2024-12-22 [1] CRAN (R 4.5.0)
jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.5.0)
jsonlite * 2.0.0 2025-03-27 [1] CRAN (R 4.5.0)
KernSmooth 2.23-26 2025-01-01 [1] CRAN (R 4.5.2)
knitr * 1.51 2025-12-20 [1] CRAN (R 4.5.2)
later 1.4.8 2026-03-05 [1] CRAN (R 4.5.2)
lattice 0.22-9 2026-02-09 [1] CRAN (R 4.5.2)
lazyeval 0.2.3 2026-04-04 [1] CRAN (R 4.5.2)
leafem 0.2.5 2025-08-28 [1] CRAN (R 4.5.0)
leaflet 2.2.3 2025-09-04 [1] CRAN (R 4.5.0)
librarian 1.8.1 2021-07-12 [1] CRAN (R 4.5.0)
lifecycle 1.0.5 2026-01-08 [1] CRAN (R 4.5.2)
lubridate * 1.9.5 2026-02-04 [1] CRAN (R 4.5.2)
magrittr 2.0.5 2026-04-04 [1] CRAN (R 4.5.2)
mapgl 0.4.6 2026-06-05 [1] Github (bbest/mapgl@0b70b3f)
mapview 2.11.4 2025-09-08 [1] CRAN (R 4.5.0)
markdown 2.0 2025-03-23 [1] CRAN (R 4.5.0)
Matrix 1.7-5 2026-03-21 [1] CRAN (R 4.5.2)
memoise 2.0.1 2021-11-26 [1] CRAN (R 4.5.0)
mgcv 1.9-4 2025-11-07 [1] CRAN (R 4.5.0)
mime 0.13 2025-03-17 [1] CRAN (R 4.5.0)
nlme 3.1-169 2026-03-27 [1] CRAN (R 4.5.2)
otel 0.2.0 2025-08-29 [1] CRAN (R 4.5.0)
pillar 1.11.1 2025-09-17 [1] CRAN (R 4.5.0)
pkgbuild 1.4.8 2025-05-26 [1] CRAN (R 4.5.0)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.5.0)
pkgload 1.5.1 2026-04-01 [1] CRAN (R 4.5.2)
plotly 4.12.0 2026-01-24 [1] CRAN (R 4.5.2)
png 0.1-9 2026-03-15 [1] CRAN (R 4.5.2)
promises 1.5.0 2025-11-01 [1] CRAN (R 4.5.0)
proxy 0.4-29 2025-12-29 [1] CRAN (R 4.5.2)
purrr * 1.2.2 2026-04-10 [1] CRAN (R 4.5.2)
quantmod 0.4.28 2025-06-19 [1] CRAN (R 4.5.0)
R6 2.6.1 2025-02-15 [1] CRAN (R 4.5.0)
rappdirs 0.3.4 2026-01-17 [1] CRAN (R 4.5.2)
raster 3.6-32 2025-03-28 [1] CRAN (R 4.5.0)
RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.5.0)
Rcpp 1.1.1-1.1 2026-04-24 [1] CRAN (R 4.5.2)
readr * 2.2.0 2026-02-19 [1] CRAN (R 4.5.2)
rlang 1.2.0 2026-04-06 [1] CRAN (R 4.5.2)
rlist 0.4.6.2 2021-09-03 [1] CRAN (R 4.5.0)
rmarkdown 2.31 2026-03-26 [1] CRAN (R 4.5.2)
rnaturalearth 1.2.0 2026-01-19 [1] CRAN (R 4.5.2)
rnaturalearthhires 1.0.0.9000 2025-10-02 [1] Github (ropensci/rnaturalearthhires@e4736f6)
RPostgres 1.4.10 2026-02-16 [1] CRAN (R 4.5.2)
rprojroot 2.1.1 2025-08-26 [1] CRAN (R 4.5.0)
rstudioapi 0.18.0 2026-01-16 [1] CRAN (R 4.5.2)
S7 0.2.2 2026-04-22 [1] CRAN (R 4.5.2)
sass 0.4.10 2025-04-11 [1] CRAN (R 4.5.0)
satellite 1.0.6 2025-08-21 [1] CRAN (R 4.5.0)
scales 1.4.0 2025-04-24 [1] CRAN (R 4.5.0)
sessioninfo 1.2.3 2025-02-05 [1] CRAN (R 4.5.0)
sf * 1.1-1 2026-05-06 [1] CRAN (R 4.5.2)
shiny 1.13.0 2026-02-20 [1] CRAN (R 4.5.2)
shinyWidgets 0.9.1 2026-03-09 [1] CRAN (R 4.5.2)
snakecase 0.11.1 2023-08-27 [1] CRAN (R 4.5.0)
sp 2.2-1 2026-02-13 [1] CRAN (R 4.5.2)
stars 0.7-2 2026-04-03 [1] CRAN (R 4.5.2)
stringi 1.8.7 2025-03-27 [1] CRAN (R 4.5.0)
stringr * 1.6.0 2025-11-04 [1] CRAN (R 4.5.0)
terra 1.9-27 2026-05-10 [1] CRAN (R 4.5.2)
tibble * 3.3.1 2026-01-11 [1] CRAN (R 4.5.2)
tidyr * 1.3.2 2025-12-19 [1] CRAN (R 4.5.2)
tidyselect 1.2.1 2024-03-11 [1] CRAN (R 4.5.0)
timechange 0.4.0 2026-01-29 [1] CRAN (R 4.5.2)
TTR 0.24.4 2023-11-28 [1] CRAN (R 4.5.0)
tzdb 0.5.0 2025-03-15 [1] CRAN (R 4.5.0)
units * 1.0-1 2026-03-11 [1] CRAN (R 4.5.2)
usethis 3.2.1 2025-09-06 [1] CRAN (R 4.5.0)
utf8 1.2.6 2025-06-08 [1] CRAN (R 4.5.0)
uuid 1.2-2 2026-01-23 [1] CRAN (R 4.5.2)
V8 8.2.0 2026-04-21 [1] CRAN (R 4.5.2)
vctrs 0.7.3 2026-04-11 [1] CRAN (R 4.5.2)
viridisLite 0.4.3 2026-02-04 [1] CRAN (R 4.5.2)
visNetwork 2.1.4 2025-09-04 [1] CRAN (R 4.5.0)
vroom 1.7.1 2026-03-31 [1] CRAN (R 4.5.2)
withr 3.0.2 2024-10-28 [1] CRAN (R 4.5.0)
xfun 0.58 2026-06-01 [1] CRAN (R 4.5.2)
xtable 1.8-8 2026-02-22 [1] CRAN (R 4.5.2)
xts 0.14.2 2026-02-28 [1] CRAN (R 4.5.2)
yaml 2.3.12 2025-12-10 [1] CRAN (R 4.5.2)
zoo 1.8-15 2025-12-15 [1] CRAN (R 4.5.2)
[1] /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library
* ── Packages attached to the search path.
P ── Loaded and on-disk path mismatch.
──────────────────────────────────────────────────────────────────────────────