---
title: "Ingest CalCOFI Phytoplankton (Venrick)"
calcofi:
target_name: ingest_calcofi_phytoplankton
workflow_type: ingest
dependency:
- ingest_swfsc_ichthyo
output: data/parquet/calcofi_phytoplankton/manifest.json
provider: calcofi
dataset: phytoplankton
workflow_url: https://calcofi.io/workflows/ingest_calcofi_phytoplankton.html
questions_file: metadata/calcofi/phytoplankton/questions.csv
dataset_meta:
dataset_name: CalCOFI Phytoplankton (Venrick)
description: >
Abundance and species composition of phytoplankton (385 taxonomic
categories) in the California Current, 1996-2022, by inverted-microscope
counts (E. Venrick). Samples from the near-surface "second depth" are
pooled across stations into four regions (NE, SE, Alley, Offshore;
Hayward & Venrick 1998) before counting, so the grain is cruise x region,
not per-station. Source: EDI knb-lter-cce.254.4.
citation_main: ""
link_calcofi_org: "https://calcofi.org/data/marine-ecosystem-data/phytoplankton-bacterioplankton/"
link_data_source: "https://portal.edirepository.org/nis/mapbrowse?packageid=knb-lter-cce.254.4"
link_others: []
coverage_temporal: 1996 to 2022
coverage_spatial: "CalCOFI region (4 pooled sub-regions)"
license: ""
pi_names: Elizabeth L. Venrick
tables_owned:
- {table: phyto_sample}
- {table: phyto_measurement}
- {table: phyto_taxon}
- {table: region}
- {table: measurement_type, shared: true}
erd:
color: "#b5e8b0"
editor_options:
chunk_output_type: console
---
## Overview
**Source**: EDI [`knb-lter-cce.254.4`](https://portal.edirepository.org/nis/mapbrowse?packageid=knb-lter-cce.254.4)
— *Temporal and spatial changes of the abundance and species composition of
phytoplankton in the California Current* (E. Venrick + CalCOFI + CCE-LTER,
1996-2022). Provider `calcofi`.
**Grain note**: samples are **pooled across stations into 4 regions** before
counting, so there is no per-station `site_key`. We model the native grain —
`phyto_sample` = one row per (cruise × region) — link to the cruise registry by
year-month (`cruise_key`), and place each region at a **provisional centroid**
of its member CalCOFI stations (see Questions Q01).
## Setup
```{r}
#| label: setup
#| message: false
devtools::load_all(here::here("../calcofi4db"))
devtools::load_all(here::here("../calcofi4r"))
librarian::shelf(
CalCOFI/calcofi4db, CalCOFI/calcofi4r,
DBI, dplyr, DT, fs, glue, here, janitor, jsonlite, knitr, lubridate, purrr,
readr, sf, stringr, tibble, tidyr, units, quiet = T)
options(readr.show_col_types = F); options(DT.options = list(scrollX = TRUE))
source(here("libs/ingest.R"))
source(here("libs/parse_phytoplankton.R"))
