---
title: "Ingest CalCOFI CTD Cast Data"
calcofi:
target_name: ingest_calcofi_ctd_cast
workflow_type: ingest
dependency:
- ingest_swfsc_ichthyo
output: data/parquet/calcofi_ctd-cast/manifest.json
modifies:
- ship
provider: calcofi
dataset: ctd-cast
workflow_url: https://calcofi.io/workflows/ingest_calcofi_ctd-cast.html
dataset_meta:
dataset_name: CalCOFI CTD Cast Files
description: >
CTD downcast profiles with temperature, salinity, oxygen, fluorescence,
and other sensors at standard depths.
citation_main: "CalCOFI. (2023). CalCOFI CTD Cast Files. CalCOFI.org."
link_calcofi_org: https://calcofi.org/data/oceanographic-data/ctd-cast-files/
link_data_source: https://calcofi.org/data/oceanographic-data/ctd-cast-files/
coverage_temporal: 1993-01 to 2021-05
coverage_spatial: "28-37°N, -125 to -117°W"
tables_owned:
- {table: ctd_cast}
- {table: ctd_thin}
- {table: ctd_measurement}
- {table: ctd_summary}
- {table: ctd_wide}
- {table: measurement_type, shared: true, note: "shared registry across bottle/ctd/dic"}
erd:
color: "#e0ccf0"
---
## Overview
This notebook ingests CalCOFI CTD data from <https://calcofi.org/data/oceanographic-data/ctd-cast-files/>, downloads and unzips **final** and **preliminary** CTD files, normalizes into tidy tables (`ctd_cast`, `ctd_measurement`, `ctd_thin`, `ctd_summary`), and exports to Parquet for the CalCOFI integrated database.
### Key Features
1. **Web Scraping**: Scrapes all CTD .zip download links from calcofi.org
2. **Smart Filtering**:
- Downloads all .zip files for archival completeness
- Only unzips `final` and `preliminary` files
- Skips raw/cast/test files
3. **Priority-based Selection**:
- For each cruise, selects final if available, otherwise preliminary
- Excludes raw/test/prodo cast files
4. **Tidy Normalization**:
- `ctd_cast`: one row per unique cast (cruise/station/direction)
- `ctd_measurement`: long-format sensor readings at each depth (supplemental)
- `ctd_thin`: adaptively-thinned `ctd_measurement` — single direction, canonical types, ~10 m grid with inflections preserved; the headline CTD table
- `ctd_summary`: summary stats per station/depth/measurement_type across cast directions
- `measurement_type`: reference table for measurement codes
5. **Standardized Workflow**: follows patterns from `ingest_calcofi_bottle.qmd` — deterministic UUIDs, GCS parquet uploads, metadata sidecars, calcofi4db utilities
## Setup
```{r}
#| label: setup
# chunk timing hook — prints elapsed time for each chunk
knitr::knit_hooks$set(time_it = function(before, options) {
if (before) {
.time_it_t0 <<- Sys.time()
} else {
elapsed <- round(difftime(Sys.time(), .time_it_t0, units = "secs"), 1)
tnow <- format(Sys.time(), "%H:%M:%S")
message(glue::glue("R chunk {options$label}: {elapsed}s ~ {tnow}"))
}
})
knitr::opts_chunk$set(time_it = TRUE)
devtools::load_all(here::here("../calcofi4db"))
devtools::load_all(here::here("../calcofi4r"))
librarian::shelf(
CalCOFI / calcofi4db,
CalCOFI / calcofi4r,
DBI,
dplyr,
DT,
fs,
glue,
here,
httr,
janitor,
lubridate,
mapview,
plotly,
purrr,
ps,
readr,
rvest,
sf,
stringr,
tibble,
tidyr,
zip,
quiet = T
)
# common ingest settings (overwrite, dir_data)
source(here("libs/ingest.R"))
# provider/dataset/metadata read from this file's authoritative YAML block
cc <- read_calcofi_meta(here("ingest_calcofi_ctd-cast.qmd"))
provider <- cc$provider
dataset <- cc$dataset
dataset_name <- cc$dataset_meta$dataset_name
tables_owned <- cc$tables_owned
dir_label <- glue("{provider}_{dataset}")
dir_dl <- path_expand(glue("{dir_data}/{provider}/{dataset}/download"))
dir_parquet <- here(glue("data/parquet/{dir_label}"))
db_path <- here(glue("data/wrangling/{dir_label}.duckdb"))
db_checkpoint <- here(glue("data/wrangling/{dir_label}_checkpoint.duckdb"))
dir_tmp <- here(glue("data/tmp/{dir_label}"))
url <- "https://calcofi.org/data/oceanographic-data/ctd-cast-files/"
dir_meta <- here(glue("metadata/{provider}/{dataset}"))
# overwrite: rebuild the wrangling DB, but keep checkpoint DB + downloads and
# (importantly) keep dir_parquet so write_parquet_outputs can content-hash
# dedup against the prior run — only changed partitions get re-written/uploaded.
# overwrite_all: also delete parquet, checkpoint DB, and RDS intermediates.
if (overwrite) {
if (file_exists(db_path)) file_delete(db_path)
# clear any stale WAL/tmp from an interrupted run so the restored checkpoint
# DB opens cleanly (avoids "WAL checkpoint iteration does not match" errors)
db_wal <- paste0(db_path, ".wal")
db_tmp <- paste0(db_path, ".tmp")
if (file_exists(db_wal)) file_delete(db_wal)
if (dir_exists(db_tmp)) dir_delete(db_tmp)
if (overwrite_all) {
if (dir_exists(dir_parquet)) dir_delete(dir_parquet)
if (file_exists(db_checkpoint)) file_delete(db_checkpoint)
rds_files <- list.files(dir_tmp, pattern = "\\.rds$", full.names = TRUE)
if (length(rds_files) > 0) file_delete(rds_files)
message("Deleted parquet, checkpoint DB, and RDS intermediates")
}
}
# restore from checkpoint DB if available (skips expensive read+bind+filter)
if (file_exists(db_checkpoint) && !file_exists(db_path)) {
file_copy(db_checkpoint, db_path, overwrite = TRUE)
message(glue("Restored from checkpoint: {db_checkpoint}"))
}
dir_create(c(dir_dl, dirname(db_path), dir_parquet, dir_tmp), recurse = TRUE)
con <- get_duckdb_con(db_path)
load_duckdb_extension(con, "spatial")
load_duckdb_extension(con, "icu")
# limit memory to half of system RAM so DuckDB spills to disk instead of consuming all RAM
mem_gb <- ps::ps_system_memory()$total / 1024^3 / 2 |> floor()
dbExecute(con, glue("SET memory_limit = '{mem_gb}GB'"))
dbExecute(con, glue("SET temp_directory = '{dir_tmp}'"))
# source archival handled by sync_gd_to_gcs.qmd (rclone)
# the ctd-cast download/ dir is 62GB+ — too large for inline
# sync_to_gcs() through the GD FUSE mount
# load metadata
d_meas_type <- read_csv(
here("metadata/measurement_type.csv"),
show_col_types = F
)
d_flds_rd <- read_csv(glue("{dir_meta}/flds_redefine.csv"), show_col_types = F)
d_tbls_rd <- read_csv(glue("{dir_meta}/tbls_redefine.csv"), show_col_types = F)
d_cruise_corrections <- read_csv(
glue("{dir_meta}/cruise_key_corrections.csv"), show_col_types = F)
```
## Check for Resumable State
```{r}
#| label: check_resume
# detect if parquet outputs are already complete (e.g. prior run failed
# only during GCS upload). If overwrite=TRUE, always rebuild.
parquet_complete <- FALSE
manifest_path <- file.path(dir_parquet, "manifest.json")
if (file_exists(manifest_path)) {
mf <- jsonlite::read_json(manifest_path)
expected <- setdiff(mf$tables, unlist(mf$supplemental))
parquet_ok <- all(vapply(expected, function(tbl) {
p <- file.path(dir_parquet, paste0(tbl, ".parquet"))
d <- file.path(dir_parquet, tbl)
file_exists(p) || dir_exists(d)
}, logical(1)))
if (parquet_ok && !overwrite) {
parquet_complete <- TRUE
message(glue(
"Parquet output already complete ({length(mf$tables)} tables, ",
"{format(mf$total_rows, big.mark = ',')} rows) — ",
"skipping computation, resuming at upload"))
}
}
# if parquet not complete, check for checkpoint (ctd_raw pre-computed)
has_ctd_raw <- FALSE
if (!parquet_complete) {
has_ctd_raw <- "ctd_raw" %in% DBI::dbListTables(con)
if (has_ctd_raw) {
n_raw <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_raw")$n
message(glue(
"Checkpoint: ctd_raw already loaded ",
"({format(n_raw, big.mark = ',')} rows) — ",
"skipping read+bind+filter"))
}
}
# set eval for read+bind+filter chunks
skip_read_bind <- parquet_complete || has_ctd_raw
knitr::opts_chunk$set(eval = !skip_read_bind)
```
## Scrape CTD Download Links
```{r}
#| label: d_zips
# read web page, extract all .zip download links; cache to CSV
cache_csv <- file.path(dir_meta, "ctd_zip_urls.csv")
d_zips <- tryCatch(
{
d <- read_html(url) |>
html_nodes("a[href$='.zip']") |>
html_attr("href") |>
tibble(url = _) |>
mutate(
url = if_else(
str_starts(url, "http"),
url,
paste0("https://calcofi.org", url)
),
file_zip = basename(url),
year = str_extract(url, "/(\\d{4})/", group = 1) |> as.integer(),
month = str_extract(url, "-\\d{2}(\\d{2})", group = 1) |> as.integer(),
cruise_key = str_extract(
file_zip,
"\\d{2}-(\\d{4}[A-Z0-9]{2,4})",
group = 1
),
zip_type = case_when(
str_detect(file_zip, "CTDFinal") ~ "final",
str_detect(file_zip, "CTDPrelim") ~ "preliminary",
str_detect(file_zip, "CTDCast|CTD_Cast") ~ "raw",
str_detect(file_zip, "CTDTest") ~ "test",
TRUE ~ "unknown"
)
)
write_csv(d, cache_csv)
message(glue("Scraped {nrow(d)} zip URLs from {url}"))
d
},
error = function(e) {
if (file_exists(cache_csv)) {
message(glue("Website unavailable, using cached URLs from {cache_csv}"))
read_csv(cache_csv, show_col_types = FALSE)
} else {
stop(e)
}
}
)
stopifnot(!any(d_zips$zip_type == "unknown"))
d_zips |>
mutate(
file_zip = glue("<a href={url}>{file_zip}</a>")
) |>
select(-url) |>
dt(
caption = "All zip files to download",
fname = "ctd_zip_files",
escape = F
)
```
## Prime Downloads from GCS Source (optional)
The authoritative source for the CTD `.zip` files is the organization Shared Drive
("CalCOFI Data Folder"), mirrored to
`gs://calcofi-files-public/_sync/calcofi/ctd-cast/download/` by
`scripts/sync_gdrive_to_gcs.sh`. If that source exposes zips, copy them into
`dir_dl` so the next chunk simply unzips them rather than re-scraping calcofi.org.
This is a no-op (falls back to calcofi.org) until the GCS source is populated; set
`CTD_ZIP_SOURCE=""` to disable, or override it to point elsewhere.
