Code
graph LR
A[NCEI CSV] --> B[DuckDB Wrangling]
B --> C[Parse Station + Date]
C --> D[Match to Casts]
D --> E[Pivot ALL → long]
E --> F[Summarize Replicates]
F --> G[Parquet Export]
G --> H[GCS Archive]Source: DIC | CalCOFI.org
Dissolved Inorganic Carbon (DIC) and Total Alkalinity (TA) from CalCOFI Niskin bottle samples, archived at NCEI accession 0301029.
calcofi (CalCOFI program; PI: Todd Martz, Scripps)CALCOFI_DIC_20250122.csv (~500KB, 4,391 rows)Strategy: Load source CSV, pivot ALL four measurement columns (DIC, TA, CTD temperature, salinity) into tidy long-format dic_measurement, then summarize replicates into dic_summary. The base dic_sample table retains only position/time/FK columns — no measurement values.
graph LR
A[NCEI CSV] --> B[DuckDB Wrangling]
B --> C[Parse Station + Date]
C --> D[Match to Casts]
D --> E[Pivot ALL → long]
E --> F[Summarize Replicates]
F --> G[Parquet Export]
G --> H[GCS Archive]Four measurement types from this dataset — all new types, distinct from bottle/CTD equivalents because these come from a separate instrument chain with WOCE QC:
| measurement_type | description | units | source column | status |
|---|---|---|---|---|
dic |
Dissolved inorganic carbon | umol/kg | DIC | NEW |
alkalinity |
Total alkalinity | umol/kg | TA | NEW |
ctdtemp_its90 |
CTD temperature (ITS-90) | degC | CTDTEMP_ITS90 | NEW |
salinity_pss78 |
Practical salinity (PSS-78) | PSS-78 | Salinity_PSS78 | NEW |
These are kept separate from the calcofi_bottle temperature/salinity types because the DIC dataset values come from a different QC pipeline (WOCE flags vs calcofi.org quality codes).
# devtools::install_local(here::here("../calcofi4db"), force = T)
devtools::load_all(here::here("../calcofi4db"))
devtools::load_all(here::here("../calcofi4r"))
librarian::shelf(
CalCOFI / calcofi4db,
CalCOFI / calcofi4r,
DBI,
dplyr,
DT,
fs,
glue,
googledrive,
here,
htmltools,
janitor,
jsonlite,
knitr,
lubridate,
purrr,
readr,
sf,
stringr,
tibble,
tidyr,
units,
quiet = T
)
options(readr.show_col_types = F)
options(DT.options = list(scrollX = TRUE))
# common ingest settings (overwrite, dir_data)
source(here("libs/ingest.R"))
# define paths
# provider/dataset/metadata read from this file's authoritative YAML block
cc <- read_calcofi_meta(here("ingest_calcofi_dic.qmd"))
provider <- cc$provider
dataset <- cc$dataset
dataset_name <- cc$dataset_meta$dataset_name
tables_owned <- cc$tables_owned
dir_label <- glue("{provider}_{dataset}")
dir_parquet <- here(glue("data/parquet/{dir_label}"))
db_path <- here(glue("data/wrangling/{dir_label}.duckdb"))
# clean slate if overwrite (keep dir_parquet for content-hash dedup)
if (overwrite) {
if (file_exists(db_path)) file_delete(db_path)
# clear stale WAL/tmp from an interrupted run
if (file_exists(paste0(db_path, ".wal"))) file_delete(paste0(db_path, ".wal"))
if (dir_exists(paste0(db_path, ".tmp"))) dir_delete(paste0(db_path, ".tmp"))
}
dir_create(dirname(db_path))
con <- get_duckdb_con(db_path)
load_duckdb_extension(con, "spatial")
# archive source files to GCS
dir_src <- path_expand(glue("{dir_data}/{provider}/{dataset}"))
sync_to_gcs(
local_dir = dir_src,
gcs_prefix = glue("archive/{provider}/{dataset}"),
bucket = "calcofi-files-public",
exclude = c(".DS_Store", "*.tmp"))# A tibble: 11 × 4
file action size reason
<chr> <chr> <dbl> <chr>
1 0301029/0301029.1.1.xml skipped 13438 checksum …
2 0301029/1.1/about/0301029_lonlat.txt skipped 1278 checksum …
3 0301029/1.1/about/0301029_map.jpg skipped 270529 checksum …
4 0301029/1.1/about/BH2MXN3XW-confirmation_email.txt skipped 1154 checksum …
5 0301029/1.1/about/journal.txt skipped 1455 checksum …
6 0301029/1.1/data/0-data/BH2MXN3XW.xml skipped 3915 checksum …
7 0301029/1.1/data/0-data/CalCOFI_Code_Figures.pdf skipped 1352977 checksum …
8 0301029/1.1/data/0-data/CALCOFI_DIC_20250122.csv skipped 499613 checksum …
9 0301029/1.1/NCEI-Readme.txt skipped 1847 checksum …
10 CalCOFI_DICs_200901-201507_28June2018.csv skipped 306152 checksum …
11 DIC – CalCOFI.pdf skipped 656252 checksum …# load unified measurement_type reference
meas_type_csv <- here("metadata/measurement_type.csv")
d_meas_type <- read_csv(meas_type_csv)The NCEI CSV has a units row (row 2) that must be skipped, and uses -999 as the missing value sentinel.
