---
title: "Ingest CalCOFI Lobster Phyllosoma"
calcofi:
target_name: ingest_calcofi_phyllosoma
workflow_type: ingest
dependency:
- ingest_swfsc_ichthyo
output: data/parquet/calcofi_phyllosoma/manifest.json
provider: calcofi
dataset: phyllosoma
workflow_url: https://calcofi.io/workflows/ingest_calcofi_phyllosoma.html
questions_file: metadata/calcofi/phyllosoma/questions.csv
dataset_meta:
dataset_name: CalCOFI Lobster Phyllosoma
description: >
Spiny lobster (Panulirus interruptus) phyllosoma larvae counts by
developmental stage from CalCOFI net tows, 1951-2008. Source: EDI
knb-lter-cce.188.4 (Koslow).
citation_main: ""
link_calcofi_org: ""
link_data_source: "https://portal.edirepository.org/nis/mapbrowse?packageid=knb-lter-cce.188.4"
link_others: []
coverage_temporal: 1951 to 2008
coverage_spatial: "CalCOFI region"
license: ""
pi_names: J. Anthony Koslow
tables_owned:
- {table: phyllosoma_tow}
- {table: phyllosoma_measurement}
- {table: measurement_type, shared: true}
erd:
color: "#e0bbf0"
editor_options:
chunk_output_type: console
---
## Overview
**Source**: EDI [`knb-lter-cce.188.4`](https://portal.edirepository.org/nis/mapbrowse?packageid=knb-lter-cce.188.4)
— spiny lobster (*Panulirus interruptus*) phyllosoma larvae counts by stage,
CalCOFI net tows 1951-2008 (PI Koslow). Provider `calcofi`.
## Setup
```{r}
#| label: setup
#| message: false
devtools::load_all(here::here("../calcofi4db"))
devtools::load_all(here::here("../calcofi4r"))
librarian::shelf(
CalCOFI/calcofi4db, CalCOFI/calcofi4r,
DBI, dplyr, DT, fs, glue, here, janitor, jsonlite, knitr, lubridate, purrr,
readr, sf, stringr, tibble, tidyr, units, quiet = T)
options(readr.show_col_types = F); options(DT.options = list(scrollX = TRUE))
source(here("libs/ingest.R"))
cc <- read_calcofi_meta(here("ingest_calcofi_phyllosoma.qmd"))
provider <- cc$provider; dataset <- cc$dataset; tables_owned <- cc$tables_owned
dir_label <- glue("{provider}_{dataset}")
dir_parquet <- here(glue("data/parquet/{dir_label}")); db_path <- here(glue("data/wrangling/{dir_label}.duckdb"))
if (overwrite && file_exists(db_path)) file_delete(db_path)
dir_create(dirname(db_path)); con <- get_duckdb_con(db_path); load_duckdb_extension(con, "spatial")
meas_type_csv <- here("metadata/measurement_type.csv"); d_meas_type <- read_csv(meas_type_csv)
```