```{r}
#| label: prime_zips_from_gcs
# authoritative zip source (gdrive→gcs); empty string disables priming
ctd_zip_source <- Sys.getenv(
"CTD_ZIP_SOURCE",
"gcs-calcofi:calcofi-files-public/_sync/calcofi/ctd-cast/download")
prime_zips_from_gcs <- function(src, dest_dir) {
# skip if disabled or rclone unavailable
if (src == "" || Sys.which("rclone") == "")
return(invisible(0L))
# only act if the source actually exposes zips (else fall back to scraping)
n_src <- tryCatch(
length(system2(
"rclone", c("lsf", src, "--include", "*.zip", "--max-depth", "1"),
stdout = TRUE, stderr = FALSE)),
error = function(e) 0L)
if (n_src == 0) {
message(glue("No zips at {src} — skipping GCS prime (will use calcofi.org)"))
return(invisible(0L))
}
message(glue("Priming {n_src} zip(s) from {src} → {dest_dir}"))
system2("rclone", c(
"copy", src, dest_dir,
"--include", "*.zip", "--max-depth", "1",
"--transfers", "8", "--checkers", "16"))
invisible(n_src)
}
prime_zips_from_gcs(ctd_zip_source, dir_dl)
```
## Download and Unzip Files
```{r}
#| label: download_and_unzip
download_and_unzip <- function(url, dest_dir, zip_type, unzip = TRUE) {
file_zip <- basename(url)
dest_file <- file.path(dest_dir, file_zip)
dir_unzip <- file.path(dest_dir, str_remove(file_zip, "\\.zip$"))
if (file_exists(dest_file)) {
message(glue("Already exists: {file_zip}"))
} else {
message(glue("Downloading: {file_zip}"))
tryCatch(
download.file(url, dest_file, mode = "wb"),
error = function(e) {
warning(glue("Failed to download {file_zip}: {e$message}"))
if (file_exists(dest_file)) {
file_delete(dest_file)
}
return(invisible(NULL))
}
)
if (!file_exists(dest_file)) return(invisible(NULL))
}
if (unzip && dir_exists(dir_unzip)) {
message(glue("Already unzipped: {file_zip}"))
} else {
if (zip_type %in% c("final", "preliminary")) {
message(glue("Unzipping: {file_zip}"))
dir_create(dir_unzip, recurse = TRUE)
unzip(dest_file, exdir = dir_unzip)
} else if (unzip) {
message(glue("Skipping unzip (not final/preliminary): {file_zip}"))
}
}
}
d_zips |>
pwalk(function(url, file_zip, zip_type, ...) {
download_and_unzip(url, dir_dl, zip_type, unzip = TRUE)
})
message("Download and extraction complete!")
```
## Find and Prioritize CTD Data Files
```{r}
#| label: d_csv
d_csv <- tibble(
path = list.files(
dir_dl,
pattern = "\\.csv$",
recursive = TRUE,
full.names = TRUE
)
) |>
mutate(
file_csv = basename(path),
path_unzip = str_replace(path, glue("{dir_dl}/"), ""),
dir_unzip = str_extract(path_unzip, "^[^/]+"),
cruise_key = str_extract(
path_unzip,
"\\d{2}-(\\d{4}[A-Z0-9]{2,4})_.*",
group = 1
),
data_stage = case_when(
str_detect(path_unzip, "Final.*db[_|-]csv") ~ "final",
str_detect(path_unzip, "Prelim.*db[_|-]csv") ~ "preliminary",
# prelim CSVs directly in unzipped dir (no db-csv subfolder)
str_detect(dir_unzip, "Prelim") &
path_unzip == paste0(dir_unzip, "/", file_csv) ~ "preliminary",
# edge case: 2111SR has CSVs only in csvs-plots subfolder
cruise_key == "2111SR" &
str_detect(
path_unzip,
"Prelim.*csvs-plots.*2111SR.*csv"
) ~ "preliminary",
.default = NA_character_
),
cast_dir = case_when(
str_detect(file_csv, regex("U\\.csv$", ignore_case = T)) ~ "U",
str_detect(file_csv, regex("D\\.csv$", ignore_case = T)) ~ "D"
),
priority = case_when(
data_stage == "final" ~ 1,
data_stage == "preliminary" ~ 2,
TRUE ~ 3
)
) |>
relocate(cruise_key, path_unzip) |>
arrange(cruise_key, path_unzip) |>
filter(data_stage %in% c("final", "preliminary"))
# for each cruise, keep only final if available, otherwise preliminary
d_priority <- d_csv |>
group_by(cruise_key) |>
summarize(
best_priority = min(priority),
.groups = "drop"
)
d_csv <- d_csv |>
inner_join(d_priority, by = "cruise_key") |>
filter(priority == best_priority) |>
select(-best_priority)
cruises_csv_notzip <- setdiff(
unique(d_csv$cruise_key),
unique(d_zips$cruise_key)
) |>
sort()
stopifnot(length(cruises_csv_notzip) == 0)
cruises_zip_notcsv <- setdiff(
unique(d_zips$cruise_key),
unique(d_csv$cruise_key)
) |>
sort()
d_csv |>
select(-any_of(c("path", "data", "col_empties", "col_types"))) |>
relocate(cruise_key, path_unzip) |>
arrange(cruise_key, path_unzip) |>
dt(
caption = "Files to Ingest",
fname = "ctd_files_to_ingest"
)
```
## Read and Standardize CTD Files
Remove repeat header rows that can occur within files.
```{r}
#| label: read_csv
d_csv <- d_csv |>
arrange(basename(path)) |>
mutate(
data = map2(path, seq_along(path), \(path, idx) {
message(glue("Reading {idx}/{nrow(d_csv)}: {basename(path)}"))
all_lines <- read_lines(path)
header_line <- all_lines[1]
# find repeat header rows (excluding row 1)
repeat_header_rows <- which(all_lines[-1] == header_line)
if (length(repeat_header_rows) > 0) {
all_lines <- all_lines[-(repeat_header_rows + 1)]
tmp_file <- tempfile(fileext = ".csv")
write_lines(all_lines, tmp_file)
data <- read_csv(tmp_file, guess_max = Inf, show_col_types = F) |>
clean_names()
file_delete(tmp_file)
} else {
data <- read_csv(path, guess_max = Inf, show_col_types = F) |>
clean_names()
}
data
}),
nrows = map_int(data, ~ if (is.null(.x)) 0 else nrow(.x))
)
d_csv |>
arrange(cruise_key, file_csv) |>
select(cruise_key, file_csv, nrows) |>
dt(
caption = "Number of rows read per file",
fname = "ctd_rows_per_file"
) |>
formatCurrency("nrows", currency = "", digits = 0, mark = ",")
```
## Detect and Correct Column Type Mismatches
```{r}
#| label: d_bind
d_csv <- d_csv |>
mutate(
col_empties = map(data, \(x) {
tibble(
col_name = names(x),
n_empty = map_int(x, \(col) sum(is.na(col)))
) |>
filter(n_empty == nrow(x)) |>
pull(col_name)
}),
col_types = map2(data, col_empties, \(x, y) {
tibble(
col_name = names(x),
col_type = map_chr(x, \(col) class(col)[1])
) |>
filter(!col_name %in% y)
})
)
# find most common type for each column across all files
d_types <- d_csv |>
select(path, col_types) |>
unnest(col_types) |>
count(col_name, col_type) |>
group_by(col_name) |>
slice_max(n, n = 1, with_ties = FALSE) |>
ungroup() |>
select(col_name, expected_type = col_type)
d_mismatches <- d_csv |>
select(cruise_key, path, col_types) |>
unnest(col_types) |>
left_join(d_types, by = "col_name") |>
filter(col_type != expected_type) |>
arrange(col_name, path)
if (nrow(d_mismatches) > 0) {
message("Type mismatches detected - converting columns...")
}
# bind data, converting mismatched columns to expected type
d_bind <- d_csv |>
mutate(
data = map2(data, path, \(x, p) {
x_mismatches <- d_mismatches |>
filter(path == p)
if (nrow(x_mismatches) > 0) {
for (i in 1:nrow(x_mismatches)) {
col <- x_mismatches$col_name[i]
expected <- x_mismatches$expected_type[i]
na_before <- sum(is.na(x[[col]]))
suppressWarnings({
x[[col]] <- switch(
expected,
"numeric" = as.numeric(x[[col]]),
"integer" = as.integer(x[[col]]),
"logical" = as.logical(x[[col]]),
"character" = as.character(x[[col]]),
x[[col]]
)
})
na_after <- sum(is.na(x[[col]]))
na_generated <- na_after - na_before
if (na_generated > 0) {
message(glue(
" {basename(p)}: {col} ({x_mismatches$col_type[i]} -> {expected}) generated {na_generated} NAs"
))
}
d_mismatches[
d_mismatches$path == p & d_mismatches$col_name == col,
"nas_generated"
] <<- na_generated
}
}
x
})
) |>
unnest(data)
if (nrow(d_mismatches) > 0) {
d_mismatches |>
group_by(col_name, expected_type, col_type) |>
summarize(
n_files = n(),
total_nas = sum(nas_generated, na.rm = TRUE),
files = paste(basename(path), collapse = "; "),
.groups = "drop"
) |>
arrange(desc(total_nas)) |>
dt(
caption = "Type mismatches by column",
fname = "ctd_type_mismatches_by_column"
) |>
formatCurrency(
c("n_files", "total_nas"),
currency = "",
digits = 0,
mark = ","
)
}
# reconcile cruise_key from study where mismatched
d_bind <- d_bind |>
mutate(
cruise_key = if_else(
!is.na(study) &
cruise_key != study &
study != "Study",
study,
cruise_key
),
`_source_file` = path_unzip
) |>
relocate(`_source_file`, .after = cruise_key) |>
select(
-path_unzip,
-path,
-file_csv,
-dir_unzip,
-priority,
-project,
-study,
-nrows,
-col_empties,
-col_types
)
# fill missing ord_occ from cast_id
d_bind <- d_bind |>
mutate(
ord_occ = if_else(
is.na(ord_occ) & !is.na(cast_id),
str_extract(cast_id, "_(\\d{3})", group = 1),
ord_occ
)
)
# normalize raw coordinate column names (CalCOFI CTD CSV ships Lon_Dec/Lat_Dec ->
# clean_names lon_dec/lat_dec) to the canonical dictionary names used downstream
d_bind <- d_bind |>
rename(longitude = lon_dec, latitude = lat_dec)
# save intermediate for resumability
write_rds(d_bind, glue("{dir_tmp}/d_bind_pre_datetime.rds"), compress = "gz")
```
## Format Date-Time Column
```{r}
#| label: format_datetime
d_bind <- read_rds(glue("{dir_tmp}/d_bind_pre_datetime.rds"))
d_bind <- d_bind |>
mutate(
date_time_utc = trimws(date_time_utc),
date_time_format = case_when(
str_detect(
date_time_utc,
"^\\d{1,2}-[A-z]{3}-\\d{4} \\d{1,2}:\\d{1,2}:\\d{1,2}$"
) ~ "dmy_hms",
str_detect(
date_time_utc,
"^\\d{1,2}/\\d{1,2}/\\d{4} \\d{1,2}:\\d{1,2}$"
) ~ "mdy_hm",
TRUE ~ "unknown"
),
datetime_start_utc = NA,
datetime_start_utc = if_else(
date_time_format == "dmy_hms",
suppressWarnings(dmy_hms(date_time_utc, tz = "UTC")),
datetime_start_utc
),
datetime_start_utc = if_else(
date_time_format == "mdy_hm",
suppressWarnings(mdy_hm(date_time_utc, tz = "UTC")),
datetime_start_utc
)
) |>
relocate(date_time_format, datetime_start_utc, .after = date_time_utc) |>
arrange(datetime_start_utc, depth)
stopifnot(all(!is.na(d_bind$datetime_start_utc)))
write_rds(d_bind, glue("{dir_tmp}/d_bind_post_datetime.rds"), compress = "gz")
d_bind |>
group_by(cruise_key, `_source_file`, date_time_format) |>
summarize(
n_records = n(),
datetime_min = min(datetime_start_utc),
datetime_max = max(datetime_start_utc),
.groups = "drop"
) |>
arrange(cruise_key, `_source_file`, date_time_format) |>
pivot_wider(
names_from = date_time_format,
values_from = n_records,
values_fill = NA_real_
) |>
relocate(dmy_hms, mdy_hm, .after = cruise_key) |>
dt(
caption = "Date-Time formats detected by cruise_key and source_file",
fname = "ctd_datetime_formats"
) |>
formatDate(c("datetime_min", "datetime_max"), method = "toLocaleString")
```
## Pseudo-NA Values and Fill Missing Coordinates
```{r}
#| label: fill_lonlat
d_bind <- read_rds(glue("{dir_tmp}/d_bind_post_datetime.rds"))
pseudoNA_values <- c(-9.99e-29, -99)
d_bind <- d_bind |>
mutate(
is_lnsta_pseudoNA = ifelse(
as.numeric(line) == 0 & as.numeric(sta) == 0,
TRUE,
FALSE
),
is_lon_pseudoNA = map_lgl(longitude, ~ some(pseudoNA_values, near, .x)),
is_lat_pseudoNA = map_lgl(latitude, ~ some(pseudoNA_values, near, .x)),
longitude = if_else(
is_lon_pseudoNA | is_lat_pseudoNA,
NA_real_,
longitude
),
latitude = if_else(
is_lon_pseudoNA | is_lat_pseudoNA,
NA_real_,
latitude
),
lon_lnst = if_else(
!is.na(line) & !is.na(sta) & !is_lnsta_pseudoNA,
as.numeric(sf_project(
from = "+proj=calcofi",
to = "+proj=longlat +datum=WGS84",
pts = cbind(x = as.numeric(line), y = as.numeric(sta))
)[, 1]),
NA_real_
),
lat_lnst = if_else(
!is.na(line) & !is.na(sta) & !is_lnsta_pseudoNA,
as.numeric(sf_project(
from = "+proj=calcofi",
to = "+proj=longlat +datum=WGS84",
pts = cbind(x = as.numeric(line), y = as.numeric(sta))
)[, 2]),
NA_real_
),
longitude = if_else(is.na(longitude), lon_lnst, longitude),
latitude = if_else(is.na(latitude), lat_lnst, latitude)
)
stopifnot(sum(is.na(d_bind$longitude)) == 0)
stopifnot(sum(is.na(d_bind$latitude)) == 0)
d_bind |>
filter(is_lon_pseudoNA | is_lat_pseudoNA) |>
group_by(cruise_key) |>
summarize(
n_lon_pseudoNA = sum(is_lon_pseudoNA),
n_lat_pseudoNA = sum(is_lat_pseudoNA)
) |>
dt(
caption = glue(
"Cruises with pseudo-NAs ({paste(pseudoNA_values, collapse = ',')}) ",
"set to NA, then filled from line/station coordinates."