dic_csv <- glue(
"{dir_data}/calcofi/dic/0301029/1.1/data/0-data/",
"CALCOFI_DIC_20250122.csv"
)
stopifnot("DIC CSV not found" = file_exists(dic_csv))
# read, skipping the units row (row 2)
d_raw <- read_csv(dic_csv, skip = 2, col_names = FALSE)
# get header from row 1
hdr <- read_csv(dic_csv, n_max = 0) |> names()
names(d_raw) <- hdr
cat(glue("Read {nrow(d_raw)} rows, {ncol(d_raw)} columns from {basename(dic_csv)}"), "\n")Read 4391 rows, 18 columns from CALCOFI_DIC_20250122.csv Replace -999 with NA, convert character columns to proper types, and build a datetime column.
d_clean <- d_raw |>
mutate(
# convert numeric columns stored as character (due to units row)
Latitude = as.numeric(Latitude),
Longitude = as.numeric(Longitude),
Depth = as.numeric(Depth),
CTDTEMP_ITS90 = as.numeric(CTDTEMP_ITS90),
DIC = as.numeric(DIC),
TA = as.numeric(TA),
# replace -999 sentinels with NA across all numeric columns
across(
where(is.numeric),
~ if_else(.x == -999, NA_real_, .x)),
# build datetime from components
datetime_start_utc = make_datetime(
Year_UTC, Month_UTC, Day_UTC,
tz = "UTC"),
# site_key matching calcofi convention: "090.0 062.0"
site_key = Station_ID
)
# summary of NA replacement
na_counts <- d_clean |>
summarise(across(where(is.numeric), ~ sum(is.na(.x)))) |>
pivot_longer(everything(), names_to = "column", values_to = "n_na") |>
filter(n_na > 0)
na_counts |> datatable(caption = "NULL counts after -999 replacement")Load dic_sample as a tidy position table — only station, time, depth, and FK columns. Measurement values (DIC, TA, temp, salinity) are pivoted into dic_measurement in the next step.
# tidy: dic_sample has position/time only, no measurement values
d_dic <- d_clean |>
transmute(
expocode = EXPOCODE,
ship_name = Ship_Name,
datetime_start_utc = datetime_start_utc,
site_key = site_key,
latitude = Latitude,
longitude = Longitude,
depth_m = Depth
)
dbWriteTable(con, "dic_sample", d_dic, overwrite = TRUE)
cat(glue("dic_sample: {nrow(d_dic)} rows, {ncol(d_dic)} columns loaded"), "\n")dic_sample: 4391 rows, 7 columns loaded # also load the wide-format data temporarily for pivoting
d_wide <- d_clean |>
transmute(
expocode = EXPOCODE,
site_key = Station_ID,
datetime_start_utc = datetime_start_utc,
depth_m = Depth,
latitude = Latitude,
longitude = Longitude,
ctdtemp_its90 = CTDTEMP_ITS90,
ctdtemp_its90_flag = as.integer(CTDTEMP_flag),
salinity_pss78 = Salinity_PSS78,
salinity_pss78_flag = as.integer(Salinity_flag),
dic = DIC,
dic_flag = as.integer(DIC_flag),
alkalinity = TA,
alkalinity_flag = as.integer(TA_flag)
)
dbWriteTable(con, "dic_wide", d_wide, overwrite = TRUE)Load existing casts from bottle workflow parquet and match DIC samples to casts using site_key + datetime_start_utc (±3 day window).
# load casts and bottle from bottle workflow
# include "casts" in geom_tables since it has GEOMETRY columns
load_prior_tables(
con = con,
tables = c("casts", "bottle"),
parquet_dir = here("data/parquet/calcofi_bottle"),
geom_tables = c("grid", "site", "segment", "casts"),
as_view = TRUE
)# A tibble: 2 × 3
table rows has_geom
<chr> <dbl> <lgl>
1 bottle 895371 FALSE
2 casts 35644 TRUE # station matching
n_dic_sta <- dbGetQuery(
con, "SELECT COUNT(DISTINCT site_key) FROM dic_sample")[[1]]
n_matched_sta <- dbGetQuery(
con,
"SELECT COUNT(DISTINCT d.site_key)
FROM dic_sample d
INNER JOIN casts c ON d.site_key = c.site_key")[[1]]
cat(glue(
"Station matching: {n_matched_sta}/{n_dic_sta} DIC stations found in casts"), "\n")Station matching: 61/71 DIC stations found in casts # match DIC samples to casts by site_key + datetime (±3 day window) via the
# shared calcofi4db helper (resolves issue #47). many dates are offset by 1 day
# between NCEI and calcofi.org, hence the window.
m_cast <- match_by_site_datetime(
con, data_tbl = "dic_sample", ref_tbl = "casts",
fk_col = "cast_id", ref_pk = "cast_id",
key_col = "site_key", datetime_col = "datetime_start_utc", window_days = 3)
cat(glue(
"Cast matching: {m_cast$matched}/{m_cast$total} DIC samples matched ",
"({m_cast$pct}%)"), "\n")Cast matching: 1086/4391 DIC samples matched (24.7%) # show unmatched samples
if (nrow(m_cast$unmatched) > 0)
m_cast$unmatched |> datatable(caption = "Unmatched DIC samples (no matching cast)")For matched casts, find the nearest bottle at the same depth.