## Download from EDI
```{r}
#| label: download
dir_dl <- here(glue("data/cache/{dir_label}")); dir_create(dir_dl)
phyllo_csv <- file.path(dir_dl, "phyllosoma.csv")
edi_url <- "https://pasta.lternet.edu/package/data/eml/knb-lter-cce/188/4/2e66465fa17f78cdc15a2bfc9dce652d"
if (overwrite || !file_exists(phyllo_csv)) download.file(edi_url, phyllo_csv, quiet = TRUE)
d_raw <- read_csv(phyllo_csv, col_types = cols(.default = "c")) |> clean_names()
cat(glue("Downloaded {nrow(d_raw)} phyllosoma tows"), "\n")
sync_to_gcs(local_dir = dir_dl, gcs_prefix = glue("archive/{provider}/{dataset}"),
bucket = "calcofi-files-public", exclude = c(".DS_Store"))
```
## Build Tow + Measurement Tables
```{r}
#| label: build
d <- d_raw |>
mutate(tow_id = row_number(), .before = 1) |>
mutate(
date = suppressWarnings(as.Date(tow_collection_day)),
latitude = suppressWarnings(as.numeric(latitude_o)),
longitude = suppressWarnings(as.numeric(longitude_o)),
line = suppressWarnings(as.numeric(station_line)),
station = suppressWarnings(as.numeric(station_number)),
site_key = if_else(is.na(line)|is.na(station), NA_character_, sprintf("%05.1f %05.1f", line, station)),
datetime_start_utc = as_datetime(date))
d_tow <- d |>
transmute(
tow_id, cruise_orig = year_month_of_tow, ship_name = ship, sorting_lab,
date, datetime_start_utc, line, station, site_key, latitude, longitude,
max_tow_depth_m = suppressWarnings(as.numeric(max_tow_depth_m)),
volume_filtered = suppressWarnings(as.numeric(volume_water_filtered_ml_1000m3)),
aliquot_pct = suppressWarnings(as.numeric(aliquot_percent)),
aliquot_adjustment = aliquot_adjustment_value, study_flag)
dbWriteTable(con, "phyllosoma_tow", d_tow, overwrite = TRUE)
stage_cols <- c("total_phyllosoma", paste0("stage_", 1:11))
new_names <- c("total_phyllosoma", paste0("phyllosoma_stage_", 1:11))
d_meas <- d |>
select(tow_id, all_of(stage_cols)) |>
rename_with(~ new_names, all_of(stage_cols)) |>
pivot_longer(all_of(new_names), names_to = "measurement_type", values_to = "measurement_value") |>
mutate(measurement_value = suppressWarnings(as.double(measurement_value)),
measurement_qual = NA_character_) |>
filter(!is.na(measurement_value)) |>
mutate(phyllosoma_measurement_id = row_number(), .before = 1)
dbWriteTable(con, "phyllosoma_measurement", d_meas, overwrite = TRUE)