),
fname = "ctd_cruises_pseudoNA_lonlat"
) |>
formatCurrency(
c("n_lon_pseudoNA", "n_lat_pseudoNA"),
currency = "",
digits = 0,
mark = ","
)
```
## Distance Filtering
```{r}
#| label: pts_distance_from_lnst
max_dist_dec_lnst_km <- 10
pts <- d_bind |>
st_as_sf(coords = c("longitude", "latitude"), remove = F, crs = 4326) |>
mutate(
geom_lnst = purrr::map2(lon_lnst, lat_lnst, \(x, y) st_point(c(x, y))) |>
st_sfc(crs = 4326),
dist_dec_lnst_km = st_distance(geometry, geom_lnst, by_element = T) |>
units::set_units(km) |>
units::drop_units(),
is_dist_dec_lnst_within_max = dist_dec_lnst_km <= max_dist_dec_lnst_km
) |>
st_join(
calcofi4r::cc_grid |>
rename(any_of(c(site_key = "sta_key"))) |>
select(grid_site = site_key),
join = st_intersects
)
st_agr(pts) <- "constant"
```
### View sample cruise with excess distance points
```{r}
#| label: view_badcr
badcr_id <- "1507OC"
pts_badcr <- pts |>
filter(cruise_key == badcr_id)
bb_badcr <- st_bbox(pts_badcr) |> st_as_sfc()
mapView(bb_badcr) +
mapView(
pts_badcr |>
filter(is_dist_dec_lnst_within_max) |>
slice_sample(n = 1000) |>
bind_rows(
pts_badcr |>
filter(!is_dist_dec_lnst_within_max)
) |>
select(
cruise_key,
datetime_start_utc,
longitude,
latitude,
sta_id,
line,
sta,
dist_dec_lnst_km,
is_dist_dec_lnst_within_max
),
layer.name = glue(
"Cruise {badcr_id}<br>distance (km)<br>lon/lat to line/station"
),
zcol = "dist_dec_lnst_km",
cex = 5,
alpha = 0.5
)
```
### Filter points
```{r}
#| label: filter_pts
d_pts_cruise_filt_smry <- pts |>
st_drop_geometry() |>
group_by(cruise_key) |>
filter(any(!is_dist_dec_lnst_within_max)) |>
summarize(
n_all = n(),
n_outside_grid = sum(is.na(grid_site)),
pct_outside_grid = n_outside_grid / n_all,
n_gt_cutoff = sum(!is_dist_dec_lnst_within_max, na.rm = T),
avg_dist_gt_cutoff_km = if_else(
n_gt_cutoff > 0,
mean(dist_dec_lnst_km[!is_dist_dec_lnst_within_max], na.rm = T),
NA_real_
),
pct_gt_cutoff = n_gt_cutoff / n_all,
n_rm = sum(!is_dist_dec_lnst_within_max | is.na(grid_site), na.rm = T),
pct_rm = n_rm / n_all,
.groups = "drop"
) |>
filter(n_rm > 0) |>
arrange(desc(pct_rm))
pts_filt <- pts |>
filter(
is_dist_dec_lnst_within_max,
!is.na(grid_site)
)
d_pts_cruise_filt_smry |>
dt(
caption = glue(
"Cruises with rows filtered: outside CalCOFI grid or exceeded ",
"{max_dist_dec_lnst_km} km cutoff from line/station coordinates."
),
escape = F,
fname = "ctd_cruises_distance_from_lnst"
) |>
formatCurrency(
c(
"n_all",
"n_gt_cutoff",
"avg_dist_gt_cutoff_km",
"n_outside_grid",
"n_rm"
),
currency = "",
digits = 0,
mark = ","
) |>
formatPercentage(
c("pct_gt_cutoff", "pct_outside_grid", "pct_rm"),
digits = 2
)
```
### View filtered points
```{r}
#| label: view_pts_filt
bb_cr <- st_bbox(pts_filt) |> st_as_sfc()
mapView(bb_cr) +
mapView(
pts_filt |>
group_by(cruise_key) |>
slice_sample(n = 100) |>
ungroup() |>
select(
cruise_key,
longitude,
latitude,
sta_id,
line,
sta,
dist_dec_lnst_km,
datetime_start_utc
),
zcol = "cruise_key",
cex = 5,
alpha = 0.5
)
```
### Check for duplicates by datetime and depth
```{r}
#| label: check_dupes
d_dupes <- pts_filt |>
st_drop_geometry() |>
select(datetime_start_utc, depth) |>
group_by(datetime_start_utc, depth) |>
summarize(n = n(), .groups = "drop") |>
filter(n > 1) |>
arrange(desc(n))
n_distinct_dtime_depth <- pts_filt |>
st_drop_geometry() |>
select(datetime_start_utc, depth) |>
n_distinct()
d_dupes |>
slice(c(1:10, (n() - 9):n())) |>
dt(
caption = glue(
"First and last 10 duplicates by datetime_start_utc, depth ",
"(nrows = {format(nrow(d_dupes), big.mark = ',')}; ",
"n_distinct = {format(n_distinct_dtime_depth, big.mark = ',')})"
),
fname = "ctd_duplicates_by_datetime_depth"
)
```
## Rename Fields
Apply field renames from `flds_redefine.csv`.
```{r}
#| label: rename_fields
# apply column renames from flds_redefine
renames <- d_flds_rd |>
filter(fld_old != fld_new) |>
select(fld_old, fld_new)
d_filt <- pts_filt |>
st_drop_geometry() |>
select(-geom_lnst)
for (i in seq_len(nrow(renames))) {
old <- renames$fld_old[i]
new <- renames$fld_new[i]
if (old %in% names(d_filt)) {
d_filt <- d_filt |> rename(!!new := !!old)
}
}
# drop intermediate columns
d_filt <- d_filt |>
select(
-any_of(c(
"date_time_pst",
"date_time_utc",
"date_time_format",
"is_lon_pseudoNA",
"is_lat_pseudoNA",
"is_lnsta_pseudoNA",
"lon_lnst",
"lat_lnst",
"dist_dec_lnst_km",
"is_dist_dec_lnst_within_max",
"grid_site"
))
)
# write raw table for pivoting
dbWriteTable(con, "ctd_raw", d_filt, overwrite = TRUE)
message(glue("Loaded {nrow(d_filt)} rows into ctd_raw"))
```
## De-duplicate ctd_raw
Some cruises ship the same casts twice in the download archive — a primary copy plus a reorganized copy in a sub-folder (e.g. `db_csvs/` alongside `db_csvs/south-north/`), both classified `final` by the path regex, so both pass the priority filter (see the duplicates reported above). The copies are identical except for re-rounded coordinates (and occasionally a re-processed measurement value). Collapse to one row per measurement position so the deterministic UUIDs downstream (`ctd_cast_uuid`, `ctd_measurement_uuid`, …) are unique.
```{r}
#| label: dedup_ctd_raw
raw_cols <- dbGetQuery(
con,
"SELECT column_name FROM information_schema.columns WHERE table_name = 'ctd_raw'"
)$column_name
# a measurement position is identified by these five columns; duplicate copies
# share all five and differ only in re-rounded coordinates / re-processed values
dedup_key <- c("cruise_key", "cast_key", "cast_dir", "datetime_start_utc", "depth_m")
stopifnot(
"ctd_raw missing expected columns for de-duplication" =
all(c(dedup_key, "_source_file", "latitude", "longitude") %in% raw_cols))
# keep the primary copy: reorganized duplicates sit in deeper source paths, so
# prefer the shortest `_source_file`; coordinates tie-break for full determinism
n_before <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_raw")$n
dbExecute(con, glue("
CREATE OR REPLACE TABLE ctd_raw AS
SELECT * FROM ctd_raw
QUALIFY ROW_NUMBER() OVER (
PARTITION BY {paste(dedup_key, collapse = ', ')}
ORDER BY length(\"_source_file\"), \"_source_file\", latitude, longitude) = 1"))
n_after <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_raw")$n
cat(glue(
"ctd_raw de-duplicated: removed {format(n_before - n_after, big.mark = ',')} ",
"duplicate-position rows ",
"({round(100 * (n_before - n_after) / max(n_before, 1), 1)}%); ",
"{format(n_after, big.mark = ',')} rows remain"), "\n")
```
```{r}
#| label: restore_eval
#| eval: true
# must always evaluate: line ~217 may have set eval=FALSE to skip read+bind
# when restoring from checkpoint; this chunk re-enables computation through
# write_parquet. without `eval: true` it would inherit eval=FALSE and be
# skipped, so write_parquet never runs yet downstream chunks expect its output.
if (parquet_complete) {
knitr::opts_chunk$set(eval = FALSE)
message("Parquet complete — skipping to upload")
} else {
knitr::opts_chunk$set(eval = TRUE)
}
```
## Cross-Dataset Bridge
Load reference tables (ship, cruise, grid) from the ichthyo ingest, derive `ship_key`, and validate against known ships/cruises.