# for cast-matched samples, find the nearest bottle by depth via the shared
# calcofi4db helper (scoped to the already-matched cast_id).
m_btl <- match_nearest_by_depth(
con, data_tbl = "dic_sample", ref_tbl = "bottle",
fk_col = "bottle_id", ref_pk = "bottle_id",
parent_fk = "cast_id", axis_col = "depth_m", tolerance = 1.0)
cat(glue(
"Bottle matching: {m_btl$matched}/{m_btl$eligible} cast-matched samples ",
"({m_btl$pct}%)"), "\n")Bottle matching: 1065/1086 cast-matched samples (98.1%) # propagate FKs to dic_wide for pivoting
dbExecute(con, "ALTER TABLE dic_wide ADD COLUMN IF NOT EXISTS cast_id INTEGER")[1] 0dbExecute(con, "ALTER TABLE dic_wide ADD COLUMN IF NOT EXISTS bottle_id INTEGER")[1] 0dbExecute(
con,
"UPDATE dic_wide w SET
cast_id = s.cast_id,
bottle_id = s.bottle_id
FROM dic_sample s
WHERE w.expocode = s.expocode
AND w.site_key = s.site_key
AND w.datetime_start_utc = s.datetime_start_utc
AND w.depth_m IS NOT DISTINCT FROM s.depth_m"
)[1] 5347Pivot all four measurement columns (DIC, TA, CTD temperature, salinity) into tidy long-format dic_measurement. Each row = one measurement at one position. This follows tidy data principles — no mixing of different measured quantities on the same row.
# pivot all 4 measurement types from wide to long
meas_map <- list(
list(type = "dic", col = "dic", flag = "dic_flag"),
list(type = "alkalinity", col = "alkalinity", flag = "alkalinity_flag"),
list(type = "ctdtemp_its90", col = "ctdtemp_its90", flag = "ctdtemp_its90_flag"),
list(type = "salinity_pss78", col = "salinity_pss78", flag = "salinity_pss78_flag")
)
sql_parts <- map_chr(meas_map, \(m) glue(
"SELECT expocode, site_key, datetime_start_utc, depth_m,
latitude, longitude, cast_id, bottle_id,
'{m$type}' AS measurement_type,
CAST({m$col} AS DOUBLE) AS measurement_value,
CAST({m$flag} AS VARCHAR) AS measurement_qual
FROM dic_wide
WHERE {m$col} IS NOT NULL
AND NOT isnan(CAST({m$col} AS DOUBLE))
AND isfinite(CAST({m$col} AS DOUBLE))"
))
dbExecute(con, glue(
"CREATE OR REPLACE TABLE dic_measurement AS
SELECT ROW_NUMBER() OVER (
ORDER BY site_key, datetime_start_utc, depth_m, measurement_type
) AS dic_measurement_id, *
FROM ({paste(sql_parts, collapse = '\nUNION ALL\n')}) sub"
))[1] 16391# drop the temporary wide table
dbExecute(con, "DROP TABLE dic_wide")[1] 0n_meas <- dbGetQuery(con, "SELECT COUNT(*) FROM dic_measurement")[[1]]
cat(glue("dic_measurement: {format(n_meas, big.mark = ',')} rows"), "\n")dic_measurement: 16,391 rows # summary by type
dbGetQuery(
con,
"SELECT measurement_type, COUNT(*) AS n,
ROUND(AVG(measurement_value), 1) AS mean_val,
ROUND(MIN(measurement_value), 1) AS min_val,
ROUND(MAX(measurement_value), 1) AS max_val
FROM dic_measurement
GROUP BY measurement_type
ORDER BY measurement_type"
) |> datatable(caption = "Measurement summary by type")Aggregate replicate measurements at each unique position in time and space (station + date + depth) into mean and standard deviation, following ctd_summary in ingest_calcofi_ctd-cast.qmd. Filters out NaN, -Inf, Inf values.