cat(glue("phyllosoma_tow {nrow(d_tow)}, phyllosoma_measurement {nrow(d_meas)}"), "\n")
```
## Resolve Keys + Spatial
```{r}
#| label: keys-spatial
load_prior_tables(con, parquet_dir = here("data/parquet/swfsc_ichthyo"),
tables = c("ship","cruise","grid"), geom_tables = c("grid"), as_view = TRUE)
# source "Ship" is a NODC ship code (e.g. 31PT), not a name -> join on ship_nodc
d_ship <- dbGetQuery(con, "SELECT ship_key, ship_nodc FROM ship")
zt <- dbGetQuery(con, "SELECT tow_id, ship_name AS ship_nodc, date FROM phyllosoma_tow") |>
left_join(d_ship, by = "ship_nodc") |>
mutate(cruise_key = if_else(is.na(ship_nodc)|is.na(date), NA_character_,
as.character(glue("{format(date,'%Y-%m')}-{ship_nodc}"))))
valid_ck <- dbGetQuery(con, "SELECT DISTINCT cruise_key FROM cruise")$cruise_key
zt <- zt |> mutate(cruise_key = if_else(cruise_key %in% valid_ck, cruise_key, NA_character_))
dbWriteTable(con, "zk", zt |> select(tow_id, ship_key, cruise_key), overwrite = TRUE)
dbExecute(con, "ALTER TABLE phyllosoma_tow ADD COLUMN IF NOT EXISTS ship_key VARCHAR")
dbExecute(con, "ALTER TABLE phyllosoma_tow ADD COLUMN IF NOT EXISTS cruise_key VARCHAR")
dbExecute(con, "UPDATE phyllosoma_tow t SET ship_key=z.ship_key, cruise_key=z.cruise_key FROM zk z WHERE t.tow_id=z.tow_id")
dbExecute(con, "DROP TABLE zk")
cat(glue("ship {sum(!is.na(zt$ship_key))}/{nrow(zt)}; cruise_key {sum(!is.na(zt$cruise_key))}/{nrow(zt)}"), "\n")
add_point_geom(con, "phyllosoma_tow", lon_col = "longitude", lat_col = "latitude")
assign_grid_key(con, "phyllosoma_tow") |> datatable(caption = "Grid assignment")
```
## Measurement Types + Finalize
```{r}
#| label: finalize
phyllo_types <- tibble(
measurement_type = new_names,
description = c("Total phyllosoma larvae count", paste0("Phyllosoma stage ", 1:11, " count")),
units = "count", `_source_column` = new_names, `_source_table` = "phyllosoma_measurement",
`_source_datasets` = "calcofi_phyllosoma", `_qual_column` = NA_character_, `_prec_column` = NA_character_)
new_types <- phyllo_types |> filter(!measurement_type %in% d_meas_type$measurement_type)
if (nrow(new_types) > 0) { d_meas_type <- bind_rows(d_meas_type, new_types); write_csv(d_meas_type, meas_type_csv) }
dbWriteTable(con, "measurement_type", d_meas_type, overwrite = TRUE)
d_dataset <- ingest_yaml_to_dataset_df(read_ingest_yaml(here()))