```{r}
#| label: cross_dataset_bridge
# tables declared in calcofi.modifies — loaded as TABLEs (writable)
modifies_tables <- c("ship") # from calcofi.modifies in YAML frontmatter
load_prior_tables(
con = con,
tables = modifies_tables,
parquet_dir = here("data/parquet/swfsc_ichthyo")
)
# cruise + grid as VIEWs (read-only: cruise used for JOIN, grid for assign_grid_key)
load_prior_tables(
con = con,
tables = c("cruise", "grid"),
parquet_dir = here("data/parquet/swfsc_ichthyo"),
as_view = TRUE
)
# snapshot PKs of modified tables before modifications
modifies_pks <- list()
for (tbl in modifies_tables) {
pk_col <- dbGetQuery(con, glue(
"SELECT column_name FROM information_schema.columns
WHERE table_name = '{tbl}' ORDER BY ordinal_position LIMIT 1"))$column_name
modifies_pks[[tbl]] <- list(
pk_col = pk_col,
keys = dbGetQuery(con, glue("SELECT {pk_col} FROM {tbl}"))[[1]])
}
# apply cruise_key corrections for known study-column data quality errors.
# runs unconditionally so it fires for both fresh runs (YYMMKK keys) and
# checkpoint-restored runs (already-converted YYYY-MM-NODC keys).
for (i in seq_len(nrow(d_cruise_corrections))) {
n_wrong <- dbGetQuery(con, glue(
"SELECT COUNT(*) AS n FROM ctd_raw
WHERE cruise_key = '{d_cruise_corrections$cruise_key_raw[i]}'"))$n
if (n_wrong > 0) {
dbExecute(con, glue(
"UPDATE ctd_raw SET cruise_key = '{d_cruise_corrections$cruise_key_correct[i]}'
WHERE cruise_key = '{d_cruise_corrections$cruise_key_raw[i]}'"))
message(glue(
"cruise_key correction: {d_cruise_corrections$cruise_key_raw[i]} → ",
"{d_cruise_corrections$cruise_key_correct[i]} ({format(n_wrong, big.mark=',')} rows)"))
}
}
# detect whether cruise_key already in YYYY-MM-NODC format (from checkpoint)
sample_ck <- dbGetQuery(
con, "SELECT cruise_key FROM ctd_raw LIMIT 1")$cruise_key
cruise_key_already_converted <- grepl("^\\d{4}-\\d{2}-", sample_ck)
if (!cruise_key_already_converted) {
# 0404NHJD is a combined New Horizon + Jordan Davis cruise; use primary ship NH
dbExecute(
con,
"UPDATE ctd_raw SET cruise_key = LEFT(cruise_key, 6)
WHERE LENGTH(cruise_key) > 6"
)
# derive ship_key from last 2 chars of cruise_key (YYMMKK format from filename)
dbExecute(con, "ALTER TABLE ctd_raw ADD COLUMN IF NOT EXISTS ship_key VARCHAR")
dbExecute(con, "UPDATE ctd_raw SET ship_key = RIGHT(cruise_key, 2)")
# validate ship_key against ship reference table
ctd_ships <- dbGetQuery(con, "SELECT DISTINCT ship_key FROM ctd_raw")
ref_ships <- dbGetQuery(con, "SELECT ship_key FROM ship")
orphan_ships <- setdiff(ctd_ships$ship_key, ref_ships$ship_key)
if (length(orphan_ships) > 0) {
message(glue(
"{length(orphan_ships)} ship_key(s) in CTD not in ship table: ",
"{paste(orphan_ships, collapse = ', ')}"
))
# run match_ships() with centralized renames for orphan ships
orphan_tbl <- dbGetQuery(con, glue(
"SELECT DISTINCT ship_key AS ship_code, NULL AS ship_name
FROM ctd_raw
WHERE ship_key IN ({paste(shQuote(orphan_ships, type = 'sh'), collapse = ', ')})")) |>
mutate(ship_name = as.character(ship_name))
ship_result <- match_ships(
unmatched_ships = orphan_tbl,
reference_ships = dbReadTable(con, "ship"),
ship_renames_csv = here("metadata/ship_renames.csv"),
fetch_ices = FALSE)
# insert interim entries for still-unmatched ships (ship_nodc = "?XX?")
ensure_interim_ships(con, ship_result)
dbGetQuery(
con,
glue(
"SELECT ship_key, COUNT(DISTINCT cruise_key) AS n_cruises,
COUNT(*) AS n_rows
FROM ctd_raw
WHERE ship_key IN ({paste(shQuote(orphan_ships, type = 'sh'), collapse = ', ')})
GROUP BY ship_key
ORDER BY ship_key"
)
) |>
dt(
caption = "Orphan ship_keys (in CTD but not in ship table)",
fname = "ctd_orphan_ship_keys"
)
} else {
message("All CTD ship_keys found in ship reference table")
}
# convert cruise_key from YYMMKK → YYYY-MM-NODC format
convert_cruise_key_format(con, "ctd_raw", old_key_col = "cruise_key")
dbExecute(con, "ALTER TABLE ctd_raw DROP COLUMN cruise_key")
dbExecute(con, "ALTER TABLE ctd_raw RENAME COLUMN cruise_key_new TO cruise_key")
} else {
message("cruise_key already in YYYY-MM-NODC format (from checkpoint)")
}
# validate cruise_key against cruise reference table
ctd_cruises <- dbGetQuery(con, "SELECT DISTINCT cruise_key FROM ctd_raw")
ref_cruises <- dbGetQuery(con, "SELECT cruise_key FROM cruise")
orphan_cruises <- setdiff(ctd_cruises$cruise_key, ref_cruises$cruise_key)
if (length(orphan_cruises) > 0) {
message(glue(
"{length(orphan_cruises)} cruise_key(s) in CTD not in cruise table: ",
"{paste(head(orphan_cruises, 10), collapse = ', ')}",
"{if (length(orphan_cruises) > 10) '...' else ''}"
))
dbGetQuery(
con,
glue(
"SELECT cruise_key, COUNT(*) AS n_rows
FROM ctd_raw
WHERE cruise_key IN ({paste(shQuote(orphan_cruises, type = 'sh'), collapse = ', ')})
GROUP BY cruise_key
ORDER BY cruise_key"
)
) |>
dt(
caption = "Orphan cruise_keys (in CTD but not in cruise table)",
fname = "ctd_orphan_cruise_keys"
)
} else {
message("All CTD cruise_keys found in cruise reference table")
}
```
## Save Checkpoint
Save a DuckDB checkpoint after the expensive read+bind+filter+bridge steps so subsequent runs can resume from here.
```{r}
#| label: save_checkpoint
if (!file_exists(db_checkpoint) || overwrite) {
close_duckdb(con)
file_copy(db_path, db_checkpoint, overwrite = TRUE)
con <- get_duckdb_con(db_path)
load_duckdb_extension(con, "spatial")
load_duckdb_extension(con, "icu")
message(glue("Saved checkpoint: {db_checkpoint}"))
} else {
message(glue("Checkpoint already exists: {db_checkpoint}"))
}
```
## Wide-Format Output (for ERDDAP)
Create a wide-format table preserving the original column layout for serving into ERDDAP. This is a supplemental output — not part of the normalized database.
```{r}
#| label: ctd_wide
# identify measurement and quality columns from measurement_type metadata
d_meas_ctd <- d_meas_type |>
filter(str_detect(`_source_datasets`, "calcofi_ctd-cast"))
meas_cols <- d_meas_ctd$`_source_column`
qual_cols <- d_meas_ctd$`_qual_column` |> na.omit() |> as.character()
qual_cols <- qual_cols[qual_cols != ""]
# get raw columns
raw_cols <- dbGetQuery(
con,
"SELECT column_name FROM information_schema.columns WHERE table_name = 'ctd_raw'"
)$column_name
# wide-format: cast metadata + depth + all measurement/quality columns
# exclude provenance and intermediate columns
wide_keep <- intersect(
raw_cols,
c("cruise_key", "site_key", "cast_key", "cast_dir",
"datetime_start_utc", "longitude", "latitude", "ship_key",
"data_stage", "depth_m", meas_cols, qual_cols))
dbExecute(
con,
glue(
"CREATE OR REPLACE TABLE ctd_wide AS
SELECT {paste(wide_keep, collapse = ', ')}
FROM ctd_raw
ORDER BY cruise_key, site_key, cast_dir, depth_m")
)
n_wide <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_wide")$n
message(glue("ctd_wide: {format(n_wide, big.mark = ',')} rows (supplemental, for ERDDAP)"))
```
## Split into Tidy Tables
### ctd_cast — cast-level metadata
```{r}
#| label: ctd_cast
# d_meas_ctd, meas_cols, qual_cols already defined in ctd_wide chunk above
# use ctd_raw columns (includes ship_key and data_stage added via SQL)
raw_cols <- dbGetQuery(
con,
"SELECT column_name FROM information_schema.columns WHERE table_name = 'ctd_raw'"
)$column_name
cast_cols <- setdiff(
raw_cols,
c(meas_cols, qual_cols, "depth_m", "_source_file")
)