dbExecute(
con,
"CREATE OR REPLACE TABLE dic_summary AS
SELECT
site_key,
datetime_start_utc,
depth_m,
latitude,
longitude,
measurement_type,
AVG(measurement_value) AS avg,
CASE
WHEN COUNT(*) = 1 THEN 0
ELSE COALESCE(STDDEV_SAMP(measurement_value), 0)
END AS stddev,
COUNT(*) AS n_obs,
MAX(cast_id) AS cast_id,
MAX(bottle_id) AS bottle_id
FROM dic_measurement
WHERE NOT isnan(measurement_value)
AND isfinite(measurement_value)
GROUP BY site_key, datetime_start_utc, depth_m,
latitude, longitude, measurement_type"
)[1] 15786n_summ <- dbGetQuery(con, "SELECT COUNT(*) FROM dic_summary")[[1]]
cat(glue(
"dic_summary: {format(n_summ, big.mark = ',')} rows ",
"(from {format(n_meas, big.mark = ',')} measurements)"), "\n")dic_summary: 15,786 rows (from 16,391 measurements) dbGetQuery(
con,
"SELECT measurement_type,
COUNT(*) AS n_positions,
SUM(n_obs) AS n_raw_obs,
ROUND(AVG(n_obs), 1) AS avg_replicates,
SUM(CASE WHEN n_obs > 1 THEN 1 ELSE 0 END) AS n_with_replicates,
ROUND(AVG(stddev), 3) AS avg_stddev
FROM dic_summary
GROUP BY measurement_type
ORDER BY measurement_type"
) |> datatable(caption = "Replicate statistics by type")# dataset registry built from authoritative ingest_*.qmd YAML (was dataset.csv)
d_dataset <- ingest_yaml_to_dataset_df(read_ingest_yaml(here()))
dbWriteTable(con, "dataset", d_dataset, overwrite = TRUE)
cat(glue("dataset: {nrow(d_dataset)} datasets registered"), "\n")dataset: 5 datasets registered Register the 4 measurement types from this dataset. All are new — distinct from bottle/CTD types due to different QC pipelines.
dic_types <- tibble(
measurement_type = c("dic", "alkalinity", "ctdtemp_its90", "salinity_pss78"),
description = c("Dissolved inorganic carbon",
"Total alkalinity",
"CTD temperature (ITS-90 scale)",
"Practical salinity (PSS-78)"),
units = c("umol/kg", "umol/kg", "degC", "PSS-78"),
`_source_column` = c("DIC", "TA", "CTDTEMP_ITS90", "Salinity_PSS78"),
`_source_table` = c("dic_measurement", "dic_measurement", "dic_measurement", "dic_measurement"),
`_source_datasets` = c("calcofi_dic", "calcofi_dic", "calcofi_dic", "calcofi_dic"),
`_qual_column` = c("dic_flag", "ta_flag", "ctdtemp_its90_flag", "salinity_pss78_flag"),
`_prec_column` = c(NA_character_, NA_character_, NA_character_, NA_character_)
)
existing <- d_meas_type |>
filter(measurement_type %in% dic_types$measurement_type) |>
pull(measurement_type)
new_types <- dic_types |> filter(!measurement_type %in% existing)
if (nrow(new_types) > 0) {
cat(glue("Adding {nrow(new_types)} new measurement types: ",
"{paste(new_types$measurement_type, collapse = ', ')}"), "\n")
d_meas_type <- bind_rows(d_meas_type, new_types)
write_csv(d_meas_type, meas_type_csv)
} else {
cat("All measurement types already registered\n")
}All measurement types already registereddbWriteTable(con, "measurement_type", d_meas_type, overwrite = TRUE)# dic_sample composite key
n_dup_sample <- dbGetQuery(
con,
"SELECT COUNT(*) FROM (
SELECT expocode, site_key, depth_m, datetime_start_utc, COUNT(*) AS n