cc <- read_calcofi_meta(here("ingest_calcofi_phytoplankton.qmd"))
provider <- cc$provider; dataset <- cc$dataset; tables_owned <- cc$tables_owned
dir_label <- glue("{provider}_{dataset}")
dir_parquet <- here(glue("data/parquet/{dir_label}"))
db_path <- here(glue("data/wrangling/{dir_label}.duckdb"))
if (overwrite && file_exists(db_path)) file_delete(db_path)
dir_create(dirname(db_path)); con <- get_duckdb_con(db_path); load_duckdb_extension(con, "spatial")
meas_type_csv <- here("metadata/measurement_type.csv"); d_meas_type <- read_csv(meas_type_csv)
```
## Download from EDI
```{r}
#| label: download
dir_dl <- here(glue("data/cache/{dir_label}")); dir_create(dir_dl)
edi_base <- "https://pasta.lternet.edu/package/data/eml/knb-lter-cce/254/4"
edi_ents <- c(
abund_1996_2012 = "f2c2349b1b8f3f743913ddcf9b39339c",
abund_2012_2018 = "d59e83016505f8a802df8519ca6eba06",
abund_2019_2022 = "e683e945180ea0e5093aebe88f3d5c76",
definitions = "97d8f56bf41502f60ca6fdd5d5da8edc")
for (nm in names(edi_ents)) {
f <- file.path(dir_dl, paste0(nm, ".xlsx"))
if (overwrite || !file_exists(f)) download.file(paste0(edi_base, "/", edi_ents[[nm]]), f, quiet = TRUE)
}
cat(glue("Downloaded {length(edi_ents)} EDI entities to {dir_dl}"), "\n")
sync_to_gcs(local_dir = dir_dl, gcs_prefix = glue("archive/{provider}/{dataset}"),
bucket = "calcofi-files-public", exclude = c(".DS_Store"))
```
## Parse + Clean
The per-year sheets are taxon × (cruise × region) cross-tabs with merged 2-row
headers; `parse_phyto_workbooks()` (in `libs/parse_phytoplankton.R`) flattens
them to long form. We then drop stray file-path cells and separate the
group-`SUM` rows (derivable from the taxa, excluded per Q03).
```{r}
#| label: parse
abund_files <- file.path(dir_dl, c("abund_1996_2012.xlsx","abund_2012_2018.xlsx","abund_2019_2022.xlsx"))
d_long <- parse_phyto_workbooks(abund_files) |> mutate(species_code = str_trim(species_code))
d_long <- d_long |> mutate(
is_path = str_detect(species_code, "^[a-zA-Z]:\\\\|forweb"),
is_sum = str_detect(str_to_upper(species_code), "^SUM"),
is_num = str_detect(species_code, "^[0-9]+$"))
d_taxa_long <- d_long |> filter(is_num)
cat(glue("parsed {nrow(d_long)} rows: {sum(d_long$is_path)} path-junk dropped, ",
"{sum(d_long$is_sum)} group-SUM excluded, {nrow(d_taxa_long)} taxon-level kept"), "\n")
```
## Build Region (provisional centroids)
```{r}
#| label: region
reg_defs <- tribble(~region_key, ~description, ~station_codes,
"NE","Northern Inshore","83.41,83.51,87.40,90.30,90.37",
"SE","Southern Inshore","93.30,93.40,93.50,93.60",
"Alley","California Current","77.51,77.60,77.70,80.51,80.60,80.70,83.60,87.50,87.60,90.53",