dbWriteTable(con, "dataset", d_dataset, overwrite = TRUE)
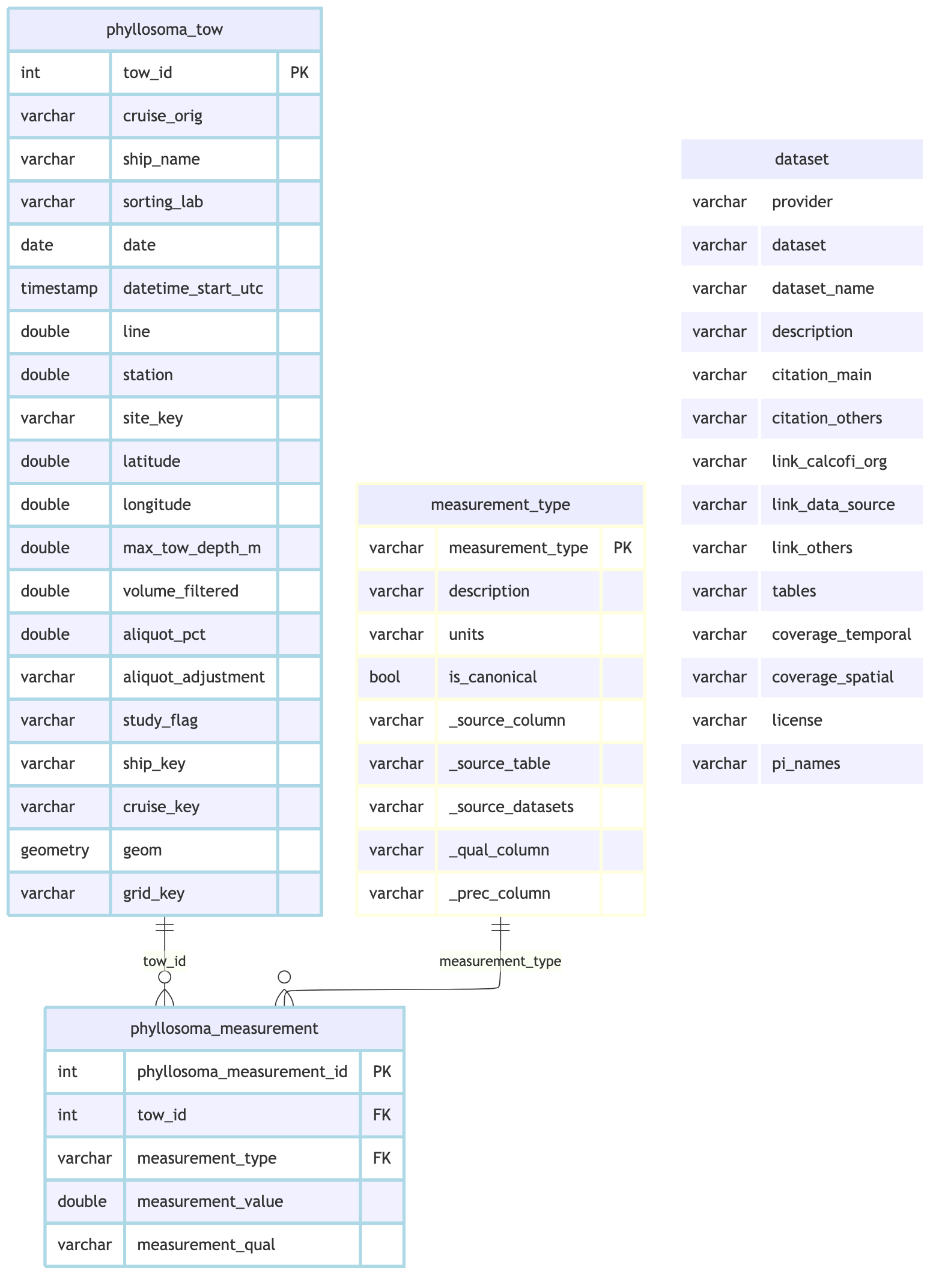
phyllo_rels <- list(
primary_keys = list(phyllosoma_tow = "tow_id", phyllosoma_measurement = "phyllosoma_measurement_id",
measurement_type = "measurement_type"),
foreign_keys = list(
list(table="phyllosoma_measurement", column="tow_id", ref_table="phyllosoma_tow", ref_column="tow_id"),
list(table="phyllosoma_measurement", column="measurement_type", ref_table="measurement_type", ref_column="measurement_type")))
cc_erd(con, tables = c("phyllosoma_tow","phyllosoma_measurement","measurement_type","dataset"), rels = phyllo_rels,
colors = list(lightblue = c("phyllosoma_tow","phyllosoma_measurement"), lightyellow = "measurement_type", white = "dataset"))
build_relationships_json(rels = phyllo_rels, output_dir = dir_parquet, provider = provider, dataset = dataset)
results <- validate_for_release(con, checks = "all", strict = FALSE)
cat("Validation:", ifelse(results$passed, "PASSED", "FAILED"), "\n")
dir_create(dir_parquet)
write_parquet_outputs(con = con, output_dir = dir_parquet,
tables = c("phyllosoma_tow","phyllosoma_measurement","measurement_type","dataset"),
sort_by = list(phyllosoma_measurement = "measurement_type"), strip_provenance = FALSE)
d_tbls_rd <- read_csv(here("metadata/calcofi/phyllosoma/tbls_redefine.csv"))
d_flds_rd <- read_csv(here("metadata/calcofi/phyllosoma/flds_redefine.csv"))
build_metadata_json(con = con, d_tbls_rd = d_tbls_rd, d_flds_rd = d_flds_rd,
metadata_derived_csv = here("metadata/calcofi/phyllosoma/metadata_derived.csv"),
output_dir = dir_parquet, tables = c("phyllosoma_tow","phyllosoma_measurement"),
set_comments = TRUE, provider = provider, dataset = dataset,
workflow_url = cc$workflow_url, tables_owned = tables_owned)
sync_to_gcs(local_dir = dir_parquet, gcs_prefix = glue("ingest/{dir_label}"), bucket = "calcofi-db")
```
## Questions for Data Providers
```{r}
#| label: provider-questions
read_csv(here(glue("metadata/{provider}/{dataset}/questions.csv"))) |>
arrange(factor(priority, c("blocker","high","normal")), id) |>
select(priority, question, context, status) |>
datatable(caption = "Questions (ranked)", options = list(dom="t"), rownames = FALSE)
```
```{r}
#| label: cleanup
close_duckdb(con); cat(glue("Parquet outputs written to: {dir_parquet}"), "\n")
```