FROM dic_sample
GROUP BY expocode, site_key, depth_m, datetime_start_utc
HAVING COUNT(*) > 1)")[[1]]
cat(glue("dic_sample composite key duplicates: {n_dup_sample}"), "\n")dic_sample composite key duplicates: 196 # dic_summary composite key
n_dup_summ <- dbGetQuery(
con,
"SELECT COUNT(*) FROM (
SELECT site_key, datetime_start_utc, depth_m, measurement_type, COUNT(*) AS n
FROM dic_summary
GROUP BY site_key, datetime_start_utc, depth_m, measurement_type
HAVING COUNT(*) > 1)")[[1]]
cat(glue("dic_summary composite key duplicates: {n_dup_summ}"), "\n")dic_summary composite key duplicates: 0 dic_sample (position/time)
↓ (site_key + datetime_start_utc + depth_m)
dic_measurement (one row per measurement)
dic_measurement.measurement_type (FK) → measurement_type.measurement_type
↓ (site_key + datetime_start_utc + depth_m + measurement_type)
dic_summary (avg/stddev per position)
dic_summary.measurement_type (FK) → measurement_type.measurement_type# define PK/FK relationships for visualization and relationships.json
dic_rels <- list(
primary_keys = list(
dic_measurement = "dic_measurement_id",
measurement_type = "measurement_type"),
foreign_keys = list(
list(table = "dic_measurement", column = "measurement_type", ref_table = "measurement_type", ref_column = "measurement_type"),
list(table = "dic_summary", column = "measurement_type", ref_table = "measurement_type", ref_column = "measurement_type")))
dic_tables <- c(
"dic_sample", "dic_measurement", "dic_summary",
"measurement_type", "dataset")
cc_erd(
con,
tables = dic_tables,
rels = dic_rels,
colors = list(
lightblue = c("dic_sample", "dic_measurement", "dic_summary"),
lightyellow = "measurement_type",
white = "dataset"))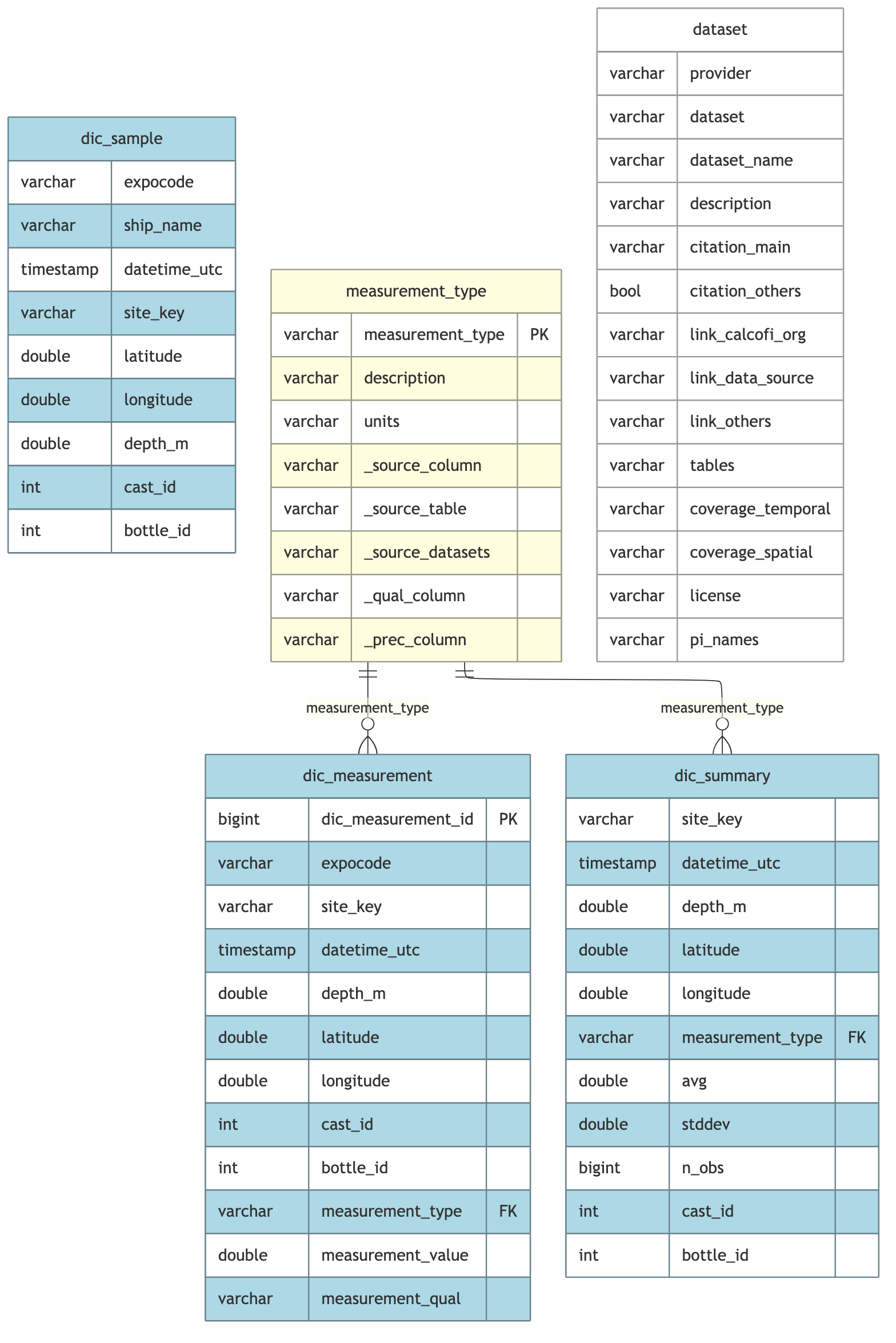
build_relationships_json(
rels = dic_rels,
output_dir = dir_parquet,
provider = provider,
dataset = dataset
)[1] "/Users/bbest/Github/CalCOFI/workflows/data/parquet/calcofi_dic/relationships.json"add_point_geom(con, "dic_sample", lon_col = "longitude", lat_col = "latitude")# exclude GEOMETRY columns for R driver compatibility
ds_cols <- dbGetQuery(con,
"SELECT column_name FROM information_schema.columns
WHERE table_name = 'dic_sample' AND data_type NOT LIKE 'GEOMETRY%'")$column_name
dbGetQuery(con, glue("SELECT {paste(ds_cols, collapse=', ')} FROM dic_sample LIMIT 100")) |>
datatable(
caption = glue(
"dic_sample — first 100 of ",
"{format(dbGetQuery(con, 'SELECT COUNT(*) FROM dic_sample')[[1]], big.mark=',')} rows"),
rownames = FALSE, filter = "top")dbGetQuery(con, "SELECT * FROM dic_measurement LIMIT 100") |>
datatable(
caption = glue(
"dic_measurement — first 100 of ",
"{format(dbGetQuery(con, 'SELECT COUNT(*) FROM dic_measurement')[[1]], big.mark=',')} rows"),
rownames = FALSE, filter = "top")dbGetQuery(con, "SELECT * FROM dic_summary LIMIT 100") |>
datatable(
caption = glue(
"dic_summary — first 100 of ",
"{format(dbGetQuery(con, 'SELECT COUNT(*) FROM dic_summary')[[1]], big.mark=',')} rows"),
rownames = FALSE, filter = "top")dir_create(dir_parquet)