# extract one row per cast, keyed (cruise_key, cast_key, cast_dir,
# datetime_start_utc). within that key the only cast-level column that varies is
# lat/lon (sub-meter GPS jitter between same-second scans), so order by it for a
# deterministic pick. measurement-like columns (e.g. ox_aveu_m_sta_corr) must be
# registered in measurement_type.csv so they pivot to ctd_measurement and never
# reach cast_cols — otherwise SELECT DISTINCT would emit multiple rows per cast.
dbExecute(
con,
glue(
"
CREATE OR REPLACE TABLE ctd_cast AS
SELECT {paste(cast_cols, collapse = ', ')}
FROM ctd_raw
QUALIFY ROW_NUMBER() OVER (
PARTITION BY cruise_key, cast_key, cast_dir, datetime_start_utc
ORDER BY latitude, longitude) = 1
ORDER BY datetime_start_utc, cruise_key"
)
)
n_cast <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_cast")$n
message(glue("ctd_cast: {format(n_cast, big.mark = ',')} rows"))
# assign deterministic UUID from composite natural key (md5-based, DuckDB-native)
assign_deterministic_uuids_md5(
con = con,
table_name = "ctd_cast",
id_col = "ctd_cast_uuid",
key_cols = c("cruise_key", "cast_key", "cast_dir", "datetime_start_utc")
)
# guard: ctd_cast_uuid must be a valid unique PK — fail loudly if a
# measurement-like column ever leaks into cast_cols again (see #53)
stopifnot(
"ctd_cast_uuid is not unique" =
dbGetQuery(
con,
"SELECT COUNT(*) - COUNT(DISTINCT ctd_cast_uuid) AS n FROM ctd_cast"
)$n == 0)
```
### ctd_measurement — long-format sensor readings
```{r}
#| label: ctd_measurement
# add ctd_cast_uuid to ctd_raw for FK linkage
dbExecute(
con,
"
ALTER TABLE ctd_raw ADD COLUMN IF NOT EXISTS ctd_cast_uuid VARCHAR"
)
dbExecute(
con,
"
UPDATE ctd_raw AS r
SET ctd_cast_uuid = c.ctd_cast_uuid
FROM ctd_cast AS c
WHERE r.cruise_key = c.cruise_key
AND r.cast_key = c.cast_key
AND r.cast_dir = c.cast_dir
AND r.datetime_start_utc = c.datetime_start_utc"
)
# pivot wide-to-long one measurement type at a time to avoid OOM
dbExecute(con, "DROP TABLE IF EXISTS ctd_measurement")
for (i in seq_len(nrow(d_meas_ctd))) {
row <- d_meas_ctd[i, ]
src_col <- row$`_source_column`
meas_type <- row$measurement_type
qual_col <- row$`_qual_column`
qual_expr <- if (!is.na(qual_col) && qual_col != "") {
glue("CAST({qual_col} AS VARCHAR)")
} else {
"NULL"
}
sql_select <- glue(
"
SELECT ctd_cast_uuid, depth_m,
'{meas_type}' AS measurement_type,
CAST({src_col} AS DOUBLE) AS measurement_value,
{qual_expr} AS measurement_qual
FROM ctd_raw
WHERE {src_col} IS NOT NULL
AND NOT isnan(CAST({src_col} AS DOUBLE))
AND isfinite(CAST({src_col} AS DOUBLE))
"
)
if (i == 1) {
dbExecute(con, glue("CREATE OR REPLACE TABLE ctd_measurement AS {sql_select}"))
} else {
dbExecute(con, glue("INSERT INTO ctd_measurement {sql_select}"))
}
message(glue(" {i}/{nrow(d_meas_ctd)}: {meas_type}"))
}
n_meas <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_measurement")$n
message(glue("ctd_measurement: {format(n_meas, big.mark = ',')} rows"))
# assign deterministic UUID (md5-based, DuckDB-native — single SQL, no R data transfer)
assign_deterministic_uuids_md5(
con = con,
table_name = "ctd_measurement",
id_col = "ctd_measurement_uuid",
key_cols = c("ctd_cast_uuid", "depth_m", "measurement_type")
)
# add cruise_key for partitioned parquet output
dbExecute(
con,
"ALTER TABLE ctd_measurement ADD COLUMN IF NOT EXISTS cruise_key VARCHAR"
)
dbExecute(
con,
"UPDATE ctd_measurement AS m
SET cruise_key = c.cruise_key
FROM ctd_cast AS c
WHERE m.ctd_cast_uuid = c.ctd_cast_uuid"
)
# remove orphaned measurements with no parent cast
n_orphan <- dbGetQuery(
con,
"SELECT COUNT(*) FROM ctd_measurement WHERE ctd_cast_uuid IS NULL"
)[[1]]
if (n_orphan > 0) {
dbExecute(con, "DELETE FROM ctd_measurement WHERE ctd_cast_uuid IS NULL")
cat(glue("{format(n_orphan, big.mark = ',')} orphaned ctd_measurement ",
"rows removed (NULL ctd_cast_uuid)"), "\n")
}
```
### ctd_summary — summary stats across cast directions
```{r}
#| label: ctd_summary
dbExecute(
con,
"
CREATE OR REPLACE TABLE ctd_summary AS
SELECT
c.cruise_key,
c.site_key,
m.depth_m,
m.measurement_type,
AVG(m.measurement_value) AS avg,
CASE
WHEN COUNT(*) = 1 THEN 0
ELSE COALESCE(STDDEV_SAMP(m.measurement_value), 0)
END AS stddev,
COUNT(*) AS n_obs
FROM ctd_measurement m
INNER JOIN ctd_cast c ON m.ctd_cast_uuid = c.ctd_cast_uuid
WHERE NOT isnan(m.measurement_value)
AND isfinite(m.measurement_value)
GROUP BY c.cruise_key, c.site_key, m.depth_m, m.measurement_type"
)
n_summ <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_summary")$n
message(glue("ctd_summary: {format(n_summ, big.mark = ',')} rows"))
assign_deterministic_uuids_md5(
con = con,
table_name = "ctd_summary",
id_col = "ctd_summary_uuid",
key_cols = c("cruise_key", "site_key", "depth_m", "measurement_type")
)
```
### measurement_type — reference table
```{r}
#| label: measurement_type
dbWriteTable(con, "measurement_type", d_meas_type, overwrite = TRUE)
message(glue("measurement_type: {nrow(d_meas_type)} rows"))
# validate: all measurement_types used by this dataset are registered
ctd_types_used <- dbGetQuery(
con,
"SELECT DISTINCT measurement_type FROM ctd_measurement"
)$measurement_type
registered <- d_meas_type |>
filter(str_detect(`_source_datasets`, "calcofi_ctd-cast")) |>
pull(measurement_type)
unregistered <- setdiff(ctd_types_used, registered)
stopifnot(
"all measurement_types used by calcofi_ctd-cast must be registered in _source_datasets" = length(
unregistered
) ==
0
)
```
### Drop intermediate table
```{r}
#| label: drop_ctd_raw
dbExecute(con, "DROP TABLE IF EXISTS ctd_raw")
```
## Measurement Frequency
`ctd_measurement` is by far the largest table in this dataset — in the prior release the `calcofi_ctd-cast` parquet totaled 22.16 GB, with `ctd_measurement` alone at 15.8 GB (233 M rows). Three stacked multipliers drive that size. The queries below quantify each, motivating the adaptively-thinned `ctd_thin` table built in the next section.
```{r}
#| label: freq_table_sizes
freq_tbl_sizes <- dbGetQuery(con, "
SELECT 'ctd_cast' AS table_name, COUNT(*) AS n_rows FROM ctd_cast
UNION ALL
SELECT 'ctd_measurement' AS table_name, COUNT(*) AS n_rows FROM ctd_measurement
UNION ALL
SELECT 'ctd_summary' AS table_name, COUNT(*) AS n_rows FROM ctd_summary")
n_meas_rows <- freq_tbl_sizes$n_rows[freq_tbl_sizes$table_name == "ctd_measurement"]
cat(glue("ctd_measurement: {format(n_meas_rows, big.mark = ',')} rows"), "\n")
freq_tbl_sizes |>
dt(caption = "Normalized CTD table row counts (this run)",
fname = "ctd_freq_table_sizes")
```
### Multiplier 1 — sub-meter depth resolution
CTD profiles record a sample roughly every metre from surface to seafloor (~3,600 m max). Thinning to a 10 m grid is therefore an order-of-magnitude reduction on the depth axis.
```{r}
#| label: freq_depth_resolution
# depth interval between consecutive samples within a cast, using `pressure`
# as a representative measurement_type (all types share a cast's depth grid)
freq_depth_int <- dbGetQuery(con, "
WITH gaps AS (
SELECT depth_m - LAG(depth_m) OVER (
PARTITION BY ctd_cast_uuid ORDER BY depth_m) AS d_gap
FROM ctd_measurement
WHERE measurement_type = 'pressure')
SELECT
ROUND(MIN(d_gap), 2) AS min_m,
ROUND(QUANTILE_CONT(d_gap, 0.25), 2) AS q25_m,
ROUND(MEDIAN(d_gap), 2) AS median_m,
ROUND(QUANTILE_CONT(d_gap, 0.75), 2) AS q75_m,
ROUND(MAX(d_gap), 2) AS max_m
FROM gaps
WHERE d_gap IS NOT NULL")
cat(glue(
"median within-cast depth interval: {freq_depth_int$median_m} m ",
"(~{round(10 / freq_depth_int$median_m)}x reduction at a 10 m grid)"), "\n")
freq_depth_int |>
dt(caption = "Within-cast depth interval (m), representative type `pressure`",
fname = "ctd_freq_depth_resolution")
```
### Multiplier 2 — up- and down-casts both stored
Nearly every physical cast is recorded as a separate down-cast and up-cast. Keeping a single direction roughly halves the rows.
```{r}
#| label: freq_cast_direction
# physical cast = (cruise_key, site_key, cast_base); direction resolved from
# cast_dir, falling back to the cast_key suffix (trailing d/u)
freq_cast_dir <- dbGetQuery(con, "
WITH phys AS (
SELECT DISTINCT
cruise_key, site_key,
regexp_replace(cast_key, '[duDU]$', '') AS cast_base,
COALESCE(
cast_dir,
CASE
WHEN RIGHT(cast_key, 1) IN ('d', 'D') THEN 'D'
WHEN RIGHT(cast_key, 1) IN ('u', 'U') THEN 'U'
END) AS dir
FROM ctd_cast)
SELECT
COUNT(DISTINCT cruise_key || '|' || site_key || '|' || cast_base)
AS n_physical_casts,
COUNT(*) FILTER (WHERE dir = 'D') AS n_with_downcast,
COUNT(*) FILTER (WHERE dir = 'U') AS n_with_upcast,
COUNT(*) FILTER (WHERE dir IS NULL) AS n_unknown_dir
FROM phys")
cat(glue(
"{format(freq_cast_dir$n_physical_casts, big.mark = ',')} physical casts; ",
"{format(freq_cast_dir$n_with_downcast, big.mark = ',')} have a downcast, ",
"{format(freq_cast_dir$n_with_upcast, big.mark = ',')} an upcast"), "\n")
freq_cast_dir |>
dt(caption = "Cast direction coverage per physical cast",
fname = "ctd_freq_cast_direction")
```
### Multiplier 3 — redundant measurement-type variants
Many of the measurement types below are variants of the same property (multiple oxygen units and sensor/correction combinations, dual temperature and salinity sensors, derived estimates). `ctd_thin` keeps one canonical type per property — see the `is_canonical` flag in `metadata/measurement_type.csv`.
```{r}
#| label: freq_measurement_types
freq_meas_types <- dbGetQuery(con, "
SELECT
measurement_type,
COUNT(*) AS n_rows,
COUNT(DISTINCT ctd_cast_uuid) AS n_casts
FROM ctd_measurement
GROUP BY measurement_type
ORDER BY n_rows DESC")
cat(glue(
"{nrow(freq_meas_types)} distinct measurement_type values in ctd_measurement"),
"\n")
freq_meas_types |>
dt(caption = "Rows per measurement_type",
fname = "ctd_freq_measurement_types")
```
## CTD Thin
`ctd_thin` is an adaptively-thinned `ctd_measurement`: one cast direction per physical cast, canonical measurement types only, and a ~10 m depth grid with thermocline / halocline inflections preserved via Ramer–Douglas–Peucker line simplification. It is the headline CTD table; full `ctd_measurement` is retained as a supplemental output. See the Measurement Frequency section above for the size rationale.