"Offshore","Central Pacific","77.80,80.80,83.70,83.80,83.90,87.70,87.80,87.90,90.60,90.70,90.80,90.90,93.70,93.80,93.90")
st <- calcofi4r::stations |> sf::st_drop_geometry() |>
transmute(line = sta_id_line, sta = sta_id_station, lon, lat, line_r = round(sta_id_line))
match_one <- function(li, si) {
cand <- st |> filter(line_r == li)
if (!nrow(cand)) return(tibble(lon = NA_real_, lat = NA_real_))
cand |> slice_min(abs(sta - si), n = 1, with_ties = FALSE) |> select(lon, lat)
}
reg_sta <- reg_defs |>
mutate(code = str_split(station_codes, ",")) |> select(region_key, code) |> unnest(code) |>
mutate(line_i = as.integer(str_extract(code, "^[0-9]+")),
sta_i = as.integer(str_extract(code, "[0-9]+$")))
reg_sta <- reg_sta |> bind_cols(map2_dfr(reg_sta$line_i, reg_sta$sta_i, match_one))
region <- reg_defs |>
left_join(
reg_sta |> group_by(region_key) |>
summarize(n_stations = n(), latitude = mean(lat, na.rm = T),
longitude = mean(lon, na.rm = T), .groups = "drop"),
by = "region_key") |>
select(region_key, description, latitude, longitude, n_stations, station_codes)
dbWriteTable(con, "region", region, overwrite = TRUE)
datatable(region, caption = "Pooled regions + provisional centroids")
```
## Build Sample (cruise × region) + cruise_key match
```{r}
#| label: sample
# cruise registry (year-month -> cruise_key, unique months only)
load_prior_tables(con, parquet_dir = here("data/parquet/swfsc_ichthyo"),
tables = c("cruise","ship","grid"), geom_tables = c("grid"), as_view = TRUE)
cr <- dbGetQuery(con, "SELECT cruise_key, date_ym FROM cruise") |>
mutate(ym = format(as.Date(date_ym), "%Y%m"))
ck <- cr |> group_by(ym) |>
summarize(cruise_key = if (n() == 1) cruise_key[1] else NA_character_, .groups = "drop")
phyto_sample <- d_taxa_long |>
distinct(cruise_yymm, year, month, region_key = region) |>
mutate(ym = sprintf("%04d%02d", year, month)) |>
left_join(ck, by = "ym") |>
left_join(region |> select(region_key, latitude, longitude), by = "region_key") |>
arrange(year, month, region_key) |>
transmute(
phyto_sample_id = row_number(),
cruise_yymm, cruise_key, year, month,
season = recode(as.integer(month), `1`="winter",`2`="winter",`3`="spring",`4`="spring",
`5`="spring",`6`="summer",`7`="summer",`8`="summer",`9`="fall",
`10`="fall",`11`="fall",`12`="winter", .default = NA_character_),
region_key, latitude, longitude)
dbWriteTable(con, "phyto_sample", phyto_sample, overwrite = TRUE)
add_point_geom(con, "phyto_sample", lon_col = "longitude", lat_col = "latitude")
cat(glue("phyto_sample {nrow(phyto_sample)} (4 regions x {n_distinct(phyto_sample$cruise_yymm)} cruises); ",