# collect mismatches for manifest
mismatches <- list(
measurement_types = collect_measurement_type_mismatches(
con, here("metadata/measurement_type.csv")),
cruise_keys = collect_cruise_key_mismatches(con, "dic_sample"))
parquet_stats <- write_parquet_outputs(
con = con,
output_dir = dir_parquet,
tables = c("dic_sample", "dic_measurement",
"dic_summary", "measurement_type",
"dataset"),
sort_by = list(
dic_measurement = "measurement_type",
dic_summary = "measurement_type"),
strip_provenance = FALSE,
mismatches = mismatches
)
parquet_stats |>
mutate(file = basename(path)) |>
select(-path) |>
datatable(caption = "Parquet export statistics")d_tbls_rd <- read_csv(here("metadata/calcofi/dic/tbls_redefine.csv"))
d_flds_rd <- read_csv(here("metadata/calcofi/dic/flds_redefine.csv"))
metadata_path <- build_metadata_json(
con = con,
d_tbls_rd = d_tbls_rd,
d_flds_rd = d_flds_rd,
output_dir = dir_parquet,
tables = c("dic_sample", "dic_measurement",
"dic_summary"),
set_comments = TRUE,
provider = provider,
dataset = dataset,
workflow_url = cc$workflow_url,
tables_owned = tables_owned
)listviewer::jsonedit(
jsonlite::fromJSON(metadata_path, simplifyVector = FALSE),
mode = "view")listviewer::jsonedit(
jsonlite::fromJSON(
file.path(dir_parquet, "relationships.json"),
simplifyVector = FALSE),
mode = "view")sync_to_gcs(
local_dir = dir_parquet,
gcs_prefix = glue("ingest/{dir_label}"),
bucket = "calcofi-db")# A tibble: 8 × 4
file action size reason
<chr> <chr> <dbl> <chr>
1 dataset.parquet uploaded 5396 crc32c changed
2 dic_measurement.parquet uploaded 130559 crc32c changed
3 dic_sample.parquet uploaded 27575 crc32c changed
4 dic_summary.parquet uploaded 124127 crc32c changed
5 manifest.json uploaded 2554 crc32c changed
6 measurement_type.parquet uploaded 4949 crc32c changed
7 metadata.json uploaded 5097 crc32c changed
8 relationships.json skipped 530 checksum matchclose_duckdb(con)
cat(glue("Parquet outputs written to: {dir_parquet}"), "\n")Parquet outputs written to: /Users/bbest/Github/CalCOFI/workflows/data/parquet/calcofi_dic devtools::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 4.5.2 (2025-10-31)
os macOS Sequoia 15.7.1
system aarch64, darwin20
ui X11
language (EN)
collate en_US.UTF-8
ctype en_US.UTF-8
tz Europe/Rome
date 2026-06-07
pandoc 3.8.3 @ /opt/homebrew/bin/ (via rmarkdown)
quarto 1.8.25 @ /usr/local/bin/quarto
─ Packages ───────────────────────────────────────────────────────────────────
! package * version date (UTC) lib source
abind 1.4-8 2024-09-12 [1] CRAN (R 4.5.0)
arrow 24.0.0 2026-04-29 [1] CRAN (R 4.5.2)
assertthat 0.2.1 2019-03-21 [1] CRAN (R 4.5.0)
backports 1.5.1 2026-04-03 [1] CRAN (R 4.5.2)
base64enc 0.1-6 2026-02-02 [1] CRAN (R 4.5.2)
bit 4.6.0 2025-03-06 [1] CRAN (R 4.5.0)
bit64 4.8.2 2026-05-19 [1] CRAN (R 4.5.2)
blob 1.3.0 2026-01-14 [1] CRAN (R 4.5.2)
broom 1.0.13 2026-05-14 [1] CRAN (R 4.5.2)
bslib 0.11.0 2026-05-16 [1] CRAN (R 4.5.2)
cachem 1.1.0 2024-05-16 [1] CRAN (R 4.5.0)