### Verify cast pairing
```{r}
#| label: ctd_thin_verify_pairing
# physical cast = (cruise_key, site_key, cast_base); direction comes from the
# cast_key suffix (trailing d/u), which is part of the deterministic
# ctd_cast_uuid key and fully consistent per cast. confirm casts are paired
# before thinning by direction.
ctd_pairing <- dbGetQuery(con, "
WITH phys AS (
SELECT DISTINCT
cruise_key, site_key,
regexp_replace(cast_key, '[duDU]$', '') AS cast_base,
CASE WHEN RIGHT(cast_key, 1) IN ('d', 'D') THEN 'D'
WHEN RIGHT(cast_key, 1) IN ('u', 'U') THEN 'U' END AS dir
FROM ctd_cast)
SELECT n_dirs, COUNT(*) AS n_physical_casts
FROM (
SELECT cruise_key, site_key, cast_base, COUNT(DISTINCT dir) AS n_dirs
FROM phys GROUP BY 1, 2, 3)
GROUP BY n_dirs ORDER BY n_dirs")
n_paired <- sum(ctd_pairing$n_physical_casts[ctd_pairing$n_dirs == 2])
n_single <- sum(ctd_pairing$n_physical_casts[ctd_pairing$n_dirs == 1])
cat(glue(
"{format(n_paired, big.mark = ',')} physical casts have both directions, ",
"{format(n_single, big.mark = ',')} have one"), "\n")
# sanity: most casts should be paired — a near-zero n_paired means the pairing
# key is wrong and the single-direction lever would silently keep everything
stopifnot(
"ctd_thin: cast pairing key looks wrong (no two-direction casts)" =
n_paired > n_single)
ctd_pairing |>
dt(caption = "Cast directions per physical cast", fname = "ctd_thin_pairing")
```
### Choose a single cast direction
```{r}
#| label: ctd_thin_chosen_dir
# canonical measurement types for ctd_thin (one per property; see is_canonical
# in metadata/measurement_type.csv)
canon_types <- d_meas_type |>
filter(str_detect(`_source_datasets`, "calcofi_ctd-cast"), is_canonical) |>
pull(measurement_type)
canon_in <- paste0("'", canon_types, "'", collapse = ", ")
cat(glue("{length(canon_types)} canonical measurement types: ",
"{paste(canon_types, collapse = ', ')}"), "\n")
# choose one direction per physical cast: prefer downcast, fall back to upcast.
# _chosen_dir maps every chosen-direction ctd_cast_uuid to its physical cast
# (phys_cast_id) and direction.
dbExecute(con, "
CREATE OR REPLACE TEMP TABLE _chosen_dir AS
WITH resolved AS (
SELECT DISTINCT
ctd_cast_uuid, cruise_key, site_key, cast_key,
regexp_replace(cast_key, '[duDU]$', '') AS cast_base,
CASE WHEN RIGHT(cast_key, 1) IN ('d', 'D') THEN 'D'
WHEN RIGHT(cast_key, 1) IN ('u', 'U') THEN 'U' END AS dir
FROM ctd_cast),
pick AS (
SELECT cruise_key, site_key, cast_base, cast_key, dir
FROM (SELECT DISTINCT cruise_key, site_key, cast_base, cast_key, dir
FROM resolved)
QUALIFY ROW_NUMBER() OVER (
PARTITION BY cruise_key, site_key, cast_base
ORDER BY CASE dir WHEN 'D' THEN 1 WHEN 'U' THEN 2 ELSE 3 END,
cast_key) = 1)
SELECT
r.ctd_cast_uuid,
r.cruise_key,
r.cruise_key || '|' || r.site_key || '|' || r.cast_base AS phys_cast_id,
p.dir AS cast_dir
FROM resolved r
JOIN pick p USING (cruise_key, site_key, cast_base, cast_key)")
n_chosen <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM _chosen_dir")$n
cat(glue("_chosen_dir: {format(n_chosen, big.mark = ',')} cast records ",
"(single direction per physical cast)"), "\n")
```
### 10 m depth grid
```{r}
#| label: ctd_thin_grid
# depth backbone: every distinct depth a canonical measurement is recorded at,
# per chosen-direction physical cast
dbExecute(con, glue("
CREATE OR REPLACE TEMP TABLE _profile_depths AS
SELECT DISTINCT cd.phys_cast_id, m.depth_m
FROM ctd_measurement m
JOIN _chosen_dir cd ON m.ctd_cast_uuid = cd.ctd_cast_uuid
WHERE m.measurement_type IN ({canon_in})"))
# 10 m grid: the sample nearest each 10 m node per profile, plus the shallowest
# and deepest sample (RDP needs fixed profile endpoints)
dbExecute(con, "
CREATE OR REPLACE TEMP TABLE _grid_depths AS
WITH ranked AS (
SELECT phys_cast_id, depth_m,
ROW_NUMBER() OVER (
PARTITION BY phys_cast_id, ROUND(depth_m / 10.0) * 10.0
ORDER BY ABS(depth_m - ROUND(depth_m / 10.0) * 10.0), depth_m) AS rn
FROM _profile_depths),
endpoints AS (
SELECT phys_cast_id, MIN(depth_m) AS depth_m FROM _profile_depths GROUP BY 1
UNION
SELECT phys_cast_id, MAX(depth_m) AS depth_m FROM _profile_depths GROUP BY 1)
SELECT phys_cast_id, depth_m FROM ranked WHERE rn = 1
UNION
SELECT phys_cast_id, depth_m FROM endpoints")
n_prof <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM _profile_depths")$n
n_grid <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM _grid_depths")$n
cat(glue("_grid_depths: {format(n_grid, big.mark = ',')} depths on the 10 m grid ",
"(from {format(n_prof, big.mark = ',')} profile depths)"), "\n")
```
### Inflection points (Ramer–Douglas–Peucker)
```{r}
#| label: ctd_thin_rdp
# Ramer-Douglas-Peucker line simplification: keep depths where a profile deviates
# from the local straight line by more than `eps` (captures thermocline /
# halocline inflections). pure DP — the ~10 m backbone is provided separately by
# _grid_depths, so RDP only adds genuine inflections on top of it.
rdp_keep <- function(x, y, eps) {
n <- length(x)
keep <- rep(FALSE, n)
if (n == 0L) return(keep)
keep[c(1L, n)] <- TRUE
if (n <= 2L) return(keep)
stack <- list(c(1L, n))
while (length(stack) > 0L) {
seg <- stack[[length(stack)]]
stack[[length(stack)]] <- NULL
i <- seg[1L]; j <- seg[2L]
if (j - i < 2L) next
idx <- (i + 1L):(j - 1L)
dx <- x[j] - x[i]
dy <- y[j] - y[i]
den <- sqrt(dx * dx + dy * dy)
d <- if (den == 0) {
abs(y[idx] - y[i])
} else {
abs(dy * x[idx] - dx * y[idx] + x[j] * y[i] - y[j] * x[i]) / den
}
if (max(d) > eps) {
k <- idx[which.max(d)]
keep[k] <- TRUE
stack[[length(stack) + 1L]] <- c(i, k)
stack[[length(stack) + 1L]] <- c(k, j)
}
}
keep
}
# per-variable tolerance in measurement units — the primary tuning knob, set so
# the median retained-sample gap lands near the 10 m grid spacing (a looser eps
# keeps fewer inflections; revisit with the spot-check in the verification section)
rdp_eps <- c(temperature_ave = 0.2, salinity_ave_corr = 0.04)
# run RDP per cruise to keep memory flat: pull the two key variables for
# chosen-direction casts, simplify each profile, collect retained depths
cruise_keys <- dbGetQuery(con, "SELECT DISTINCT cruise_key FROM _chosen_dir")$cruise_key
rdp_retained <- purrr::map(cruise_keys, function(ck) {
d_prof <- dbGetQuery(con, glue("
SELECT cd.phys_cast_id, m.measurement_type, m.depth_m,
AVG(m.measurement_value) AS measurement_value
FROM ctd_measurement m
JOIN _chosen_dir cd
ON m.ctd_cast_uuid = cd.ctd_cast_uuid AND cd.cruise_key = '{ck}'
WHERE m.cruise_key = '{ck}'
AND m.measurement_type IN ('temperature_ave', 'salinity_ave_corr')
AND m.measurement_value IS NOT NULL
GROUP BY cd.phys_cast_id, m.measurement_type, m.depth_m"))
if (nrow(d_prof) == 0) return(NULL)
d_prof |>
arrange(phys_cast_id, measurement_type, depth_m) |>
group_by(phys_cast_id, measurement_type) |>
filter(rdp_keep(depth_m, measurement_value,
eps = rdp_eps[[measurement_type[1]]])) |>
ungroup() |>
distinct(phys_cast_id, depth_m)
}) |>
purrr::list_rbind() |>
distinct(phys_cast_id, depth_m)
dbWriteTable(con, "_rdp_retained", rdp_retained,
temporary = TRUE, overwrite = TRUE)
cat(glue("_rdp_retained: {format(nrow(rdp_retained), big.mark = ',')} ",
"(profile, depth) pairs flagged as inflections"), "\n")
```
### Assemble ctd_thin
```{r}
#| label: ctd_thin_assemble
# union the 10 m grid and the RDP inflection points (grid wins ties)
dbExecute(con, "
CREATE OR REPLACE TEMP TABLE _retained_depths AS
SELECT phys_cast_id, depth_m, 'grid' AS retained_reason FROM _grid_depths
UNION
SELECT r.phys_cast_id, r.depth_m, 'inflection' AS retained_reason
FROM _rdp_retained r
WHERE NOT EXISTS (
SELECT 1 FROM _grid_depths g
WHERE g.phys_cast_id = r.phys_cast_id AND g.depth_m = r.depth_m)")
# ctd_thin: ctd_measurement rows that are a canonical type, on the chosen
# direction, at a retained depth — a pure row subset (values never interpolated).
# the QUALIFY de-dups defensively on (ctd_cast_uuid, depth_m, measurement_type):
# the dedup_ctd_raw chunk above already makes ctd_measurement unique, so this is
# a no-op safeguard that keeps ctd_thin's PK guaranteed-unique on its own.
dbExecute(con, glue("
CREATE OR REPLACE TABLE ctd_thin AS
WITH candidates AS (
SELECT
m.ctd_cast_uuid,
m.depth_m,
m.measurement_type,
m.measurement_value,
m.measurement_qual,
cd.cast_dir,
rd.retained_reason,
m.cruise_key
FROM ctd_measurement m
JOIN _chosen_dir cd ON m.ctd_cast_uuid = cd.ctd_cast_uuid
JOIN _retained_depths rd ON rd.phys_cast_id = cd.phys_cast_id
AND rd.depth_m = m.depth_m
WHERE m.measurement_type IN ({canon_in}))
SELECT *
FROM candidates
QUALIFY ROW_NUMBER() OVER (
PARTITION BY ctd_cast_uuid, depth_m, measurement_type
ORDER BY measurement_qual NULLS LAST, measurement_value) = 1
ORDER BY cruise_key, ctd_cast_uuid, measurement_type, depth_m"))
n_thin <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_thin")$n
n_meas <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_measurement")$n
cat(glue(
"ctd_thin: {format(n_thin, big.mark = ',')} rows ",
"({round(100 * n_thin / n_meas, 1)}% of ctd_measurement's ",
"{format(n_meas, big.mark = ',')})"), "\n")
# deterministic PK from the natural key, mirroring ctd_measurement
assign_deterministic_uuids_md5(
con = con,
table_name = "ctd_thin",
id_col = "ctd_thin_uuid",
key_cols = c("ctd_cast_uuid", "depth_m", "measurement_type"))
# drop scratch tables; _chosen_dir is kept for the verification chunk that
# follows and dropped there (downstream metadata helpers enumerate all DB tables)
dbExecute(con, "DROP TABLE IF EXISTS _profile_depths")
dbExecute(con, "DROP TABLE IF EXISTS _grid_depths")
dbExecute(con, "DROP TABLE IF EXISTS _rdp_retained")
dbExecute(con, "DROP TABLE IF EXISTS _retained_depths")
```
### Verify ctd_thin
```{r}
#| label: ctd_thin_verify
# 1. row count + thinning ratio
n_thin <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_thin")$n
n_meas <- dbGetQuery(con, "SELECT COUNT(*) AS n FROM ctd_measurement")$n
cat(glue("ctd_thin: {format(n_thin, big.mark = ',')} rows = ",
"{round(100 * n_thin / n_meas, 1)}% of ctd_measurement"), "\n")
stopifnot(
"ctd_thin is empty" = n_thin > 0,
"ctd_thin not smaller than ctd_measurement" = n_thin < n_meas)
# 2. measurement_type is a subset of the canonical list
thin_types <- dbGetQuery(con,
"SELECT DISTINCT measurement_type FROM ctd_thin")$measurement_type
stopifnot("ctd_thin has non-canonical measurement_type" =
length(setdiff(thin_types, canon_types)) == 0)
# 3. ctd_thin_uuid is unique
stopifnot("ctd_thin_uuid not unique" = dbGetQuery(con,
"SELECT COUNT(*) - COUNT(DISTINCT ctd_thin_uuid) AS n FROM ctd_thin")$n == 0)