"cruise_key matched {sum(!is.na(phyto_sample$cruise_key))}/{nrow(phyto_sample)} (Q06)"), "\n")
```
## Build Taxon (verbatim + WoRMS) + Measurement
```{r}
#| label: taxon-measurement
# WoRMS aphia_ids resolved + cached in metadata/.../taxon_worms.csv (Q05)
worms <- read_csv(here("metadata/calcofi/phytoplankton/taxon_worms.csv")) |>
mutate(species_code = as.character(species_code))
phyto_taxon <- worms |>
transmute(species_code, taxa, species,
aphia_id = as.integer(aphia_id), scientific_name_accepted, rank, kingdom, phylum)
# codes present in the abundance data but absent from the Definitions sheet (Q05):
# add placeholder rows so phyto_measurement.species_code has a complete FK.
missing_codes <- setdiff(unique(d_taxa_long$species_code), phyto_taxon$species_code)
if (length(missing_codes) > 0)
phyto_taxon <- bind_rows(phyto_taxon, tibble(
species_code = missing_codes, taxa = "undefined (code not in source definitions; Q05)",
species = NA_character_, aphia_id = NA_integer_, scientific_name_accepted = NA_character_,
rank = NA_character_, kingdom = NA_character_, phylum = NA_character_))
dbWriteTable(con, "phyto_taxon", phyto_taxon, overwrite = TRUE)
phyto_measurement <- d_taxa_long |>
inner_join(phyto_sample |> select(phyto_sample_id, cruise_yymm, region_key),
by = c("cruise_yymm", "region" = "region_key")) |>
filter(!is.na(abundance)) |>
transmute(phyto_sample_id, species_code,
measurement_type = "phytoplankton_abundance", measurement_value = abundance) |>
mutate(phyto_measurement_id = row_number(), .before = 1)
dbWriteTable(con, "phyto_measurement", phyto_measurement, overwrite = TRUE)
cat(glue("phyto_taxon {nrow(phyto_taxon)} ({sum(!is.na(phyto_taxon$aphia_id))} WoRMS-matched); ",
"phyto_measurement {nrow(phyto_measurement)}"), "\n")
```
## Measurement Types + Finalize
```{r}
#| label: finalize
phyto_types <- tibble(
measurement_type = "phytoplankton_abundance",
description = "Phytoplankton abundance by inverted-microscope count (cells/L)",
units = "cells/L", `_source_column` = "abundance", `_source_table` = "phyto_measurement",
`_source_datasets` = "calcofi_phytoplankton", `_qual_column` = NA_character_, `_prec_column` = NA_character_)
new_types <- phyto_types |> filter(!measurement_type %in% d_meas_type$measurement_type)
if (nrow(new_types) > 0) { d_meas_type <- bind_rows(d_meas_type, new_types); write_csv(d_meas_type, meas_type_csv) }
dbWriteTable(con, "measurement_type", d_meas_type, overwrite = TRUE)
d_dataset <- ingest_yaml_to_dataset_df(read_ingest_yaml(here()))
dbWriteTable(con, "dataset", d_dataset, overwrite = TRUE)