P calcofi4db * 2.8.2 2026-06-07 [?] load_all()
P calcofi4r * 1.3.0 2026-06-05 [?] load_all()
class 7.3-23 2025-01-01 [1] CRAN (R 4.5.2)
classInt 0.4-11 2025-01-08 [1] CRAN (R 4.5.0)
cli 3.6.6 2026-04-09 [1] CRAN (R 4.5.2)
codetools 0.2-20 2024-03-31 [1] CRAN (R 4.5.2)
crayon 1.5.3 2024-06-20 [1] CRAN (R 4.5.0)
crosstalk 1.2.2 2025-08-26 [1] CRAN (R 4.5.0)
curl 7.1.0 2026-04-22 [1] CRAN (R 4.5.2)
data.table 1.18.4 2026-05-06 [1] CRAN (R 4.5.2)
DBI * 1.3.0 2026-02-25 [1] CRAN (R 4.5.2)
dbplyr 2.5.2 2026-02-13 [1] CRAN (R 4.5.2)
desc 1.4.3 2023-12-10 [1] CRAN (R 4.5.0)
devtools 2.5.0 2026-03-14 [1] CRAN (R 4.5.2)
DiagrammeR 1.0.12 2026-04-27 [1] CRAN (R 4.5.2)
DiagrammeRsvg 0.1 2016-02-04 [1] CRAN (R 4.5.0)
digest 0.6.39 2025-11-19 [1] CRAN (R 4.5.2)
dm 1.1.2 2026-05-17 [1] CRAN (R 4.5.2)
dplyr * 1.2.1 2026-04-03 [1] CRAN (R 4.5.2)
DT * 0.34.0 2025-09-02 [1] CRAN (R 4.5.0)
duckdb 1.5.2 2026-04-13 [1] CRAN (R 4.5.2)
dygraphs 1.1.1.6 2018-07-11 [1] CRAN (R 4.5.0)
e1071 1.7-17 2025-12-18 [1] CRAN (R 4.5.2)
ellipsis 0.3.2 2021-04-29 [1] CRAN (R 4.5.0)
evaluate 1.0.5 2025-08-27 [1] CRAN (R 4.5.0)
farver 2.1.2 2024-05-13 [1] CRAN (R 4.5.0)
fastmap 1.2.0 2024-05-15 [1] CRAN (R 4.5.0)
fs * 2.1.0 2026-04-18 [1] CRAN (R 4.5.2)
fuzzyjoin 0.1.8 2026-02-20 [1] CRAN (R 4.5.2)
gargle 1.6.1 2026-01-29 [1] CRAN (R 4.5.2)
generics 0.1.4 2025-05-09 [1] CRAN (R 4.5.0)
geojsonsf 2.0.5 2025-11-26 [1] CRAN (R 4.5.2)
ggplot2 4.0.3 2026-04-22 [1] CRAN (R 4.5.2)
glue * 1.8.1 2026-04-17 [1] CRAN (R 4.5.2)
googledrive * 2.1.2 2025-09-10 [1] CRAN (R 4.5.0)
gtable 0.3.6 2024-10-25 [1] CRAN (R 4.5.0)
here * 1.0.2 2025-09-15 [1] CRAN (R 4.5.0)
highcharter 0.9.5 2026-04-22 [1] CRAN (R 4.5.2)
hms 1.1.4 2025-10-17 [1] CRAN (R 4.5.0)
htmltools * 0.5.9 2025-12-04 [1] CRAN (R 4.5.2)
htmlwidgets 1.6.4 2023-12-06 [1] CRAN (R 4.5.0)
httpuv 1.6.17 2026-03-18 [1] CRAN (R 4.5.2)
httr 1.4.8 2026-02-13 [1] CRAN (R 4.5.2)
httr2 1.2.2 2025-12-08 [1] CRAN (R 4.5.2)
igraph 2.3.2 2026-05-29 [1] CRAN (R 4.5.2)
isoband 0.3.0 2025-12-07 [1] CRAN (R 4.5.2)
janitor * 2.2.1 2024-12-22 [1] CRAN (R 4.5.0)
jquerylib 0.1.4 2021-04-26 [1] CRAN (R 4.5.0)
jsonlite * 2.0.0 2025-03-27 [1] CRAN (R 4.5.0)
KernSmooth 2.23-26 2025-01-01 [1] CRAN (R 4.5.2)
knitr * 1.51 2025-12-20 [1] CRAN (R 4.5.2)
later 1.4.8 2026-03-05 [1] CRAN (R 4.5.2)
lattice 0.22-9 2026-02-09 [1] CRAN (R 4.5.2)
lazyeval 0.2.3 2026-04-04 [1] CRAN (R 4.5.2)
leafem 0.2.5 2025-08-28 [1] CRAN (R 4.5.0)
leaflet 2.2.3 2025-09-04 [1] CRAN (R 4.5.0)
librarian 1.8.1 2021-07-12 [1] CRAN (R 4.5.0)
lifecycle 1.0.5 2026-01-08 [1] CRAN (R 4.5.2)
listviewer 4.0.0 2023-09-30 [1] CRAN (R 4.5.0)
lubridate * 1.9.5 2026-02-04 [1] CRAN (R 4.5.2)
magrittr 2.0.5 2026-04-04 [1] CRAN (R 4.5.2)
mapgl 0.4.6 2026-06-05 [1] Github (bbest/mapgl@0b70b3f)
mapview 2.11.4 2025-09-08 [1] CRAN (R 4.5.0)
markdown 2.0 2025-03-23 [1] CRAN (R 4.5.0)
Matrix 1.7-5 2026-03-21 [1] CRAN (R 4.5.2)
memoise 2.0.1 2021-11-26 [1] CRAN (R 4.5.0)
mgcv 1.9-4 2025-11-07 [1] CRAN (R 4.5.0)