# 4. faithful subset of ctd_measurement — every ctd_thin row corresponds to a
# real ctd_measurement row with the same value (thinning selects rows, never
# interpolates). a NOT EXISTS check, since ctd_measurement has duplicate keys.
stopifnot("ctd_thin rows not a faithful subset of ctd_measurement" =
dbGetQuery(con, "
SELECT COUNT(*) AS n
FROM ctd_thin t
WHERE NOT EXISTS (
SELECT 1 FROM ctd_measurement m
WHERE m.ctd_cast_uuid = t.ctd_cast_uuid
AND m.depth_m = t.depth_m
AND m.measurement_type = t.measurement_type
AND m.measurement_value IS NOT DISTINCT FROM t.measurement_value)")$n == 0)
# 5. retained_reason populated with the two expected categories
reason_breakdown <- dbGetQuery(con,
"SELECT retained_reason, COUNT(*) AS n FROM ctd_thin GROUP BY 1 ORDER BY 1")
stopifnot(
"ctd_thin retained_reason has unexpected values" =
all(reason_breakdown$retained_reason %in% c("grid", "inflection")),
"ctd_thin retained_reason missing a category" =
all(c("grid", "inflection") %in% reason_breakdown$retained_reason))
# 6. one cast direction per physical cast; no physical cast dropped entirely
coverage <- dbGetQuery(con, glue("
WITH meas_casts AS (
SELECT DISTINCT cd.phys_cast_id
FROM ctd_measurement m
JOIN _chosen_dir cd ON m.ctd_cast_uuid = cd.ctd_cast_uuid
WHERE m.measurement_type IN ({canon_in})),
thin AS (
SELECT cd.phys_cast_id, COUNT(DISTINCT t.cast_dir) AS n_dir
FROM ctd_thin t
JOIN _chosen_dir cd ON t.ctd_cast_uuid = cd.ctd_cast_uuid
GROUP BY cd.phys_cast_id)
SELECT
(SELECT COUNT(*) FROM thin) AS n_thin_casts,
(SELECT COUNT(*) FROM thin WHERE n_dir > 1) AS n_multi_dir,
(SELECT COUNT(*) FROM (
SELECT phys_cast_id FROM meas_casts
EXCEPT
SELECT phys_cast_id FROM thin)) AS n_dropped"))
stopifnot(
"ctd_thin: physical cast with >1 direction" = coverage$n_multi_dir == 0,
"ctd_thin: physical cast dropped entirely" = coverage$n_dropped == 0)
cat(glue("{format(coverage$n_thin_casts, big.mark = ',')} physical casts ",
"retained (single direction each)"), "\n")
# 7. depth-gap distribution between retained samples
gap_stats <- dbGetQuery(con, "
WITH g AS (
SELECT t.depth_m - LAG(t.depth_m) OVER (
PARTITION BY cd.phys_cast_id, t.measurement_type
ORDER BY t.depth_m) AS gap_m
FROM ctd_thin t
JOIN _chosen_dir cd ON t.ctd_cast_uuid = cd.ctd_cast_uuid)
SELECT
ROUND(MEDIAN(gap_m), 2) AS median_gap_m,
ROUND(QUANTILE_CONT(gap_m, 0.95), 2) AS p95_gap_m,
ROUND(MAX(gap_m), 2) AS max_gap_m
FROM g WHERE gap_m IS NOT NULL")
cat(glue("depth gaps between retained samples: median {gap_stats$median_gap_m} m, ",
"p95 {gap_stats$p95_gap_m} m, max {gap_stats$max_gap_m} m"), "\n")
# 8. every ctd_thin type is registered as canonical in measurement_type
stopifnot("ctd_thin types not registered as canonical in measurement_type" =
length(dbGetQuery(con, "
SELECT DISTINCT t.measurement_type
FROM ctd_thin t
LEFT JOIN measurement_type mt ON t.measurement_type = mt.measurement_type
WHERE mt.measurement_type IS NULL OR NOT mt.is_canonical")$measurement_type) == 0)
# done with _chosen_dir — drop before downstream metadata helpers enumerate tables
dbExecute(con, "DROP TABLE IF EXISTS _chosen_dir")
reason_breakdown |>
dt(caption = "ctd_thin rows by retained_reason", fname = "ctd_thin_reason")
```
### Spot-check thinned profiles
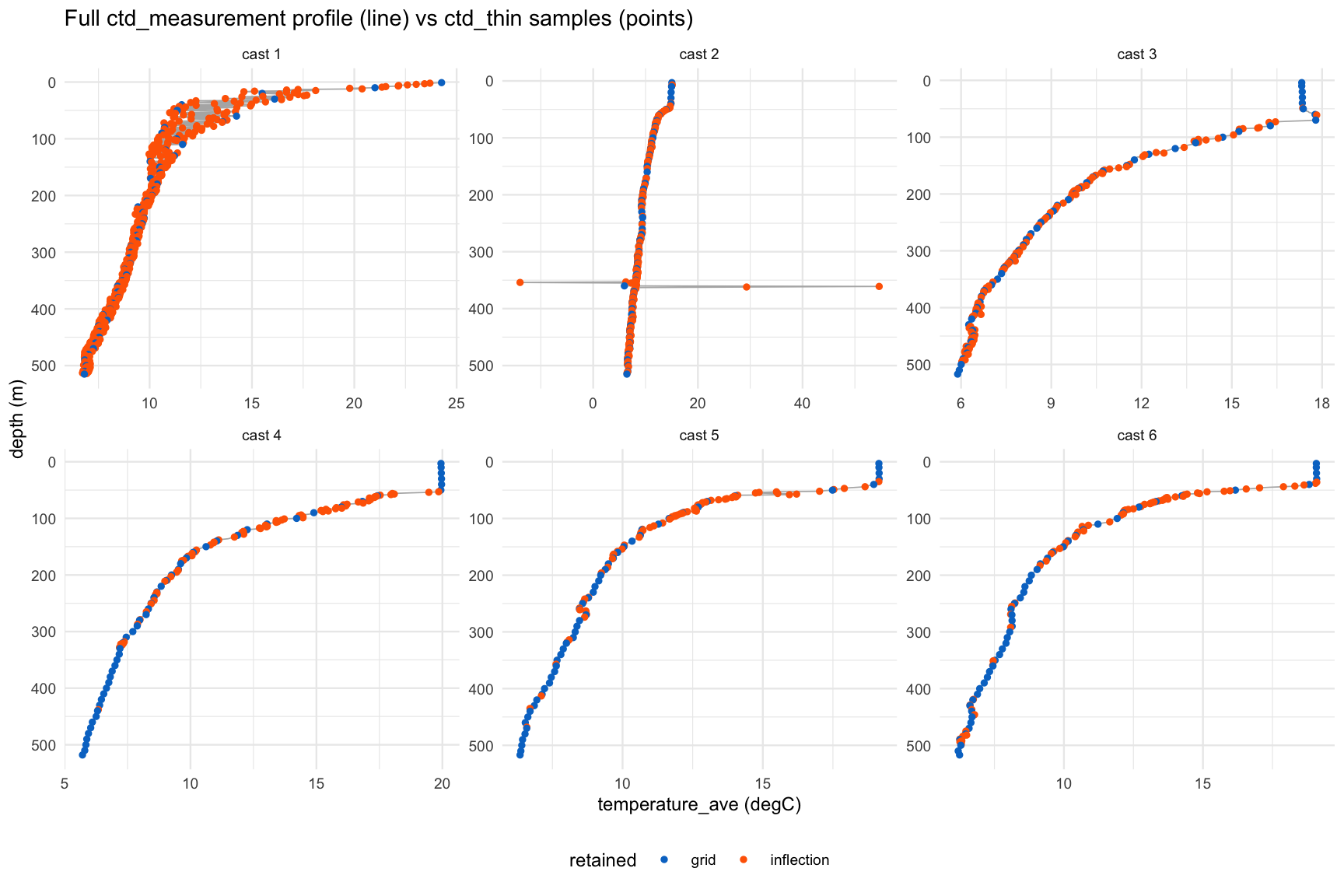
Overlay the full `ctd_measurement` profile (line) against the `ctd_thin` samples (points) for the six temperature profiles with the most retained inflection points — confirming thermocline curvature is tracked while flat segments stay sparse.