phyto_rels <- list(
primary_keys = list(phyto_sample = "phyto_sample_id", phyto_measurement = "phyto_measurement_id",
phyto_taxon = "species_code", region = "region_key",
measurement_type = "measurement_type"),
foreign_keys = list(
list(table="phyto_sample", column="region_key", ref_table="region", ref_column="region_key"),
list(table="phyto_measurement", column="phyto_sample_id", ref_table="phyto_sample", ref_column="phyto_sample_id"),
list(table="phyto_measurement", column="species_code", ref_table="phyto_taxon", ref_column="species_code"),
list(table="phyto_measurement", column="measurement_type", ref_table="measurement_type", ref_column="measurement_type")))
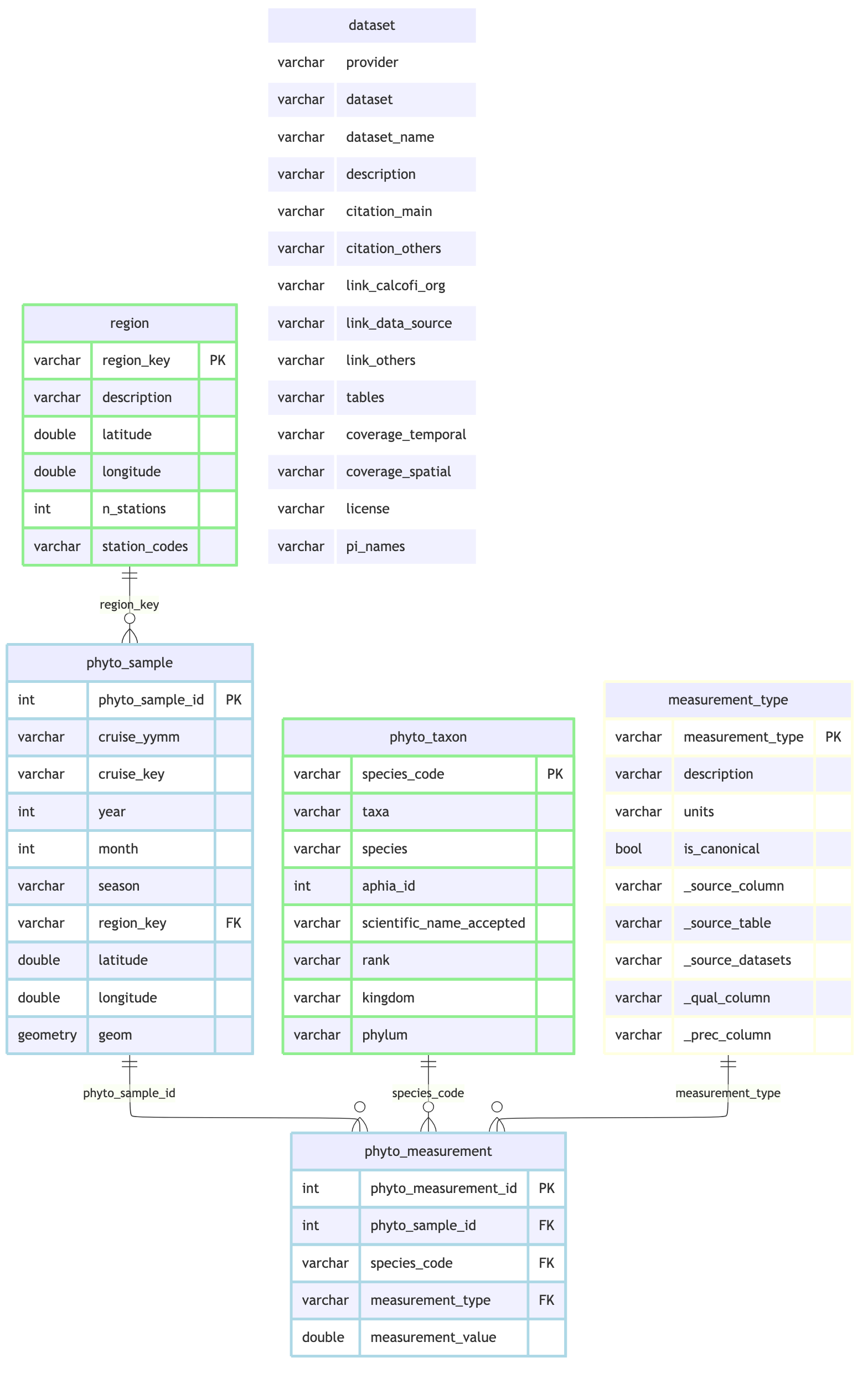
cc_erd(con, tables = c("phyto_sample","phyto_measurement","phyto_taxon","region","measurement_type","dataset"),
rels = phyto_rels,
colors = list(lightblue = c("phyto_sample","phyto_measurement"),
lightgreen = c("phyto_taxon","region"),
lightyellow = "measurement_type", white = "dataset"))
build_relationships_json(rels = phyto_rels, output_dir = dir_parquet, provider = provider, dataset = dataset)
results <- validate_for_release(con, checks = "all", strict = FALSE)
cat("Validation:", ifelse(results$passed, "PASSED", "FAILED"), "\n")
dir_create(dir_parquet)
write_parquet_outputs(con = con, output_dir = dir_parquet,
tables = c("phyto_sample","phyto_measurement","phyto_taxon","region","measurement_type","dataset"),
sort_by = list(phyto_measurement = "phyto_sample_id"), strip_provenance = FALSE)
d_tbls_rd <- read_csv(here("metadata/calcofi/phytoplankton/tbls_redefine.csv"))
d_flds_rd <- read_csv(here("metadata/calcofi/phytoplankton/flds_redefine.csv"))
build_metadata_json(con = con, d_tbls_rd = d_tbls_rd, d_flds_rd = d_flds_rd,
metadata_derived_csv = here("metadata/calcofi/phytoplankton/metadata_derived.csv"),
output_dir = dir_parquet, tables = c("phyto_sample","phyto_measurement","phyto_taxon","region"),
set_comments = TRUE, provider = provider, dataset = dataset,
workflow_url = cc$workflow_url, tables_owned = tables_owned)
sync_to_gcs(local_dir = dir_parquet, gcs_prefix = glue("ingest/{dir_label}"), bucket = "calcofi-db")
```
## Questions for Data Providers
```{r}
#| label: provider-questions
read_csv(here(glue("metadata/{provider}/{dataset}/questions.csv"))) |>
arrange(factor(priority, c("blocker","high","normal")), id) |>
select(priority, question, context, status) |>
datatable(caption = "Questions (ranked)", options = list(dom = "t"), rownames = FALSE)
```
```{r}
#| label: cleanup
close_duckdb(con); cat(glue("Parquet outputs written to: {dir_parquet}"), "\n")
```