mime 0.13 2025-03-17 [1] CRAN (R 4.5.0)
nlme 3.1-169 2026-03-27 [1] CRAN (R 4.5.2)
otel 0.2.0 2025-08-29 [1] CRAN (R 4.5.0)
pillar 1.11.1 2025-09-17 [1] CRAN (R 4.5.0)
pkgbuild 1.4.8 2025-05-26 [1] CRAN (R 4.5.0)
pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.5.0)
pkgload 1.5.1 2026-04-01 [1] CRAN (R 4.5.2)
plotly 4.12.0 2026-01-24 [1] CRAN (R 4.5.2)
png 0.1-9 2026-03-15 [1] CRAN (R 4.5.2)
promises 1.5.0 2025-11-01 [1] CRAN (R 4.5.0)
proxy 0.4-29 2025-12-29 [1] CRAN (R 4.5.2)
purrr * 1.2.2 2026-04-10 [1] CRAN (R 4.5.2)
quantmod 0.4.28 2025-06-19 [1] CRAN (R 4.5.0)
R6 2.6.1 2025-02-15 [1] CRAN (R 4.5.0)
rappdirs 0.3.4 2026-01-17 [1] CRAN (R 4.5.2)
raster 3.6-32 2025-03-28 [1] CRAN (R 4.5.0)
RColorBrewer 1.1-3 2022-04-03 [1] CRAN (R 4.5.0)
Rcpp 1.1.1-1.1 2026-04-24 [1] CRAN (R 4.5.2)
readr * 2.2.0 2026-02-19 [1] CRAN (R 4.5.2)
rlang 1.2.0 2026-04-06 [1] CRAN (R 4.5.2)
rlist 0.4.6.2 2021-09-03 [1] CRAN (R 4.5.0)
rmarkdown 2.31 2026-03-26 [1] CRAN (R 4.5.2)
rnaturalearth 1.2.0 2026-01-19 [1] CRAN (R 4.5.2)
rnaturalearthhires 1.0.0.9000 2025-10-02 [1] Github (ropensci/rnaturalearthhires@e4736f6)
RPostgres 1.4.10 2026-02-16 [1] CRAN (R 4.5.2)
rprojroot 2.1.1 2025-08-26 [1] CRAN (R 4.5.0)
rstudioapi 0.18.0 2026-01-16 [1] CRAN (R 4.5.2)
S7 0.2.2 2026-04-22 [1] CRAN (R 4.5.2)
sass 0.4.10 2025-04-11 [1] CRAN (R 4.5.0)
satellite 1.0.6 2025-08-21 [1] CRAN (R 4.5.0)
scales 1.4.0 2025-04-24 [1] CRAN (R 4.5.0)
sessioninfo 1.2.3 2025-02-05 [1] CRAN (R 4.5.0)
sf * 1.1-1 2026-05-06 [1] CRAN (R 4.5.2)
shiny 1.13.0 2026-02-20 [1] CRAN (R 4.5.2)
shinyWidgets 0.9.1 2026-03-09 [1] CRAN (R 4.5.2)
snakecase 0.11.1 2023-08-27 [1] CRAN (R 4.5.0)
sp 2.2-1 2026-02-13 [1] CRAN (R 4.5.2)
stars 0.7-2 2026-04-03 [1] CRAN (R 4.5.2)
stringi 1.8.7 2025-03-27 [1] CRAN (R 4.5.0)
stringr * 1.6.0 2025-11-04 [1] CRAN (R 4.5.0)
terra 1.9-27 2026-05-10 [1] CRAN (R 4.5.2)
tibble * 3.3.1 2026-01-11 [1] CRAN (R 4.5.2)
tidyr * 1.3.2 2025-12-19 [1] CRAN (R 4.5.2)
tidyselect 1.2.1 2024-03-11 [1] CRAN (R 4.5.0)
timechange 0.4.0 2026-01-29 [1] CRAN (R 4.5.2)
TTR 0.24.4 2023-11-28 [1] CRAN (R 4.5.0)
tzdb 0.5.0 2025-03-15 [1] CRAN (R 4.5.0)
units * 1.0-1 2026-03-11 [1] CRAN (R 4.5.2)
usethis 3.2.1 2025-09-06 [1] CRAN (R 4.5.0)
utf8 1.2.6 2025-06-08 [1] CRAN (R 4.5.0)
uuid 1.2-2 2026-01-23 [1] CRAN (R 4.5.2)
V8 8.2.0 2026-04-21 [1] CRAN (R 4.5.2)
vctrs 0.7.3 2026-04-11 [1] CRAN (R 4.5.2)
viridisLite 0.4.3 2026-02-04 [1] CRAN (R 4.5.2)
visNetwork 2.1.4 2025-09-04 [1] CRAN (R 4.5.0)
vroom 1.7.1 2026-03-31 [1] CRAN (R 4.5.2)
withr 3.0.2 2024-10-28 [1] CRAN (R 4.5.0)
xfun 0.58 2026-06-01 [1] CRAN (R 4.5.2)
xtable 1.8-8 2026-02-22 [1] CRAN (R 4.5.2)
xts 0.14.2 2026-02-28 [1] CRAN (R 4.5.2)
yaml 2.3.12 2025-12-10 [1] CRAN (R 4.5.2)
zoo 1.8-15 2025-12-15 [1] CRAN (R 4.5.2)
[1] /Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library
* ── Packages attached to the search path.
P ── Loaded and on-disk path mismatch.
──────────────────────────────────────────────────────────────────────────────