```{r}
#| label: ctd_thin_spotcheck
#| fig-width: 9
#| fig-height: 6
# a ctd_cast_uuid is a single depth sample, not a profile — group by the
# physical cast (cruise_key + cast_key). pick six temperature profiles with the
# most retained inflection points (the hardest cases to thin faithfully).
cast_map <- "(SELECT DISTINCT ctd_cast_uuid, cast_key FROM ctd_cast)"
spot <- dbGetQuery(con, glue("
WITH thin AS (
SELECT t.cruise_key, cm.cast_key, t.retained_reason
FROM ctd_thin t
JOIN {cast_map} cm ON t.ctd_cast_uuid = cm.ctd_cast_uuid
WHERE t.measurement_type = 'temperature_ave')
SELECT cruise_key, cast_key
FROM thin
GROUP BY cruise_key, cast_key
HAVING COUNT(*) >= 20
ORDER BY COUNT(*) FILTER (WHERE retained_reason = 'inflection') DESC,
cruise_key, cast_key
LIMIT 6"))
spot$cast <- paste("cast", seq_len(nrow(spot)))
spot_in <- if (nrow(spot) > 0) {
paste(sprintf("('%s', '%s')", spot$cruise_key, spot$cast_key), collapse = ", ")
} else "('', '')"
# full ctd_measurement profile (de-duplicated) and the thinned samples
d_full <- dbGetQuery(con, glue("
SELECT t.cruise_key, cm.cast_key, t.depth_m,
AVG(t.measurement_value) AS measurement_value
FROM ctd_measurement t
JOIN {cast_map} cm ON t.ctd_cast_uuid = cm.ctd_cast_uuid
WHERE t.measurement_type = 'temperature_ave'
AND (t.cruise_key, cm.cast_key) IN ({spot_in})
GROUP BY t.cruise_key, cm.cast_key, t.depth_m
ORDER BY t.cruise_key, cm.cast_key, t.depth_m"))
d_thin <- dbGetQuery(con, glue("
SELECT t.cruise_key, cm.cast_key, t.depth_m, t.measurement_value,
t.retained_reason
FROM ctd_thin t
JOIN {cast_map} cm ON t.ctd_cast_uuid = cm.ctd_cast_uuid
WHERE t.measurement_type = 'temperature_ave'
AND (t.cruise_key, cm.cast_key) IN ({spot_in})
ORDER BY t.cruise_key, cm.cast_key, t.depth_m"))
# short facet labels keyed on cruise_key + cast_key
prof_key <- function(d) paste(d$cruise_key, d$cast_key)
cast_lab <- setNames(spot$cast, prof_key(spot))
d_full$cast <- cast_lab[prof_key(d_full)]
d_thin$cast <- cast_lab[prof_key(d_thin)]
ggplot2::ggplot() +
ggplot2::geom_path(
data = d_full, ggplot2::aes(measurement_value, depth_m),
color = "grey70", linewidth = 0.3) +
ggplot2::geom_point(
data = d_thin,
ggplot2::aes(measurement_value, depth_m, color = retained_reason),
size = 1.1) +
ggplot2::scale_y_reverse() +
ggplot2::scale_color_manual(
values = c(grid = "#0077cc", inflection = "#ff6600")) +
ggplot2::facet_wrap(~ cast, scales = "free", nrow = 2) +
ggplot2::labs(
x = "temperature_ave (degC)", y = "depth (m)", color = "retained",
title = "Full ctd_measurement profile (line) vs ctd_thin samples (points)") +
ggplot2::theme_minimal(base_size = 9) +
ggplot2::theme(legend.position = "bottom")
```
## Schema Diagram
```{r}
#| label: schema
# define PK/FK relationships for visualization and relationships.json
ctd_rels <- list(
primary_keys = list(
ctd_cast = "ctd_cast_uuid",
ctd_measurement = "ctd_measurement_uuid",
ctd_thin = "ctd_thin_uuid",
ctd_summary = "ctd_summary_uuid",
measurement_type = "measurement_type"),
foreign_keys = list(
list(table = "ctd_measurement", column = "ctd_cast_uuid", ref_table = "ctd_cast", ref_column = "ctd_cast_uuid"),
list(table = "ctd_thin", column = "ctd_cast_uuid", ref_table = "ctd_cast", ref_column = "ctd_cast_uuid"),
list(table = "ctd_measurement", column = "measurement_type", ref_table = "measurement_type", ref_column = "measurement_type"),
list(table = "ctd_thin", column = "measurement_type", ref_table = "measurement_type", ref_column = "measurement_type"),
list(table = "ctd_summary", column = "measurement_type", ref_table = "measurement_type", ref_column = "measurement_type")))
cc_erd(con, rels = ctd_rels)
```
## Add Spatial
```{r}
#| label: add_spatial
add_point_geom(con, "ctd_cast", lon_col = "longitude", lat_col = "latitude")
# grid already loaded in Cross-Dataset Bridge section
assign_grid_key(con, "ctd_cast")
```
## Derived View
```{r}
#| label: derived_view
dbExecute(
con,
"
CREATE OR REPLACE VIEW ctd_cast_derived AS
SELECT *,
datetime_start_utc AT TIME ZONE 'UTC' AT TIME ZONE 'US/Pacific' AS datetime_pst,
EXTRACT(YEAR FROM datetime_start_utc) AS year,
EXTRACT(MONTH FROM datetime_start_utc) AS month,
EXTRACT(DOY FROM datetime_start_utc) AS julian_day
FROM ctd_cast"
)
```
## Load Dataset Metadata
```{r}
#| label: load-dataset-metadata
# dataset registry built from authoritative ingest_*.qmd YAML (was dataset.csv)
d_dataset <- ingest_yaml_to_dataset_df(read_ingest_yaml(here()))
dbWriteTable(con, "dataset", d_dataset, overwrite = TRUE)
message(glue("dataset: {nrow(d_dataset)} datasets registered"))
```
## Validate and Enforce Types
```{r}
#| label: validate
validate_for_release(con)
enforce_column_types(con, d_flds_rd = d_flds_rd)
```
## Preview Tables
```{r}
#| label: preview
#| results: asis
preview_tables(
con,
tables = c("ctd_cast", "ctd_measurement", "ctd_thin", "ctd_summary",
"measurement_type", "ctd_wide")
)
```
## Write Parquet
```{r}
#| label: write_parquet
# collect mismatches for manifest
mismatches <- list(
ships = collect_ship_mismatches(con, "ctd_cast"),
measurement_types = collect_measurement_type_mismatches(
con, here("metadata/measurement_type.csv")),
cruise_keys = collect_cruise_key_mismatches(con, "ctd_cast"))
parquet_stats <- write_parquet_outputs(
con = con,
output_dir = dir_parquet,
tables = c("ctd_cast", "ctd_measurement", "ctd_thin", "ctd_summary",
"measurement_type", "ctd_wide"),
partition_by = list(
ctd_measurement = "cruise_key",
ctd_thin = "cruise_key",
ctd_summary = "cruise_key"),
sort_by = list(
ctd_measurement = c("measurement_type", "depth_m"),
ctd_thin = c("measurement_type", "depth_m"),
ctd_summary = c("measurement_type", "depth_m"),
ctd_cast = "hilbert:longitude,latitude"),
strip_provenance = FALSE,
mismatches = mismatches,
supplemental = c("ctd_wide", "ctd_measurement")
)
parquet_stats |>
dt(fname = "ctd_parquet_stats")
```
## Write Metadata JSON
```{r}
#| label: write_metadata
metadata_path <- build_metadata_json(
con = con,
d_tbls_rd = d_tbls_rd,
d_flds_rd = d_flds_rd,
metadata_derived_csv = glue("{dir_meta}/metadata_derived.csv"),
output_dir = dir_parquet,
tables = parquet_stats$table,
provider = provider,
dataset = dataset,
workflow_url = cc$workflow_url,
tables_owned = tables_owned
)
# write relationships.json sidecar with PKs/FKs
build_relationships_json(
rels = ctd_rels,
output_dir = dir_parquet,
provider = provider,
dataset = dataset
)
```
```{r}
#| label: show_metadata_json
listviewer::jsonedit(
jsonlite::fromJSON(metadata_path, simplifyVector = FALSE),
mode = "view")
```
```{r}
#| label: show_relationships_json
listviewer::jsonedit(
jsonlite::fromJSON(
file.path(dir_parquet, "relationships.json"),
simplifyVector = FALSE),
mode = "view")
```
## Export Modified Dependency Deltas
```{r}
#| label: export_new_deltas
# export _new delta sidecars for modified dependency tables (from calcofi.modifies)
# these are NOT in the manifest — picked up by build_release_table_registry()
for (tbl in modifies_tables) {
pk_col <- modifies_pks[[tbl]]$pk_col
keys_old <- modifies_pks[[tbl]]$keys
keys_new <- dbGetQuery(con, glue("SELECT {pk_col} FROM {tbl}"))[[1]]
additions <- setdiff(keys_new, keys_old)
if (length(additions) > 0) {
pq_path <- file.path(dir_parquet, paste0(tbl, "_new.parquet"))
vals <- paste(shQuote(additions, "sh"), collapse = ", ")
export_parquet(con,
glue("SELECT * FROM {tbl} WHERE {pk_col} IN ({vals})"), pq_path)
message(glue("{length(additions)} new {tbl} row(s) -> {tbl}_new.parquet"))
} else {
message(glue("No new {tbl} rows — {tbl}_new not exported"))
}
}
```
## Upload to GCS
```{r}
#| label: resume_for_upload
#| eval: true
# always re-enable eval for upload and cleanup
knitr::opts_chunk$set(eval = TRUE)
```
```{r}
#| label: upload_gcs
# skip sync if all parquet tables were unchanged (no re-write)
if (parquet_complete) {
message("Parquet unchanged — skipping GCS sync")
} else {
sync_to_gcs(
local_dir = dir_parquet,
gcs_prefix = glue("ingest/{dir_label}"),
bucket = "calcofi-db",
delete_stale = TRUE
)
}
```
## Cleanup
```{r}
#| label: cleanup
close_duckdb(con)
# remove checkpoint after successful completion (fresh next run)
if (file_exists(db_checkpoint)) {
file_delete(db_checkpoint)
message(glue("Removed checkpoint: {db_checkpoint}"))
}
```
## Appendix: Interactive Gantt Chart {.appendix}
```{r}
#| label: gantt_chart
# reconnect for gantt chart
con_pq <- get_duckdb_con()
load_duckdb_extension(con_pq, "spatial")
# read ctd_cast from parquet (exclude GEOMETRY columns for R driver compat)
dbExecute(con_pq, glue("
CREATE OR REPLACE VIEW _ctd_probe AS
SELECT * FROM read_parquet('{dir_parquet}/ctd_cast.parquet') LIMIT 0"))
pq_geom_cols <- dbGetQuery(con_pq,
"SELECT column_name FROM information_schema.columns
WHERE table_name = '_ctd_probe' AND data_type LIKE 'GEOMETRY%'")$column_name
pq_all_cols <- dbGetQuery(con_pq,
"SELECT column_name FROM information_schema.columns
WHERE table_name = '_ctd_probe'
ORDER BY ordinal_position")$column_name
pq_safe_cols <- setdiff(pq_all_cols, pq_geom_cols)
dbExecute(con_pq, "DROP VIEW IF EXISTS _ctd_probe")
dbExecute(con_pq, glue("
CREATE VIEW ctd_cast AS
SELECT {paste(pq_safe_cols, collapse = ', ')}
FROM read_parquet('{dir_parquet}/ctd_cast.parquet')"))
cruise_spans <- tbl(con_pq, "ctd_cast") |>
group_by(cruise_key, data_stage) |>
summarize(
beg_date = min(datetime_start_utc, na.rm = TRUE) |> as.Date(),
end_date = max(datetime_start_utc, na.rm = TRUE) |> as.Date(),
.groups = "drop"
) |>
collect() |>
filter(!is.na(beg_date), !is.na(end_date))
# split multi-year cruises into separate rows
cruise_spans <- cruise_spans |>
rowwise() |>
mutate(
years_spanned = list(year(beg_date):year(end_date))
) |>
unnest(years_spanned) |>
mutate(
year = years_spanned,
adj_beg_date = if_else(
years_spanned == year(beg_date),
beg_date,
as.Date(paste0(years_spanned, "-01-01"))
),
adj_end_date = if_else(
years_spanned == year(end_date),
end_date,
as.Date(paste0(years_spanned, "-12-31"))
),
begin_jday = yday(adj_beg_date),
end_jday = yday(adj_end_date),
stage_label = data_stage,
hover_text = glue(
"Cruise: {cruise_key}<br>",
"Stage: {data_stage}<br>",
"Begin: {format(beg_date, '%Y-%m-%d')}<br>",
"End: {format(end_date, '%Y-%m-%d')}<br>",
"Duration: {as.numeric(difftime(end_date, beg_date, units = 'days'))} days"
)
) |>
ungroup() |>
arrange(adj_beg_date)
colors <- c("final" = "#23d355ff", "preliminary" = "#A23B72")
p <- plot_ly()
for (i in 1:nrow(cruise_spans)) {
row <- cruise_spans[i, ]
p <- p |>
add_trace(
type = "scatter",
mode = "lines",
x = c(row$begin_jday, row$end_jday),
y = c(row$year, row$year),
line = list(
color = colors[row$stage_label],
width = 8
),
text = row$hover_text,
hoverinfo = "text",
showlegend = FALSE,
legendgroup = row$stage_label
)
}
p <- p |>
add_trace(
type = "scatter",
mode = "lines",
x = c(NA, NA),
y = c(NA, NA),
line = list(color = colors["final"], width = 8),
name = "Final",
showlegend = TRUE
) |>
add_trace(
type = "scatter",
mode = "lines",
x = c(NA, NA),
y = c(NA, NA),
line = list(color = colors["preliminary"], width = 8),
name = "Preliminary",
showlegend = TRUE
)
p <- p |>
layout(
title = "CalCOFI CTD Cruise Timeline",
xaxis = list(
title = "Day of Year",
range = c(1, 365),
dtick = 30,
tickangle = 0
),
yaxis = list(
title = "Year",
autorange = "reversed",
dtick = 1
),
hovermode = "closest",
plot_bgcolor = "#f8f9fa",
paper_bgcolor = "white",
legend = list(
x = 1.02,
y = 1,
xanchor = "left",
yanchor = "top"
)
)
p
close_duckdb(con_pq)
```
::: {.callout-caution collapse="true"}
## Session Info
```{r session_info}
devtools::session_info()
```
:::